Материалы по тегу: core
|
27.08.2020 [19:13], Алексей Степин
TSMC и Graphcore создают ИИ-платформу на базе технологии 3 нмНесмотря на все проблемы в полупроводниковой индустрии, технологии продолжают развиваться. Технологические нормы 7 нм уже давно не являются чудом, вовсю осваиваются и более тонкие нормы, например, 5 нм. А ведущий контрактный производитель, TSMC, штурмует следующую вершину — 3-нм техпроцесс. Одним из первых продуктов на базе этой технологии станет ИИ-платформа Graphcore с четырьмя IPU нового поколения. Британская компания Graphcore разрабатывает специфические ускорители уже не первый год. В прошлом году она представила процессор IPU (Intelligence Processing Unit), интересный тем, что состоит не из ядер, а из так называемых тайлов, каждый из которых содержит вычислительное ядро и некоторое количество интегрированной памяти. В совокупности 1216 таких тайлов дают 300 Мбайт сверхбыстрой памяти с ПСП до 45 Тбайт/с, а между собой процессоры IPU общаются посредством IPU-Link на скорости 320 Гбайт/с. 
Colossально: ИИ-сервер Graphcore с четырьмя IPU на борту Компания позаботилась о программном сопровождении своего детища, снабдив его стеком Poplar, в котором предусмотрена интеграция с TensorFlow и Open Neural Network Exchange. Разработкой Graphcore заинтересовалась Microsoft, применившая IPU в сервисах Azure, причём совместное тестирование показало самые положительные результаты. Следующее поколение IPU, Colossus MK2, представленное летом этого года, оказалось сложнее NVIDIA A100 и получило уже 900 Мбайт сверхбыстрой памяти.  Машинное обучение, в основе которого лежит тренировка и использование нейронных сетей, само по себе требует процессоров с весьма высокой степенью параллелизма, а она, в свою очередь, автоматически означает огромное количество транзисторов — 59,4 млрд в случае Colossus MK2. Поэтому освоение новых, более тонких и экономичных техпроцессов является для этого класса микрочипов ключевой задачей, и Graphcore это понимает, заявляя о своём сотрудничестве с TSMC. 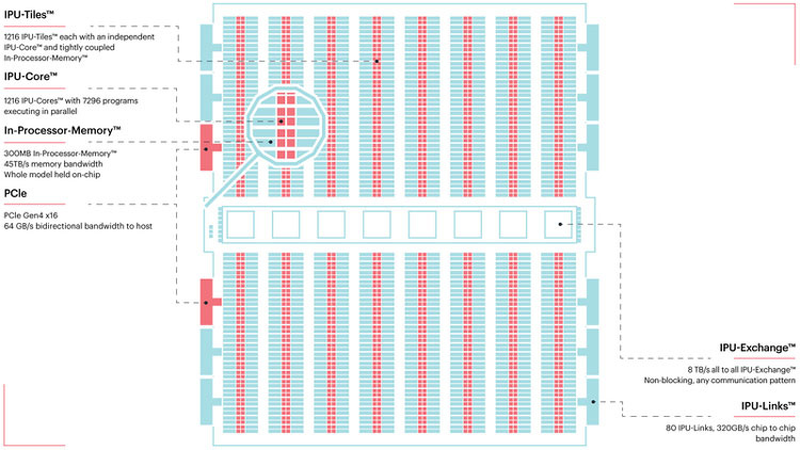
Тайловая архитектура Graphcore Colossus MK2 В настоящее время TSMC готовит к началу «рискового» производства новый техпроцесс с нормами 3 нм, причём скорость внедрения такова, что первые продукты на его основе должны увидеть свет уже в 2021 году, а массовое производство будет развёрнуто во второй половине 2022 года. И одним из первых продуктов на базе 3-нм технологических норм станет новый вариант IPU за авторством Graphcore, известный сейчас как N3. Судя по всему, использовать 5 нм британский разработчик не собирается. 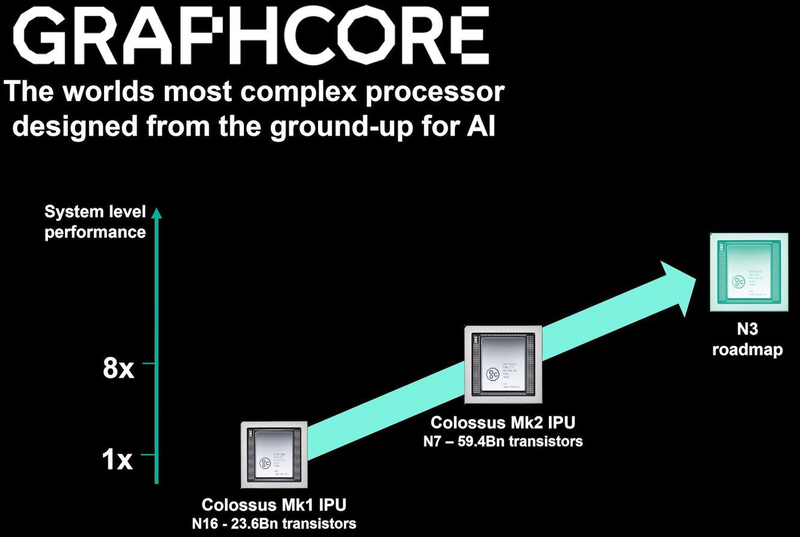
В планах компании явно указано использование 3-нм техпроцесса В настоящее время чипы Colossus MK2 производятся с использованием техпроцесса 7 нм (TSMC N7). Они включают в себя 1472 тайла и способны одновременно выполнять 8832 потока. В режиме тренировки нейросетей с использованием вычислений FP16 это даёт 250 Тфлопс, но существует удобное решение мощностью 1 Пфлопс — это специальный 1U-сервер Graphcore, в нём четыре IPU дополнены 450 Гбайт внешней памяти. Доступны также платы расширения PCI Express c чипами IPU на борту. Дела у Graphcore идут неплохо, её технология оказалась востребованной и среди инвесторов числятся Microsoft, BMW, DeepMind и ряд других компаний, разрабатывающих и внедряющих комплексы машинного обучения. Разработка 3-нм чипа ещё более упрочнит позиции этого разработчика. Более тонкие техпроцессы существенно увеличивают стоимость разработки, но финансовые резервы у Graphcore пока есть; при этом не и исключён вариант более тесного сотрудничества, при котором часть стоимости разработки возьмёт на себя TSMC.
