Материалы по тегу: isc 2020
|
27.06.2020 [18:54], Алексей Степин
ISC 2020: NEC анонсировала новые векторные ускорители SX-AuroraВ японском сегменте рынка супервычислений продолжает доминировать свой, уникальный подход к построению систем класса HPC. Fujitsu сделала ставку на гомогенную архитектуру A64FX с памятью HBM2 и заняла первое место в Top500, но и другая японская компания, NEC, не отказалась от своего видения суперкомпьютерной архитектуры. На предыдущей конференции SC19 NEC пополнила свой арсенал новыми ускорителями SX-Aurora 10E, которые получили более быстрые сборки HBM2. О новых ускорителях «Type 20» речь заходила ещё до начала эпидемии COVID-19; к сожалению, она внесла свои коррективы и анонс новинок состоялся лишь сейчас, летом 2020 года.  Изначально процессор SX-Aurora, используемый во всей серии ускорителей «Type 10» имеет 8 векторных блоков, каждый из которых дополнен 2 Мбайт кеша и 6 сборок памяти HBM2 общим объёмом 24 или 48 Гбайт. Из-за сравнительно грубого 16-нм техпроцесса уровень тепловыделения достаточно высок и составляет примерно 225 Ватт. В отличие от Fujitsu A64FX, NEC SX-Aurora требует для своей работы управляющего хост-процессора, и обычно компания комбинирует его с Intel Xeon, но существуют варианты и с AMD EPYC второго поколения. 
