Материалы по тегу: tpu
|
26.12.2024 [18:17], Руслан Авдеев
Omdia: быстрый рост спроса на TPU Google ставит под вопрос доминирование NVIDIA на рынке ИИ-ускорителейНовейшее исследование Omdia показывает, что быстрый рост спроса на кастомные ИИ-ускорители Google (TPU) формирует особый тренд. Не исключено, что он станет достаточно сильным для того, чтобы начать процесс, способный прекратить доминирование NVIDIA на рынке ускорителей, сообщает Omdia. Результаты III квартала компании Broadcom, чьё подразделение Semiconductor Solutions выполняет аутсорс-заказы Google, Meta✴ и некоторых других IT-гигантов, дают по-новому взглянуть на рынок ускорителей. В частности, они позволяют оценить покупательские тенденции и косвенно получить информацию, которая обычно скрывается. Например, как много кастомных процессоров покупает Google. Глава Broadcom Хок Тан (Hock Tan) неоднократно пересматривал планы выручки от ИИ-полупроводников, в этом году компания намерена заработать $12 млрд. Исходя из этого ожидается, что на TPU Google придётся от $6 млрд (близко к текущим оценкам Omdia) до $9 млрд, в зависимости от распределения выручки между вычислительными и сетевыми решениями. В сумму целиком входит и выручка от чипов Meta✴ MTIA. В следующем году у Broadcom, вероятно, появится и загадочный третий заказчик. Им может стать Apple, которая сейчас активно использует для обучения моделей именно TPU. 
Источник изобраджения: Google По словам экспертов Omdia, даже с учётом того, что соотношение выручки от вычислительных и сетевых устройств точно не определено, поставки TPU даже «по нижней границе» в $6 млрд свидетельствуют о росте достаточно быстром, чтобы впервые отвоевать часть доли рынка у NVIDIA. По оценкам TechInsights, в 2023 году поставки TPU достигли 2 млн шт., а ускорителей NVIDIA для ЦОД — 3,8 млн шт. Стоит отметить, что выручка бизнеса Google Cloud Platform продолжает расти как часть выручки Google, при этом растёт и рентабельность подразделения. Это может свидетельствовать о том, что инстансы на основе TPU выступают драйверами роста Google Cloud и являются высокоприбыльными продуктами. В середине ноября Google и NVIDIA показали первые результаты TPU v6 и B200 в ИИ-бенчмарке MLPerf Training, где ускорители продемонстрировали неоднозначные результаты в разных сравнениях.
14.11.2024 [23:07], Владимир Мироненко
Google и NVIDIA показали первые результаты TPU v6 и B200 в ИИ-бенчмарке MLPerf TrainingУскорители Blackwell компании NVIDIA опередили в бенчмарках MLPerf Training 4.1 чипы H100 более чем в 2,2 раза, сообщил The Register. По словам NVIDIA, более высокая пропускная способность памяти в Blackwell также сыграла свою роль. Тесты были проведены с использование собственного суперкомпьютера NVIDIA Nyx на базе DGX B200. Новые ускорители имеют примерно в 2,27 раза более высокую пиковую производительность в вычисления FP8, FP16, BF16 и TF32, чем системы H100 последнего поколения. B200 показал в 2,2 раза более высокую производительность при тюнинге модели Llama 2 70B и в два раза большую производительность при предварительном обучении (Pre-training) модели GPT-3 175B. Для рекомендательных систем и генерации изображений прирост составил 64 % и 62 % соответственно. Компания также отметила преимущества используемой в B200 памяти HBM3e, благодаря которой бенчмарк GPT-3 успешно отработал всего на 64 ускорителях Blackwell без ущерба для производительности каждого GPU, тогда как для достижения такого же результата понадобилось бы 256 ускорителей H100. Впрочем, про Hopper компания тоже не забывает — в новом раунде компания смогла масштабировать тест GPT-3 175B до 11 616 ускорителей H100. 
