Вместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег.

Изображения: NVIDIA
Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.


В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов.
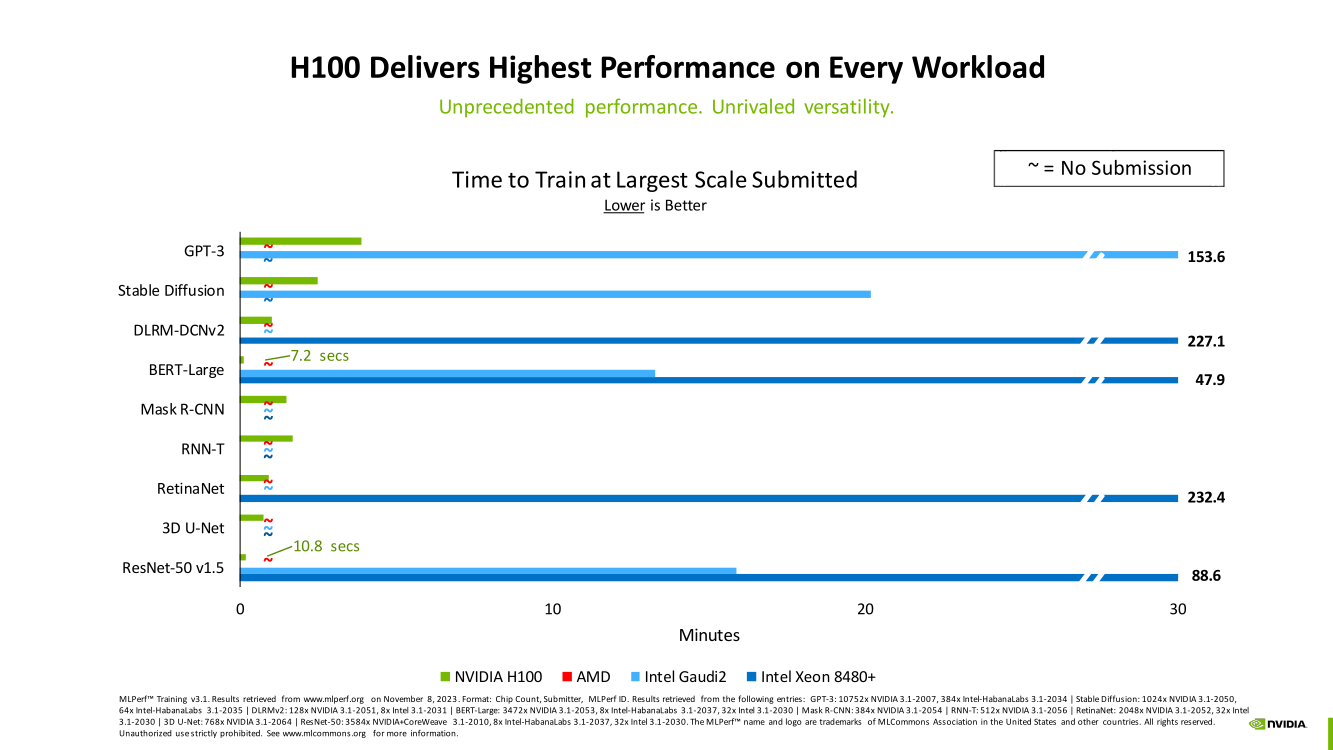
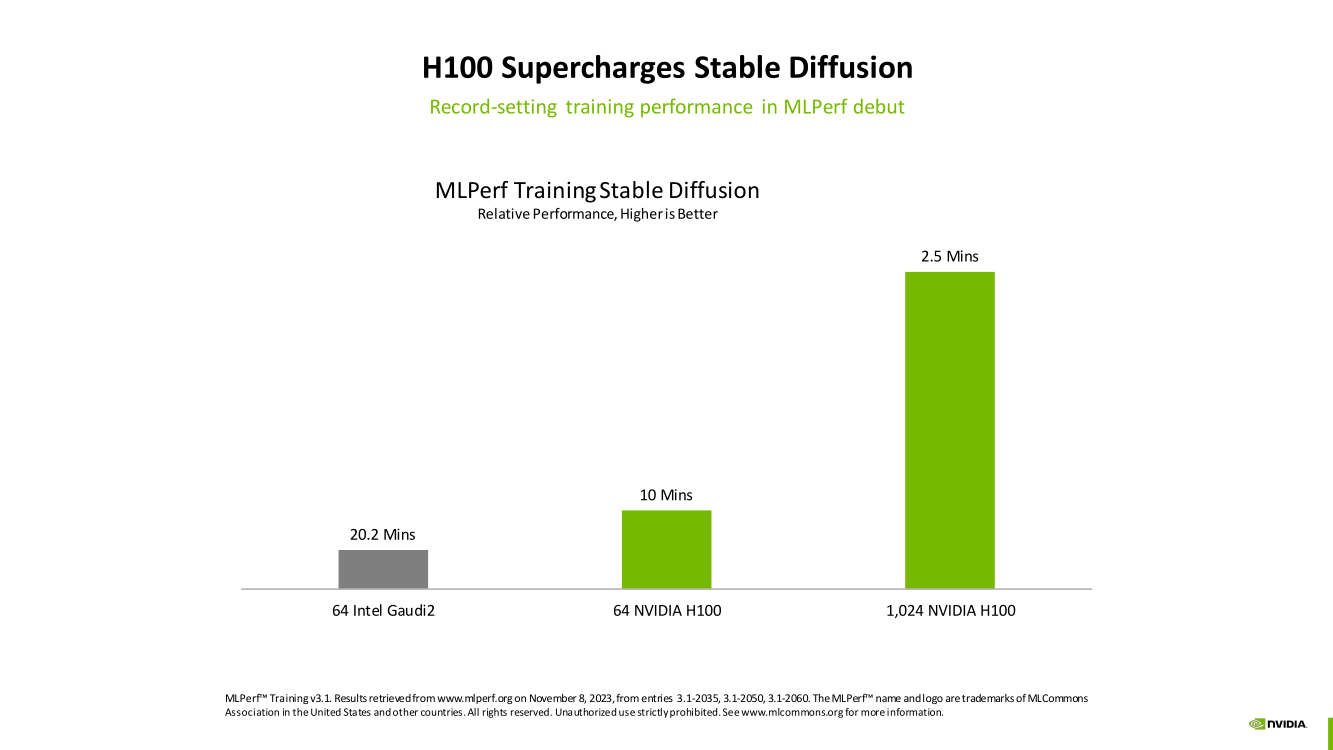
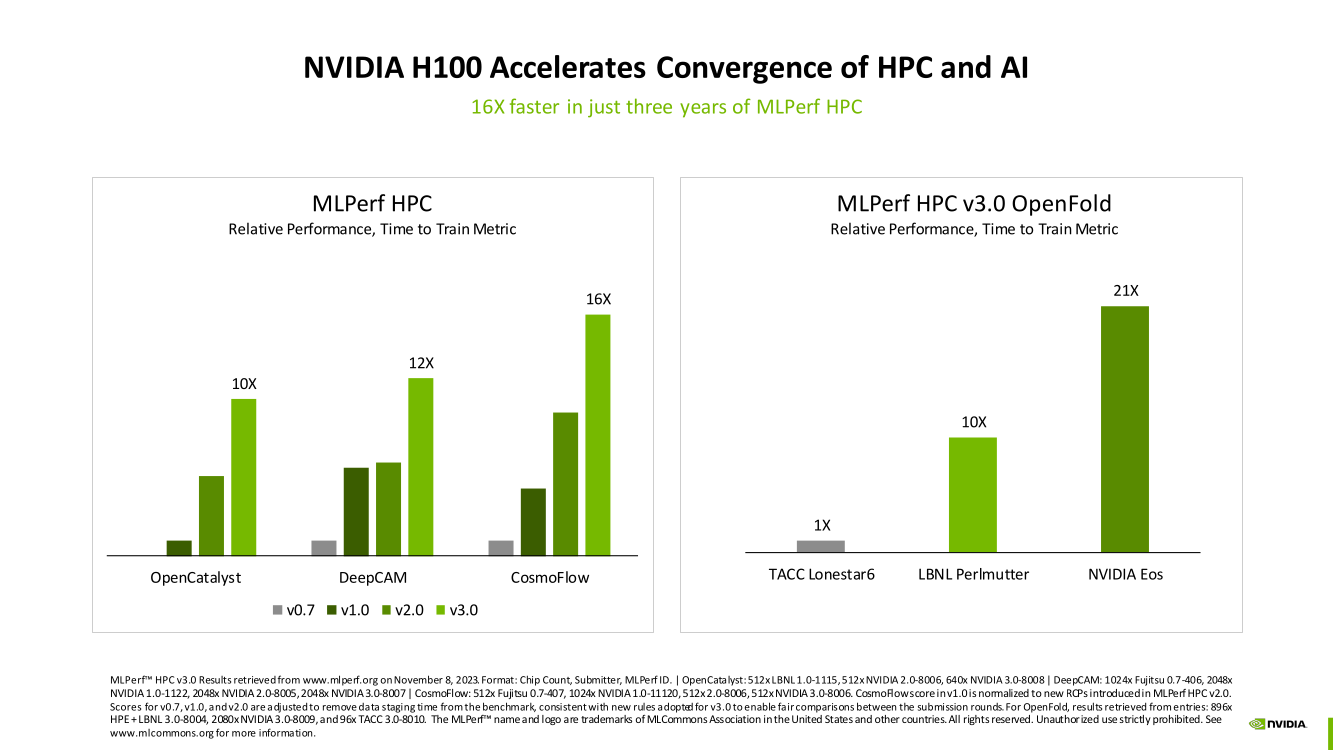
NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд.
Источник:

