Материалы по тегу: оптимизация
|
17.11.2025 [16:09], Руслан Авдеев
Программный «ускоритель» Huawei обещает практически удвоить производительность дефицитных ИИ-чиповКитайский техногигант Huawei Technologies инфраструктурное ПО для повышения эффективности использования ИИ-ускорителей, сообщает гонконгская SCMP со ссылкой на государственные СМИ КНР. По имеющимся данным, технология позволит поднять эффективность использования ИИ-чипов, включая GPU и NPU, до 70 % по сравнению с нынешними 30–40 %. Это будет ещё одним крупным достижением в области «компенсации отставания в аппаратном обеспечении за счет совершенствования программного». Новая технология, премьера которой должна состояться на одной из посвящённых ИИ-тематике конференций, позволит «унифицированно управлять» не только ускорителями самой Huawei, но и NVIDIA, а также моделями прочих разработчиков. В самой Huawei от комментариев пока воздержались. Это особенно актуально в свете недоступности актуальных ускорителей NVIDIA, из-за чего китайские компании скупают чипы прошлых поколений. Важность оптимизации использования имеющихся ресурсов наглядна показала «революция DeepSeek». 
Источник изображения: Yiran Ding/unsplash.com Если информация подтвердится, технология может значительно улучшить продажи ИИ-чипов семейства Huawei Ascend в Китае (возможно, и за его пределами). Это может снизить зависимость КНР от чипов NVIDIA и других американских разработчиков. Утверждается, что новая технология Huawei будет аналогична продукту, разрабатывавшемуся израильским стартапом Run:ai и купленному NVIDIA в 2024 году за $700 млн. Его ПО позволяет организовать оркестрацию крупномасштабных ИИ-нагрузок между массивами ИИ-ускорителей. При этом и сама NVIDIA постоянно оптимизирует собственное ПО, повышая производительность исполнения рабочих нагрузок ИИ. Новость может стать хорошим дополнением к сентябрьскому анонсу. Тогда компания поделилась планами выпуска ИИ-ускорителей Ascend следующего поколения. Готовящиеся изделия призваны составить конкуренцию передовым чипов NVIDIA и подготовке мощных ИИ-систем SuperPOD, объединяющих 8192 и 15 488 ускорителей Ascend. На основе таких платформ будут формироваться суперкластеры, насчитывающие до 500 тыс. и более экземпляров Ascend.
20.10.2025 [01:23], Владимир Мироненко
Ускорителей хватит на всех — Alibaba Aegaeon оптимизировал обработку ИИ-нагрузок, снизив использование дефицитных NVIDIA H20 на 82 %Alibaba Cloud представила Aegaeon, систему пулинга вычислений, позволяющую сократить количество ускорителей NVIDIA, необходимых для обслуживания ИИ-моделей, на 82 %, пишет ресурс SCMP. По словам разработчиков, благодаря Aegaeon количество ускорителей NVIDIA H20, необходимых для обслуживания десятков моделей с 72 млрд параметров, удалось сократить с 1192 до 213 единиц. «Aegaeon — это первое решение на рынке, которое выявило чрезмерные затраты, связанные с обслуживанием параллельных рабочих нагрузок LLM», — сообщили исследователи из Пекинского университета и Alibaba Cloud. Провайдеры облачных сервисов, такие как Alibaba Cloud и ByteDance Volcano Engine, предоставляют пользователям одновременно тысячи ИИ-моделей — множество вызовов API обрабатывается одновременно. Однако на практике для инференса чаще всего используются лишь несколько моделей, таких как Qwen и DeepSeek, а большинство других моделей применяются лишь эпизодически. Это приводит к неэффективному использованию вычислительных ресурсов: исследователи обнаружили, что 17,7 % ускорителей выделяется на обслуживание лишь 1,35 % запросов в Alibaba Cloud. Aegaeon выполняет «автоматическое масштабирование» на уровне токенов, обеспечивая переключение ускорителей между обслуживанием различных моделей в процессе генерации. В рамках системы один ускоритель поддерживает обработку до семи моделей по сравнению с двумя-тремя моделями в альтернативных системах. При этом задержка, связанная с переключением между моделями, снижена на 97 %, заявили исследователи. Alibaba Cloud сообщила, что решение уже используется на её торговой площадке моделей Bailian. 