ISC 2018: HPC-модуль с восемью векторными ускорителями NEC SX-Aurora Type 10 Это роднит SX-Aurora с более широко распространёнными ускорителями на базе графических процессоров, однако позиционирование у них всё-таки выглядит иначе. ГП-ускорители, по мнению NEC, гораздо сложнее в программировании, хотя и обеспечивают высокую производительность. 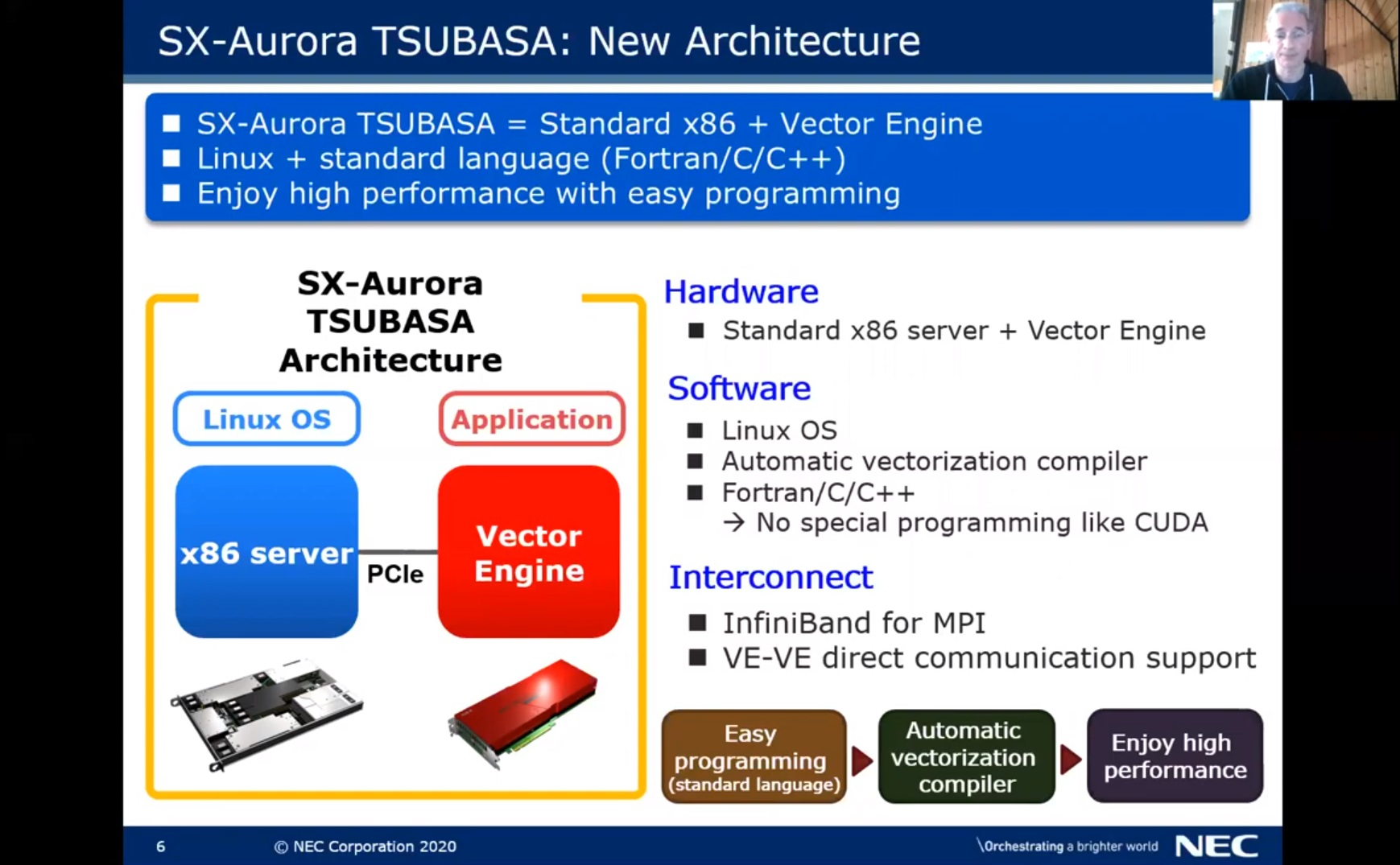 Свою же разработку компания относит к решениям с похожим уровнем производительности, но гораздо более простым в программировании. Упор также делается на высокую пропускную способность памяти, составляющую у новинок «Type 20» 1,5 Тбайт/с.  Новая версия NEC Vector Engine, VE20, структурно, скорее всего, не изменилась. Вместо восьми ядер новый процессор получил 10, и, как уже было сказано, новые сборки HBM2, в результате чего ПСП удалось поднять с 1,35 до 1,5 Тбайт/с, а вычислительную мощность с 2,45 до 3,07 Тфлопс. 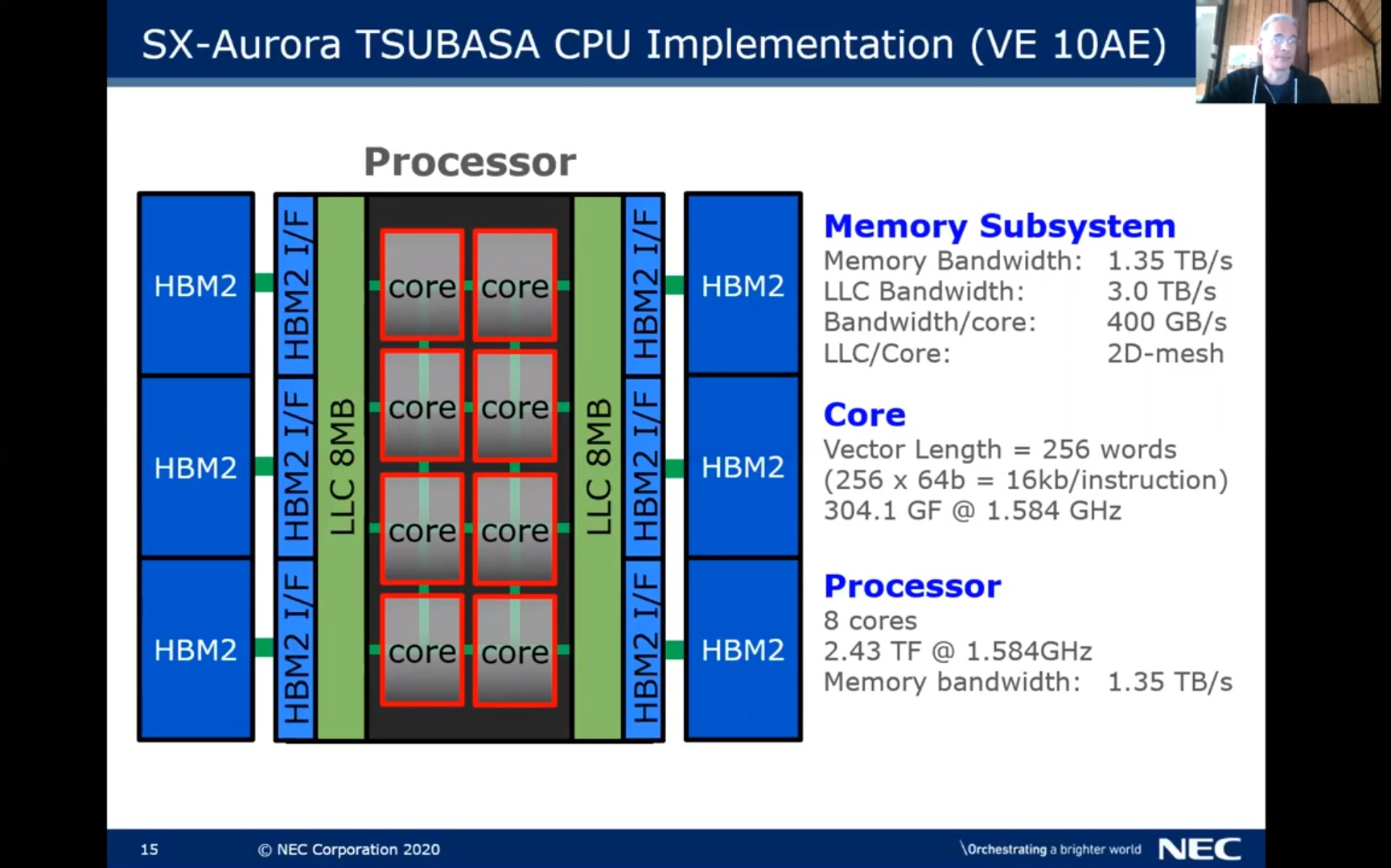 В серии пока представлено два новых ускорителя, Type 20A и 20B, последний аналогичен по конфигурации решениям Type 10 и использует усечённый вариант процессора с 8 ядрами. Говорится о неких архитектурных улучшениях, но деталей компания пока не раскрывает. Оба варианта процессора VE20 работают на частоте 1,6 ГГц, а прирост производительности в сравнении с VE10 достигается в основном за счёт повышения ПСП.  Похоже, VE20 лишь промежуточная ступень. В 2022 году планируется выпуск процессора VE30, который получит подсистему памяти с пропускной способностью свыше 2 Тбайт/с, в 2023 должен появиться его наследник VE40, но настоящий прорыв, судя по всему, откладывается до 2024 года, когда NEC планирует представить VE50, об архитектуре и возможностях которого пока ничего неизвестно. 