Источник изображений: NVIDIA Компания отметила, что платформа NVIDIA Blackwell обеспечивает значительный скачок производительности по сравнению с платформой Hopper, особенно при работе с LLM. В то же время чипы поколения Hopper по-прежнему остаются актуальными благодаря непрерывным оптимизациям ПО, порой кратно повышающим производительность в некоторых задач. Интрига в том, что в этот раз NVIDIA решила не показывать результаты GB200, хотя такие системы есть и у неё, и у партнёров. 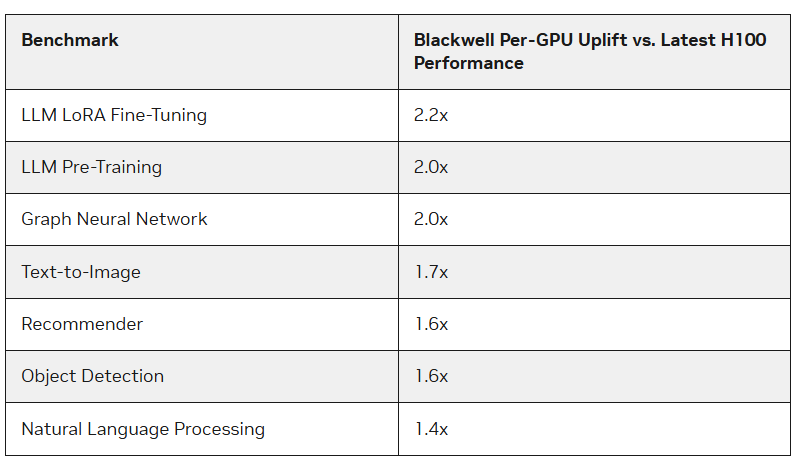 В свою очередь, Google представила первые результаты тестирования 6-го поколения TPU под названием Trillium, о доступности которого было объявлено в прошлом месяце, и второй раунд результатов ускорителей 5-го поколения TPU v5p. Ранее Google тестировала только TPU v5e. По сравнению с последним вариантом, Trillium обеспечивает прирост производительности в 3,8 раза в задаче обучения GPT-3, отмечает IEEE Spectrum.  Если же сравнивать результаты с показателями NVIDIA, то всё выглядит не так оптимистично. Система из 6144 TPU v5p достигла контрольной точки обучения GPT-3 за 11,77 мин, отстав от системы с 11 616 H100, которая выполнила задачу примерно за 3,44 мин. При одинаковом же количестве ускорителей решения Google почти вдвое отстают от решений NVIDIA, а разница между v5p и v6e составляет менее 10 %. 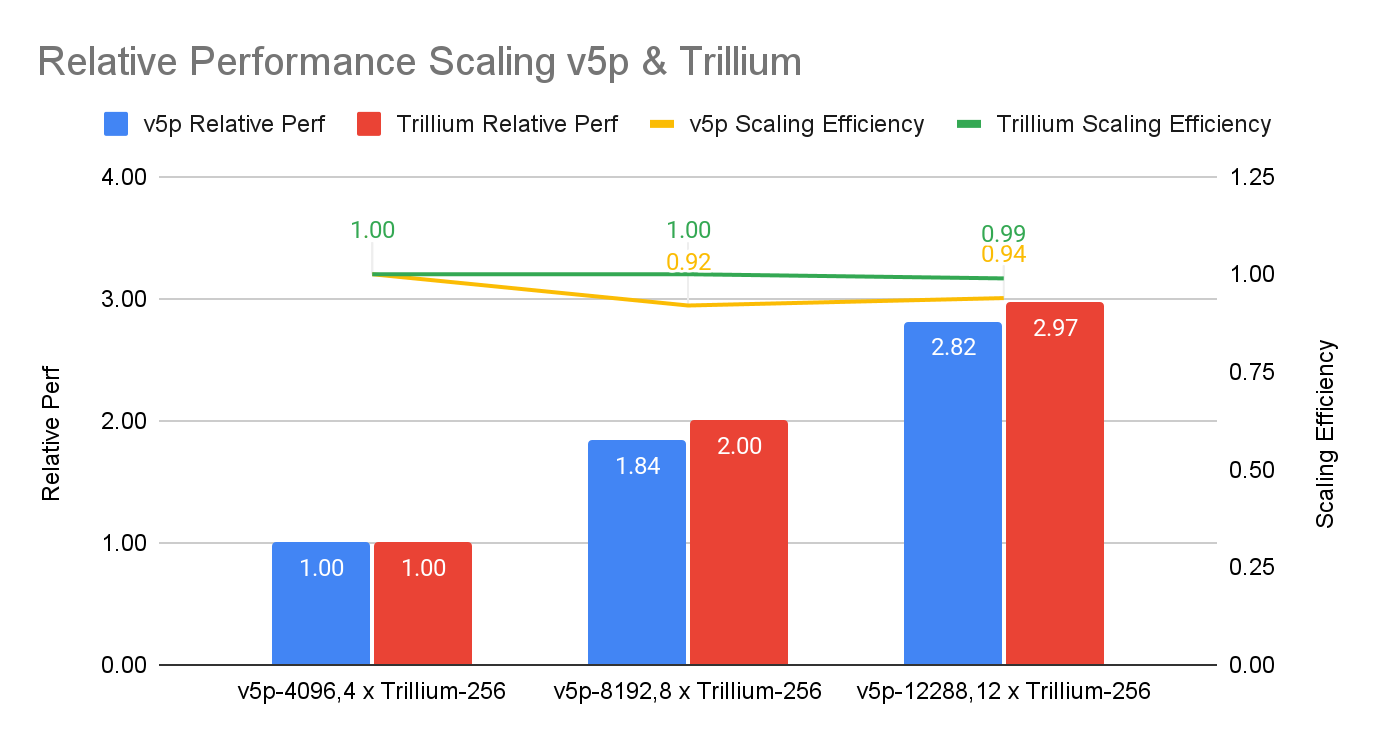
Источник изображения: Google В тесте Stable Diffusion система из 1024 TPU v5p заняла второе место, завершив работу за 2,44 мин, тогда как система того же размера на основе NVIDIA H100 справилась с задачей за 1,37 мин. В остальных тестах на кластерах меньшего масштаба разрыв остаётся примерно полуторакратным. Впрочем, Google упирает на масштабируемость и лучшее соотношение цены и производительности в сравнении как с решениями конкурентов, так и с собственными ускорителями прошлых поколений. Также в новом раунде MLPerf появился единственный результат измерения энергопотребления