25.11.2019 [16:29], Андрей Созинов
SC19: TMGcore OTTO — автономный роботизированный микро-ЦОД с иммерсионной СЖОКомпания TMGcore представила в рамках прошедшей конференции SC19 свою весьма необычную систему OTTO. Новинка является модульной платформой для создания автономных ЦОД, которая характеризуется высокой плотностью размещения аппаратного обеспечения, использует двухфазную иммерсионную систему жидкостного охлаждения, а также обладает роботизированной системой замены серверов. 
Версия OTTO на 600 кВт Первое, что отмечает производитель в системе OTTO — это высокая плотность размещения аппаратного обеспечения. Система состоит из довольно компактных серверов, которые размещены в резервуаре с охлаждающей жидкость. Собственно, использование двухфазной иммерсионной системы жидкостного охлаждения и позволяет размещать «железо» с максимальной плотностью. 
Версия OTTO на 60 кВт Всего OTTO будет доступна в трёх вариантах, рассчитанных на 60, 120 и 600 кВт. Системы состоят из одного или нескольких резервуаров для размещения серверов. Один такой резервуар имеет 12 слотов высотой 1U, в десяти из которых располагаются сервера, а ещё в двух — блоки питания. Также каждый резервуар снабжён шиной питания с рабочей мощностью 60 кВт. Отметим, что площадь, занимаемая самой большой 600-кВт системой OTTO составляет всего 14,9 м2. В состав системы OTTO могут входить как эталонные серверы HydroBlades от самой TMGcore, так и решения от других производителей, прошедшие сертификацию «OTTO Ready». В последнем случае серверы должны использовать корпуса и компоновку, которые позволяют использовать их в иммерсионной системе охлаждения. Например, таким сервером является Dell EMC PowerEdge C4140.  В рамках конференции SC19 был продемонстрирован и фирменный сервер OTTOblade G1611. При высоте всего 1U он включает два процессора Intel Xeon Scalable, до 16 графических процессоров NVIDIA V100, до 1,5 Тбайт оперативной памяти и два 10- или 100-гигабитных интерфейса Ethernet либо одиночный InfiniBand 100G. Такой сервер обладает производительность в 2000 Тфлопс при вычислениях на тензорных ядрах.  Мощность описанной абзацем выше машины составляет 6 кВт, то есть в системе OTTO может работать от 10 до 100 таких машин. И охладить столь компактную и мощную систему способна только двухфазная погружная система жидкостного охлаждения. Он состоит из резервуара, заполненного охлаждающей жидкостью от 3M и Solvay, и теплообменника для конденсации испарившейся жидкости.  Для замены неисправных серверов система OTTO оснащена роботизированной рукой, которая способна производить замены в полностью автоматическом режиме. В корпусе OTTO имеется специальный отсек с резервными серверами, а также отсек для неисправных систем. Такой подход позволяет производить замену серверов без остановки всей системы, и позволяет избежать контакта человека с СЖО во время работы.  Изначально TMGcore специализировалась на системах для майнинга с иммерсионным охлаждением, а после перенесла свои разработки на обычные системы. Поэтому, в частности, описанный выше OTTOblade G1611 с натяжкой можно отнести к HPC-решениям, так как у него довольно слабый интерконнект, не слишком хорошо подходящий для решения классических задач. Впрочем, если рассматривать OTTO как именно автономный или пограничный (edge) микро-ЦОД, то решение имеет право на жизнь. |
|