25.06.2020 [21:10], Алексей Степин
ISC 2020: Tachyum анонсировала 128-ядерные ИИ-процессоры Prodigy и будущий суперкомпьютер на их основеМашинное обучение в последние годы развивается и внедряется очень активно. Разработчики аппаратного обеспечения внедряют в свои новейшие решения поддержку оптимальных для ИИ-систем форматов вычислений, под этот круг задач создаются специализированные ускорители и сопроцессоры. 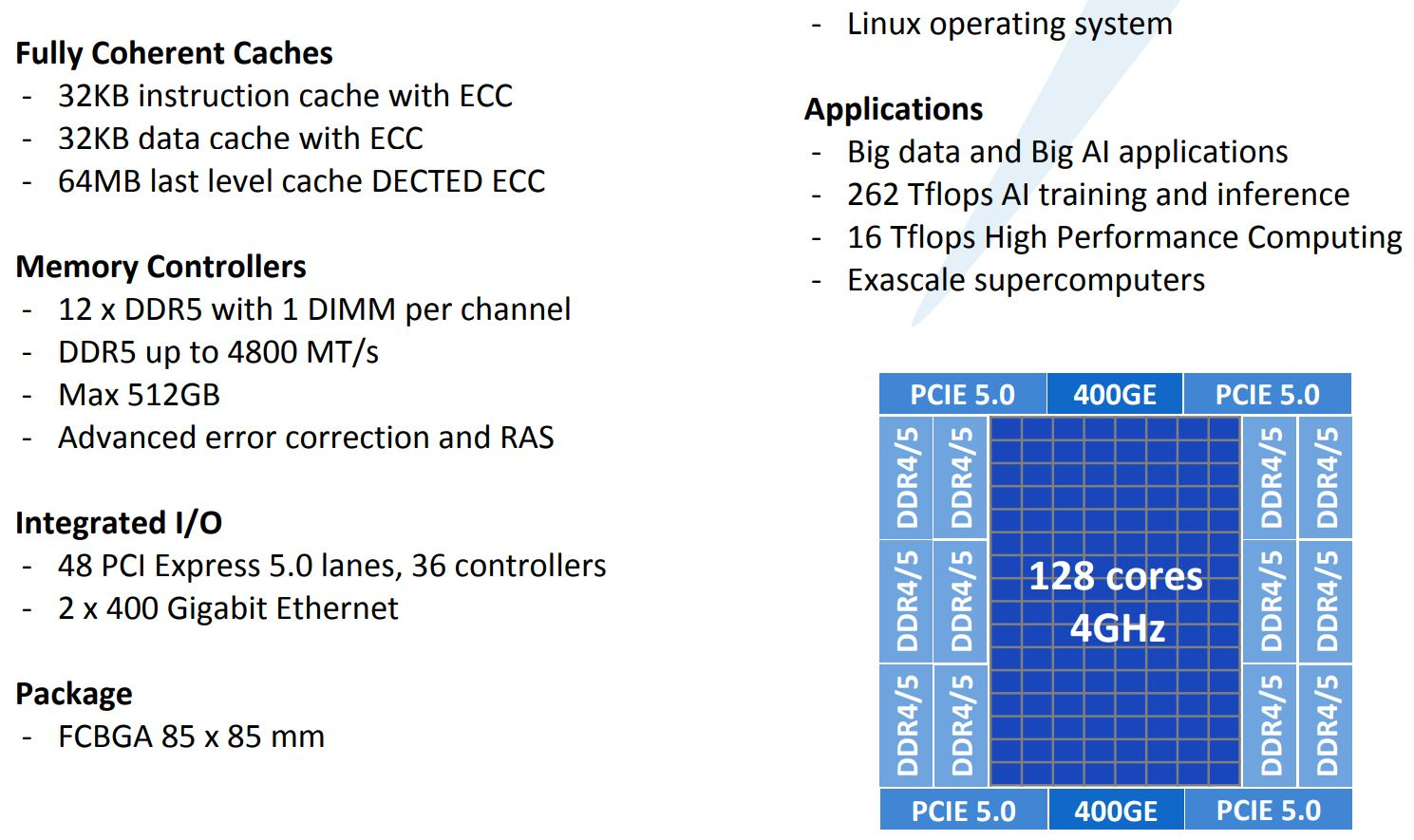 Словацкая компания Tachyum достаточно молода, но уже пообещала выпустить процессор, который «отправит Xeon на свалку истории». О том, что эти чипы станут основой для суперкомпьютеров нового поколения, мы уже рассказывали читателям, а на конференции ISC High Performance 2020 Tachyum анонсировала и сами процессоры Prodigy, и ИИ-комплекс на их основе.  Запуск готовых сценариев машинного интеллекта достаточно несложная задача, с ней справляются даже компактные специализированные чипы. Но обучение таких систем требует куда более внушительных ресурсов. Такие ресурсы Tachyum может предоставить: на базе разработанных ею процессоров Prodigy она создала дизайн суперкомпьютера с мощностью 125 Пфлопс на стойку и 4 экзафлопса на полный комплекс, состоящий из 32 стоек высотой 52U.  Основой для новой машины является сервер-модуль собственной разработки Tachyum, системная плата которого оснащается четырьмя чипами Prodigy. Каждый процессор, по словам разработчиков, развивает до 625 Тфлопс, что дает 2,5 Пфлопс на сервер. Компания обещает для новых систем трёхкратный выигрыш по параметру «цена/производительность» и четырёхкратный — по стоимости владения. При этом энергопотребление должно быть на порядок меньше, нежели у традиционных систем такого класса.  Архитектура Prodigy представляет существенный интерес: это не узкоспециализированный чип, вроде разработок NVIDIA, а универсальный процессор, сочетающий в себе черты ЦП, ГП и ускорителя ИИ-операций. Структура кристалла построена вокруг концепции «минимального перемещения данных». При разработке Tachyum компания принимала во внимание задержки, вносимые расстоянием между компонентами процессора, и минимизировала их. 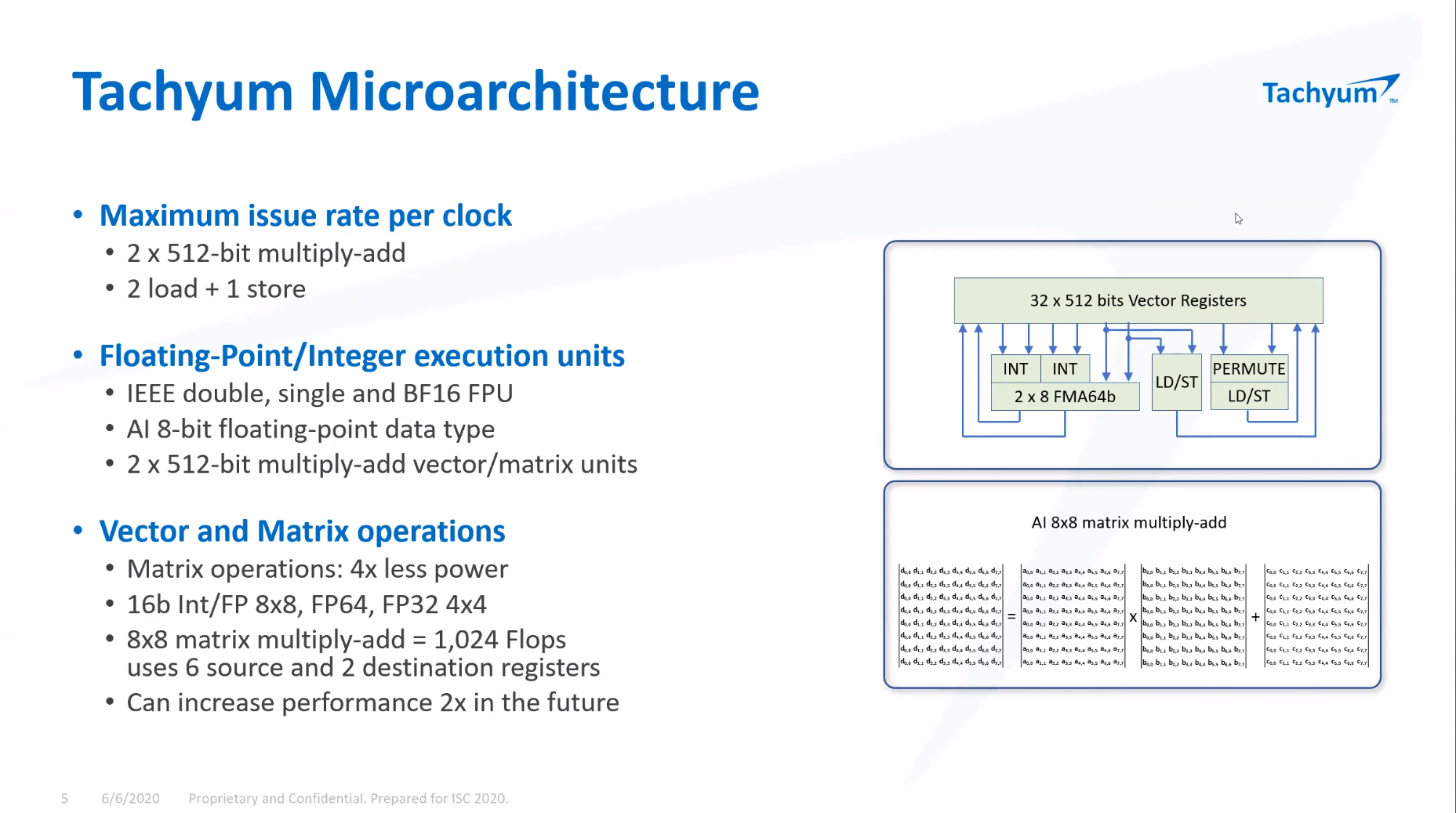 Процессор Prodigy может выполнять за такт две 512-битные операции типа multiply-add, 2 операции load и одну операцию store. Соответственно то, что каждое ядро Prodigy имеет восемь 64-бит векторных блока, похожих на те, что реализованы в расширениях Intel AVX-512 IFMA (Integer Fused Multiply Add, появилось в Cannon Lake). Блок вычислений с плавающей точкой поддерживает двойную, одинарную и половинную точность по стандартам IEEE. Для ИИ-задач имеется также поддержка 8-битных типов данных с плавающей запятой. 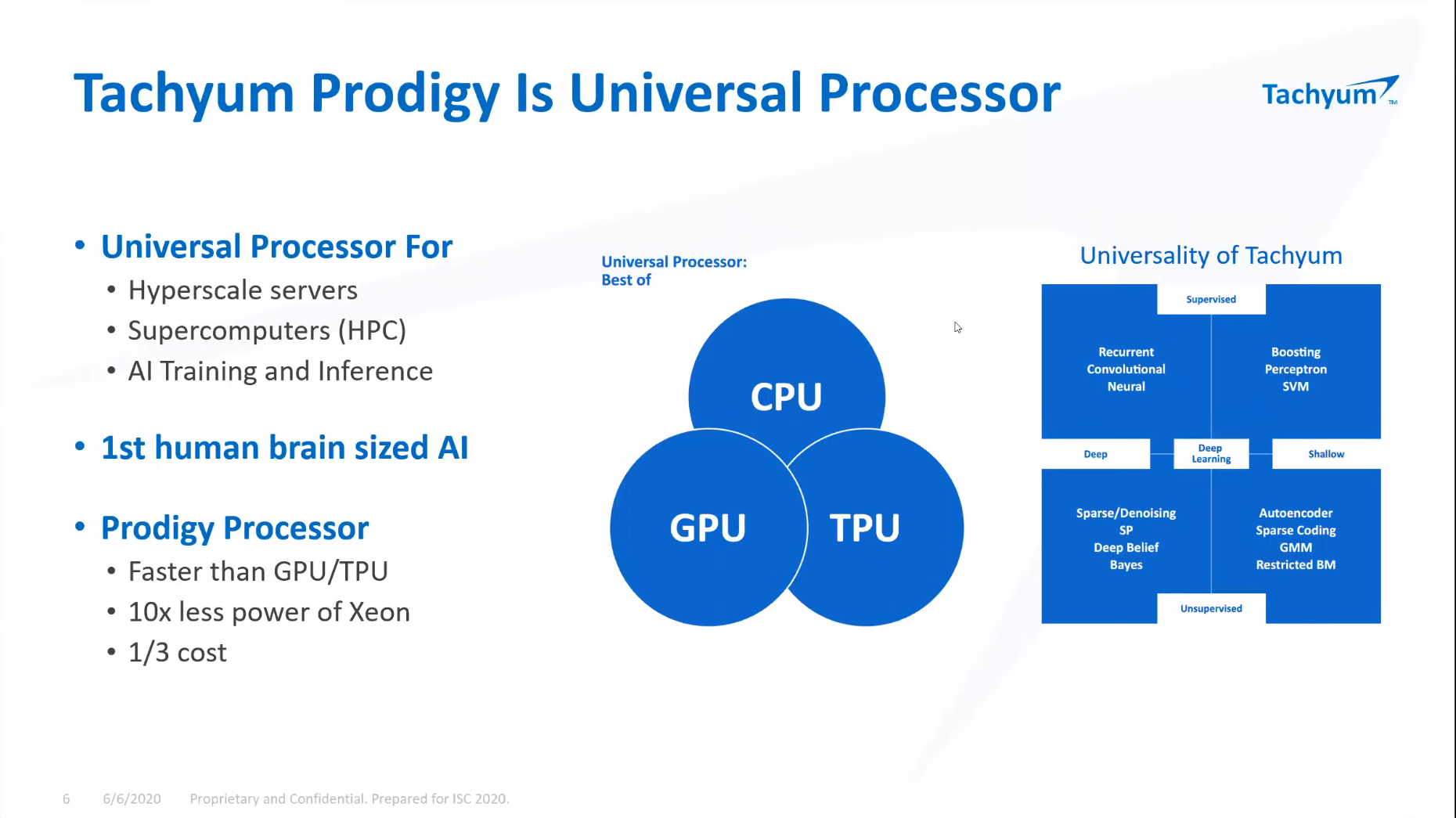 Векторные и матричные операции — сильная сторона Prodigy. На перемножении-сложении матриц размерностью 8 × 8 ядро развивает 1024 Флопс, используя 6 входных и 2 целевых регистра (в сумме есть тридцать два 512-бит регистра). Это не предел, разработчик говорит о возможности увеличения скорости выполнения этой операции вдвое. Tachyum обещает, что система на базе Prodigy станет первым в мире ИИ-кластером, способным запустить машинный интеллект, соответствующий человеческому мозгу.  С учётом заявлений о 10-кратной экономии электроэнергии и 1/3 стоимости от стоимости Xeon, это заявление звучит очень сильно. Но Prodigу — не бумажный продукт-однодневка. Tachyum разработала не только сам процессор, но и всю необходимую ему сопутствующую инфраструктуру, включая и компилятор, в котором реализованы оптимизации в рамках «минимального перемещения данных». Новинка разрабона с использованием 7-нм техпроцесса, максимальное количество ядер с вышеописанной архитектурой — 64. Помимо самих ядер, кристалл T864 содержит восьмиканальный контроллер DDR5, контроллер PCI Express 5.0 на 64 (а не 72, как ожидалось ранее) линии и два сетевых интерфейса 400GbE. При тактовой частоте 4 ГГц Prodigy развивает 8 Тфлопс на стандартных вычислениях FP32, 1 Пфлоп на задачах обучения ИИ и 4 Петаопа в инференс-задачах. Самая старшая версия, Tachyum Prodigy T16128, предлагает уже 128 ядер с частотой до 4 ГГц, 12 каналов памяти DDR5-4800 (но только 1DPC и до 512 Гбайт суммарно), 48 линий PCI Express 5.0 и два контроллера 400GbE. Производительность в HPC-задачах составит 16 Тфлопс, а в ИИ — 262 Тфлопс на обучении и тренировке.  Системные платы для Prodigy представлены, как минимум, в двух вариантах: полноразмерные четырёхпроцессорные для сегмента HPC и компактные однопроцессорные для модульных систем высокой плотности. Полноразмерный вариант имеет 64 слота DIMM и поддерживает модули DDR5 объёмом до 512 Гбайт, что даёт 32 Тбайт памяти на вычислительный узел. Сам узел полностью совместим со стандартами 19″ и Open Compute V3, он может иметь высоту 1U или 2U и поддерживает питание напряжением 48 Вольт. Плата имеет собственный BIOS UEFI, но для удалённого управления в ней реализован открытый стандарт OpenBMC.  