Источник изображения: Alibaba Глава NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что из-за экспортных ограничений доля компании на рынке передовых чипов в Китае сократилась с 95 % до нуля. Этому также способствовала стратегия Пекина, направленная на самообеспечение местного рынка. В связи с этим планы NVIDIA возобновить отгрузки ИИ-ускорителей H20, на которые ранее были установлены ограничения правительством США, встретили в Китае довольно прохладно. Более того, в Китае вынесли запрет местным компаниям на покупку разработанного специально для местного рынка ускорителя NVIDIA RTX Pro 6000D, поскольку пришли к выводу, что китайские ИИ-чипы не уступают продукции NVIDIA, разрешённой к экспорту в Китай.
03.02.2025 [09:20], Руслан Авдеев
The Register: Успех DeepSeek показал важность обдуманных инвестиций в ИИ, но потребность в развитии инфраструктуры никуда не денетсяШок, вызванный недавним триумфом китайского ИИ-стартапа DeepSeek, представившего дешёвые и эффективные ИИ-модели, заставил многих усомниться в результативности масштабных вложений в инфраструктуру на базе дорогих ИИ-ускорителей, сообщает The Register. Тем не менее эксперты уверены, что отказываться от инвестиций было бы нецелесообразно. На прошлой неделе акции ряда крупнейших американских ИИ-брендов после дебюта весьма эффективной модели DeepSeek R1, использующей, со слов создателей, сравнительно мало ускорителей NVIDIA, буквально обрушились в цене. Из-за этого многие эксперты усомнились в том, что траты миллиардов на аппаратную инфраструктуру для ИИ себя оправдывают, если Китай способен добиться хороших результатов, используя не самое мощное оборудование. Например, NVIDIA «в моменте» потеряла $600 млрд рыночной стоимости. Настоящая истерия наложилась на растущее беспокойство в связи с тем, что всё больше денег тратится на инфраструктуру и её поддержку, а особенной отдачи пока не видно. Впрочем, паника может быть неуместной, поскольку обрушение акций прекратилось, а DeepSeek обвиняется в использовании ИИ-моделей Anthropic и OpenAI. Как отмечает The Register, нет и реальных подтверждений того, что производительность моделей DeepSeek находится на уровне лучших из актуальных моделей, а также того, что на обучение китайского ИИ ушло всего $6 млн. По оценкам SemiAnalysis, доступная DeepSeek инфраструктура гораздо больше, чем утверждает компания, и стоит более чем $1,5 млрд. 