Tachyum исповедует концепцию универсальности, но всё-таки узлы для HPC-систем на базе Prodigy могут быть нескольких типов — универсальные вычислительные, узлы хранения данных, а также узлы управления. В качестве «дисковой подсистемы» разработчики выбрали SSD-накопители в формате NF1, подобные представленному ещё в 2018 году накопителю Samsung. Таких накопителей в корпусе системы может быть от одного до 36; поскольку NF1 существенно крупнее M.2, поддерживаются модели объёмом до 32 Тбайт, что даёт почти 1,2 Пбайт на узел. Стойка с модулями Prodigy будет вмещать до 50 модулей высотой 1U или до 25 высотой 2U. Согласно идее о минимизации дистанций при перемещении данных, сетевой коммутатор на 128 или 256 портов 100GbE устанавливается в середине стойки.  Такая конфигурация работает в системе с числом стоек до 16, более масштабные комплексы предполагается соединять между собой посредством коммутатора высотой 2U c 64 портами QSFP-DD, причём поддержка скорости 800 Гбит/с появится уже в 2022 году. 512 стоек могут объединяться посредством высокопроизводительного коммутатора CLOS, он имеет высоту 21U и также получит поддержку 800 Гбит/с в дальнейшем. Компания активно поддерживает открытые стандарты: применён загрузчик Core-Boot, разработаны драйверы устройств для Linux, компиляторы и отладчики GCC, поддерживаются открытые приложения, такие, как LAMP, Hadoop, Sparc, различные базы данных. В первом квартале 2021 года ожидается поддержка Java, Python, TensorFlow, PyTorch, LLVM и даже операционной системы FreeBSD.  Любопытно, что существующее программное обеспечение на системах Tachyum Prodigy может быть запущено сразу в виде бинарных файлов x86, ARMv8 или RISC-V — разумеется, с пенальти. Производительность ожидается в пределах 60 ‒ 75% от «родной архитектуры», для достижения 100% эффективности всё же потребуется рекомпиляция. Но в рамках контрактной поддержки компания обещает помощь в этом деле для своих партнёров. Разумеется, пока речи о полномасштабном производстве новых систем не идёт. Эталонные платформы Tachyum обещает во второй половине следующего года. Как обычно, сначала инженерные образцы получают OEM/ODM-партнёры компании и системные интеграторы, а массовые поставки должны начаться в 4 квартале 2021 года. Однако ПЛИС-эмуляторы Prodigy появятся уже в октябре этого года, инструментарий разработки ПО — и вовсе в августе.  Планы у Tachyum поистине наполеоновские, но её разработки интересны и содержат целый ряд любопытных идей. В чём-то новые процессоры можно сравнить с Fujitsu A64FX, которые также позволяют создавать гомогенные и универсальные вычислительные комплексы. Насколько удачной окажется новая платформа, говорить пока рано.
23.06.2020 [19:23], Алексей Степин
128 ядер ARM: Ampere Computing анонсировала процессоры Altra MaxНа первый взгляд, позиции архитектуры x86 в мире высокопроизводительных вычислений выглядят незыблемыми: примерно 94% всех систем класса HPC используют в качестве основы процессоры Intel и ещё 2,2% занимает AMD. Однако запуск кластера Fugaku доказал, что ARM — соперник весьма и весьма опасный. Система на базе процессоров Fujitsu A64FX использует именно архитектуру ARM. И наступление ARM продолжается и на других фронтах: к примеру, AWS предлагает инстансы на собственных ARM-процессорах Graviton2. Не дремлет Ampere Computing, анонсировавшая сегодня новые процессоры Altra и Altra Max.  Разработкой мощных многоядерных процессоров с архитектурой ARM компания занимается довольно давно: в конце прошлого года она уже рассказывала о втором поколении своих продуктов, чипах QuickSilver. В их основу лег дизайн ядра ARM Neoverse N1 (ARM v8.2+), количество самих ядер достигло 80, появилась поддержка интерфейса PCI Express 4.0, чего, например, до сих пор нет в процессорах Intel Xeon Scalable. Серверные процессоры с архитектурой ARM доказали своё превосходство в энергоэффективности перед x86, что сделало их отличным выбором для облачных сервисов — в таких ЦОД плотность упаковки вычислительных мощностей максимальна и такие параметры, как удельная производительность, энергопотребление и тепловыделение играют крайне важную роль. Новые процессоры Ampere под кодовым именем Altra нацелены именно на этот сектор рынка. 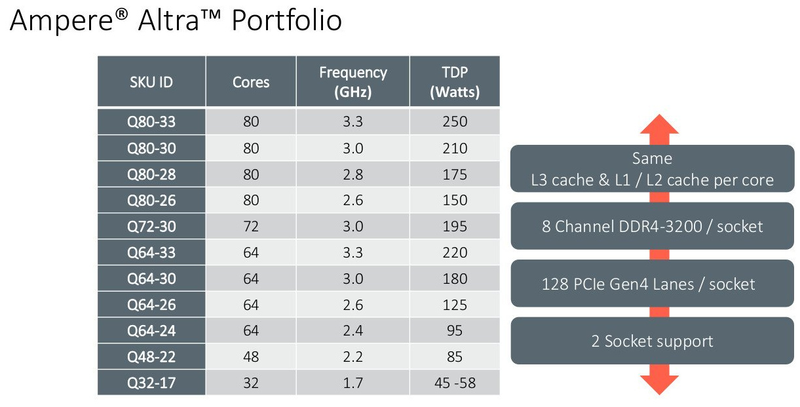 В основе Altra также лежит ядро Neoverse N1 — оно же применено и в проекте Amazon Graviton2 — но Ampere Computing намеревается охватить с помощью Altra остальных крупных провайдеров облачных услуг, которые также заинтересованы в высокоплотных энергоэффективных ЦП. При этом утверждается, что Altra превосходит Graviton2; по крайней мере, на бумаге это выглядит убедительно. Всего в серии Altra анонсировано 12 процессоров, с количеством ядер от 32 до 80, частотами от 1,7 до 3,3 ГГц и теплопакетами от 45 до 250 Ватт. Все они располагают восьмиканальным контроллером памяти DDR4-3200 (до 4 Тбайт на процессор) и предоставляют в распоряжение системы 128 линий PCI Express 4.0, чем пока могут похвастаться разве что AMD Rome. Применена очень простая система наименований: например, «Q72-30» означает, что перед нами 72 ядерный процессор поколения QuickSilver с частотой 3 ГГц.  Altra следует большинству современных тенденций в процессоростроении: процессоры располагают солидным массивом кешей (1 Мбайт на ядро, 32 Мбайт L3), ядра имеют два 128-битных блока инструкций SIMD, а также поддерживают популярные в задачах машинного интеллекта и инференс-комплексах форматы вычислений INT8 и FP16. Что касается удельной энергоэффективности, то ядро AMD Rome потребляет около 3 Ватт при полной нагрузке на частоте 3 ГГц, а для Altra Q80-30 этот показатель равен 2,6 Ватта; турборежима у Altra, впрочем, нет и максимальные частоты справедливы для всех ядер.  В настоящий момент компания поставляет образцы платформ Altra двух типов: однопроцессорную Mt. Snow и двухпроцессорную Mt. Jade. В число партнёров компании входят такие производители, как GIGABYTE и Wiwynn, заявлен также ряд контрактов с производителями более низких эшелонов. В основе Mt. Jade, вероятнее всего, лежит системная плата GIGABYTE MP32-AR0, о ней мы уже рассказывали нашим читателям.  Цены новых решений пока не разглашаются, однако, заинтересованные в процессорах Ampere провайдеры уже в течение двух месяцев тестируют новые платформы; в их число входят такие компании, как Packet и CloudFlare, причём Packet уже предоставляет своим клиентам «ранний доступ» к услугам, запускаемым на новых платформах Ampere. Более массовых поставок следует ожидать в августе и сентябре текущего года. 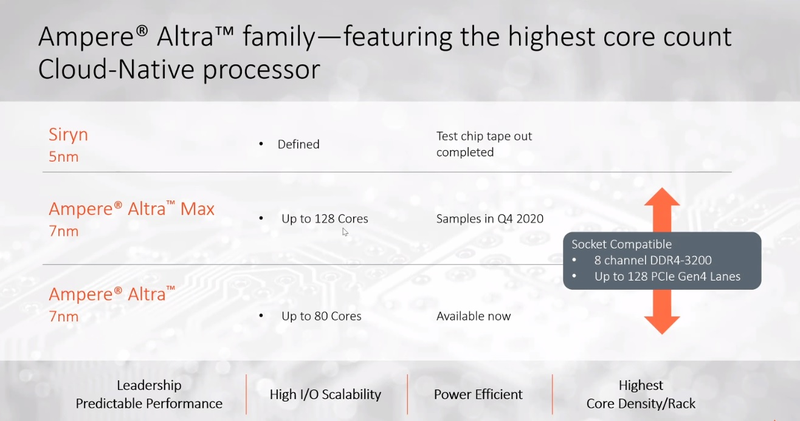 80 ядер — весьма солидное количество, даже в арсенале AMD таких процессоров ещё нет, семейство EPYC всё ещё ограничено 64 ядрами, но с SMT. Однако на достигнутом Ampere не останавливается и позднее в этом году планирует представить миру настоящего монстра — 128-ядерный процессор Altra Max, на базе всё той же архитектуры QuickSilver/Neoverse. Этот чип имеет кодовое имя Mystique, он будет базироваться на новом дизайне кристалла, однако отличия здесь количественные, качественно это всё та же Altra, но с большим количеством ядер, оптимизированная с учётом возможностей сохранённой неизменной подсистемой памяти. Сохранится даже совместимость по процессорному разъёму. Образцы Altra Max если и существуют, то только в лаборатории Ampere Computing, а публичного появления сэмплов этих процессоров следует ожидать не ранее 4 квартала с началом производства в 2021 году. 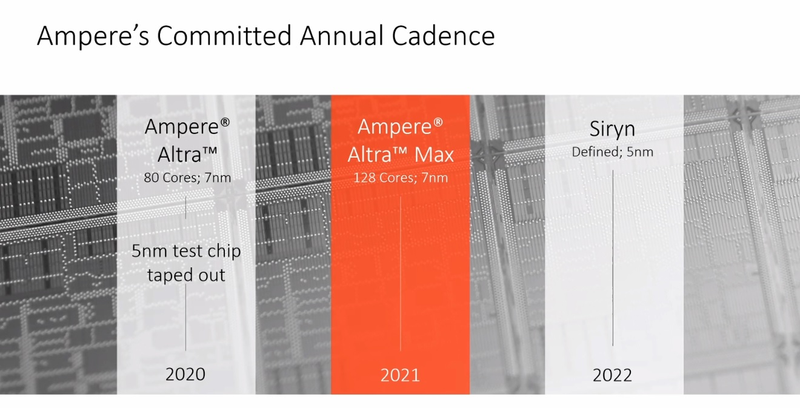 Таким образом, можно утверждать, что технологическая ступень 7 нм компанией освоена. Она штурмует новую высоту — образцы процессоров Siryn, построенные с использованием 5-нм техпроцесса TSMC должны появиться ближе к концу следующего года. Некоторые блоки Siryn уже существуют в кремнии. Эти процессоры получат и новую платформу, а, возможно, и поддержку таких технологий, как PCI Express 5.0 и DDR5.