Источник изображения: Etienne Girardet/unsplash.com По словам экспертов Omdia, опасения относительно «сокрушительных» инноваций DeepSeek сильно преувеличены. В компании подтверждают, что китайский стартап использовал некоторые «гениальные инновации», но они приведут лишь к массовому использованию аналогичных решений и строительству новой ИИ-инфраструктуры. В Omdia прогнозируют, что в ближайшие годы рынок ИИ-инфраструктуры, скорее всего, значительно вырастет. В компании полагают, что до 2028 года поставки серверов для инференса будут расти на 17 % ежегодно. В TrendForce придерживаются несколько иного мнения и предполагают, что в будущем организации всё же станут более строго оценивать инвестиции в инфраструктуру ИИ и станут применять более эффективные модели для того, чтобы снизить зависимость от доступности ускорителей. Также не исключается, что чаще будут использоваться кастомные ASIC вместо сторонних ИИ-ускорителей и спрос на «классические» модели может претерпеть с 2025 года заметные изменения. Если раньше индустрия полагалась в первую очередь на масштабирование моделей, увеличение объёмов данных и повышение производительности оборудования, то теперь стратегия меняется. DeepSeek прибегла к «дистилляции» моделей, повышению скорости инференса и снижения зависимости от оборудования. Не так давно генеральный директор IBM Арвинд Кришна (Arvind Krishna) объявил, что деятельность DeepSeek подтвердила правильность подхода к ИИ его собственной компании, считающей, что модели могут быть меньше, как и время их обучения. При использовании подобных подходов затраты на инференс могут снизиться в 30 раз, что очень хорошо для корпоративных клиентов. Ещё в 2023 году компания начала развивать серию «экономичных» базовых моделей Granite. Вероятно, по этому пути пойдут и другие. 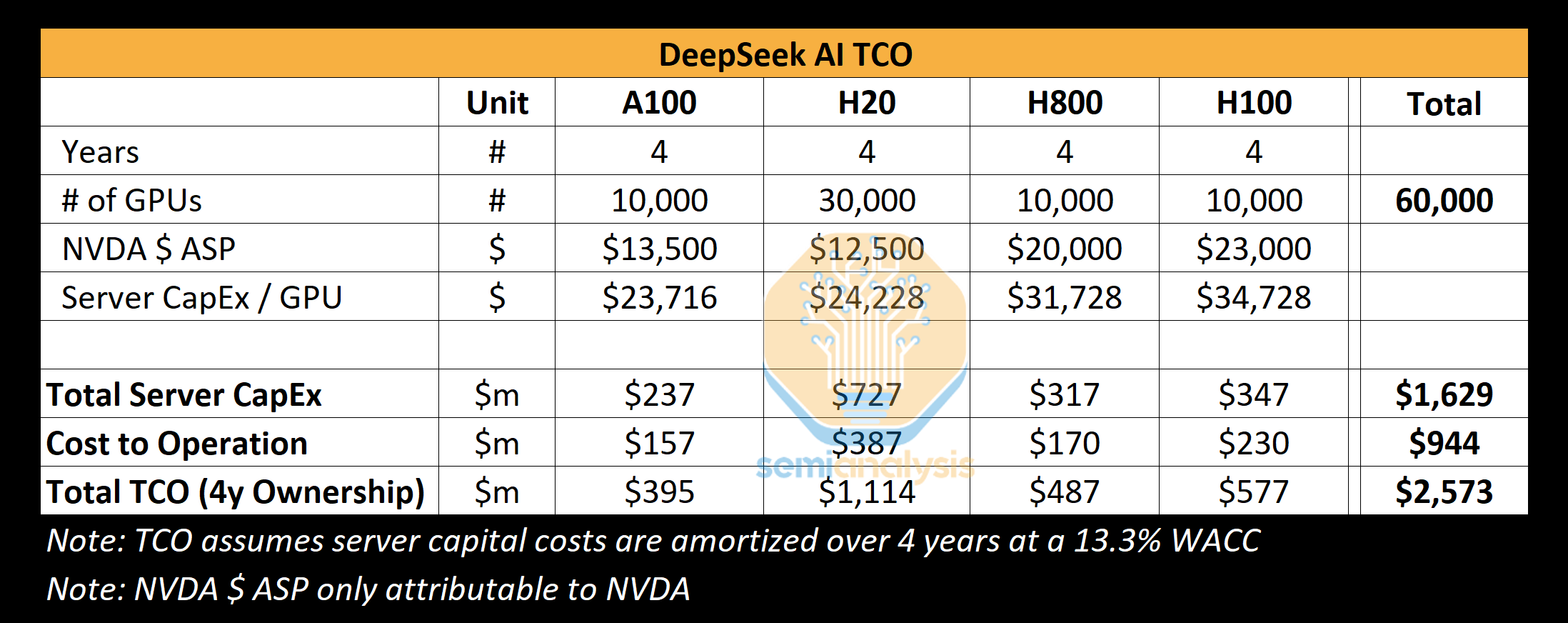
Источник изображения: SemiAnalysis Gartner также сообщает, что именно эффективное масштабирование ИИ будет целесообразнее простого наращивания вычислительных ресурсов. Впрочем, китайский ИИ не устанавливает новый стандарт эффективности моделей, поскольку те соответствуют показателям уже существующих, но не превосходят их. Кроме того, нет доказательств, что добавление дополнительных вычислительных ресурсов и данных не имеет значения. The Register прогнозирует, что продукты и технологии DeepSeek не вызовут резкого падения спроса на ИИ-инфраструктуру, поэтому инвесторам NVIDIA и строителям ЦОД, вероятно, можно не бояться того, что «пузырь» ИИ лопнет, как этого ожидают некоторые эксперты. Во всяком случае одни из крупнейших инвесторов в сектор ЦОД — Blackstone и Brookfield — заявили, что следят за успехами DeepSeek, но отказываться от инвестиций не собираются. Тем не менее, успех китайского стартапа напоминает о том, что «всегда можно сделать ещё лучше» и экстенсивное вливание денег и вычислительных ресурсов не всегда лучший вариант. |
|