22.06.2020 [18:20], Игорь Осколков
ARM-суперкомпьютер Fugaku поднялся на вершину рейтингов TOP500, HPCG и HPL-AIКонечно же, речь идёт о японском суперкомпьютере Fugaku на базе ARM-процессоров A64FX, который досрочно начал трудиться весной этого года. Эта машина стала самым мощным суперкомпьютером в мире сразу в трёх рейтингах: классическом TOP500, современном HPCG и специализированном HPL-AI.  Суперкомпьютер состоит из 158976 узлов, которые имеют почти 7,3 млн процессорных ядер, обеспечивающих реальную производительность на уровне 415,5 Пфлопс, то есть Fugaku почти в два с половиной раза быстрее лидера предыдущего рейтинга, машины Summit. Правда, оказалось, что с точки зрения энергоэффективности новая ARM-система мало чем отличается от связки обычного процессора и GPU, которой пользуется большая часть суперкомпьютеров. Так что на первое место в Green500 она не попала. 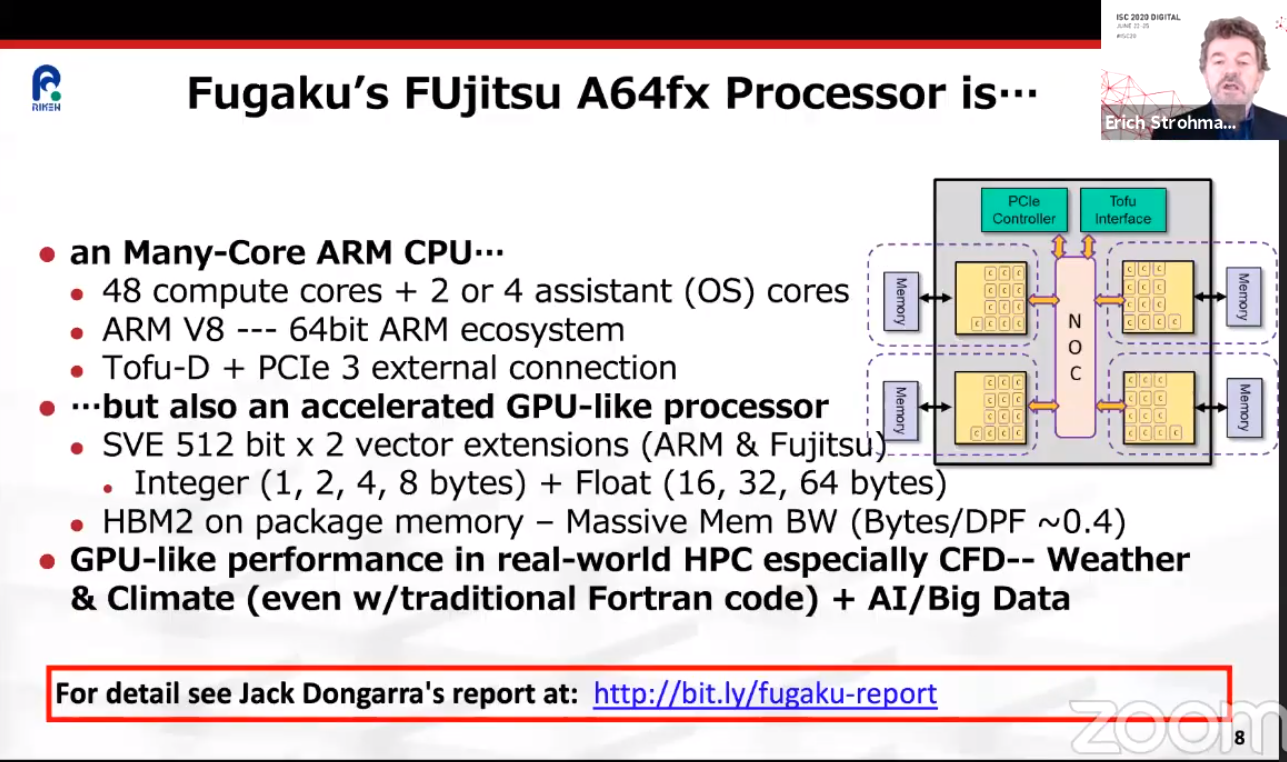  Однако на стороне Fugaku универсальность — понижение точности вычислений вдвое приводит к удвоение производительности. Так что машина имеет впечатляющую теоретическую пиковую скорость вычислений 4,3 Эопс на INT8 и не менее впечатляющие 537 Пфлопс на FP64. Это помогло занять её первое место в бенчмарке HPL-AI, которые использует вычисления разной точности. А общая архитектура процессора, включающего набортную память HBM2, и системы, использующей интерконнект Tofu, способствовали лидерству в бенчмарке HPCG, который оценивает эффективность машины в целом. 
22.06.2020 [12:39], Илья Коваль
NVIDIA представила PCIe-версию ускорителя A100Как и предполагалось, NVIDIA вслед за SXM4-версией ускорителя A100 представила и модификацию с интерфейсом PCIe 4.0 x16. Обе модели используют идентичный набор чипов с одинаковыми характеристикам, однако, помимо отличия в способе подключения, у них есть ещё два существенных отличия. 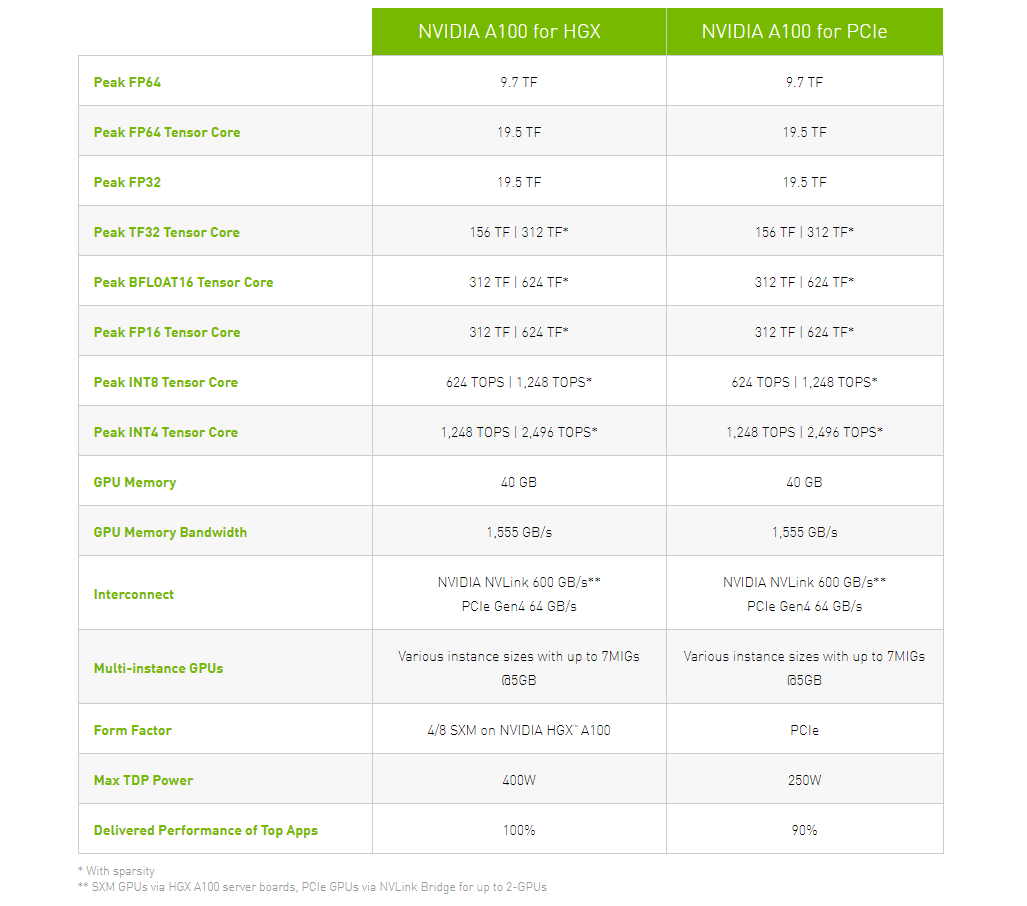 Первое — сниженный с 400 Вт до 250 Вт показатель TDP. Это прямо влияет на величину устоявшейся скорости работы. Сама NVIDIA указывает, что производительность PCIe-версии составит 90% от SXM4-модификации. На практике разброс может быть и больше. Естественным ограничением в данном случае является сам форм-фактор ускорителя — только классическая двухслотовая FLFH-карта с пассивным охлаждением совместима с современными серверами.  Второе отличие касается поддержки быстрого интерфейса NVLink. В случае PCIe-карты посредством внешнего мостика можно объединить не более двух ускорителей, тогда как для SXM-версии есть возможность масштабирования до 8 ускорителей в рамках одной системы. С одной стороны, NVLink в данном случае практически на порядок быстрее PCIe 4.0. С другой — PCIe-версия наверняка будет заметно дешевле и в этом отношении универсальнее. 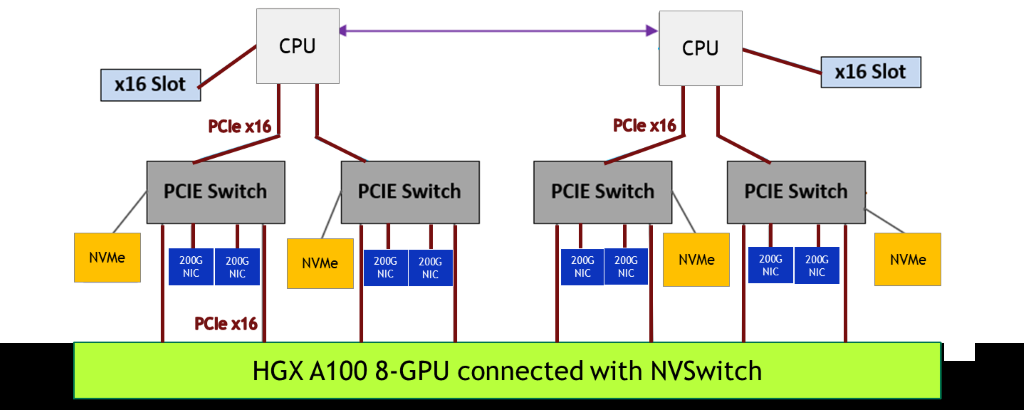 Производители серверов уже объявили о поддержке новых ускорителей в своих системах. Как правило, это уже имеющиеся платформы с возможностью установки 4 или 8 (реже 10) карт. Любопытно, что фактически единственным разумным вариантом для плат PCIe 4.0, как и в случае HGX/DGX A100, является использование платформ на базе AMD EPYC 7002. |
|