во время проведения бенчмарка. Система из восьми серверов Dell XE9680, каждый из которых включал восемь ускорителей NVIDIA H100 и два процессора Intel Xeon Platinum 8480+ (Sapphire Rapids), в задаче тюнинга Llama2 70B потребила 16,38 мДж энергии, потратив на работу 5,05 мин. — средняя мощность составила 54,07 кВт.
03.11.2024 [13:15], Сергей Карасёв
Google объявила о доступности ИИ-ускорителей TPU v6 TrilliumКомпания Google сообщила о том, что её новейшие ИИ-ускорители TPU v6 с кодовым именем Trillium доступны клиентам для ознакомления в составе облачной платформы GCP. Утверждается, что на сегодняшний день новинка является самым эффективным решением Google по соотношению цена/производительность. Официальная презентация Trillium состоялась в мае нынешнего года. Изделие оснащено 32 Гбайт памяти HBM с пропускной способностью 1,6 Тбайт/с, а межчиповый интерконнект ICI обеспечивает возможность передачи данных со скоростью до 3,58 Тбит/с (по четыре порта на чип). Задействованы блоки SparseCore третьего поколения, предназначенные для ускорения работы с ИИ-моделями, которые используются в системах ранжирования и рекомендаций. 
Источник изображений: Google Google выделяет ряд существенных преимуществ Trillium (TPU v6e) перед ускорителями TPU v5e:
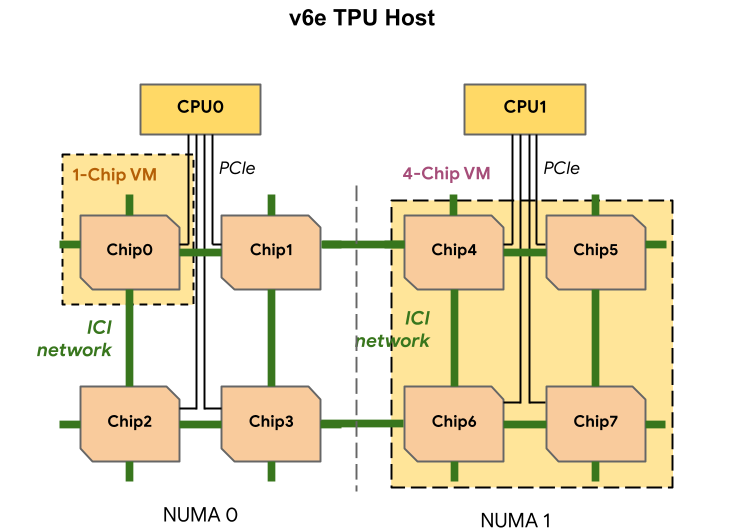 Один узел включает восемь ускорителей TPU v6e (в двух NUMA-доменах), два неназванных процессора (суммарно 180 vCPU), 1,44 Тбайт RAM и четыре 200G-адаптера (по два на CPU) для связи с внешним миром. Отмечается, что посредством ICI напрямую могут быть объединены до 256 изделий Trillium, а агрегированная скорость сетевого подключение такого кластера (Pod) составляет 25,6 Тбит/с. Десятки тысяч ускорителей могут быть связаны в масштабный ИИ-кластер благодаря платформе Google Jupiter с оптической коммутацией, совокупная пропускная способность которой достигает 13 Пбит/с. Trillium доступны в составе интегрированной ИИ-платформы AI Hypercomputer. 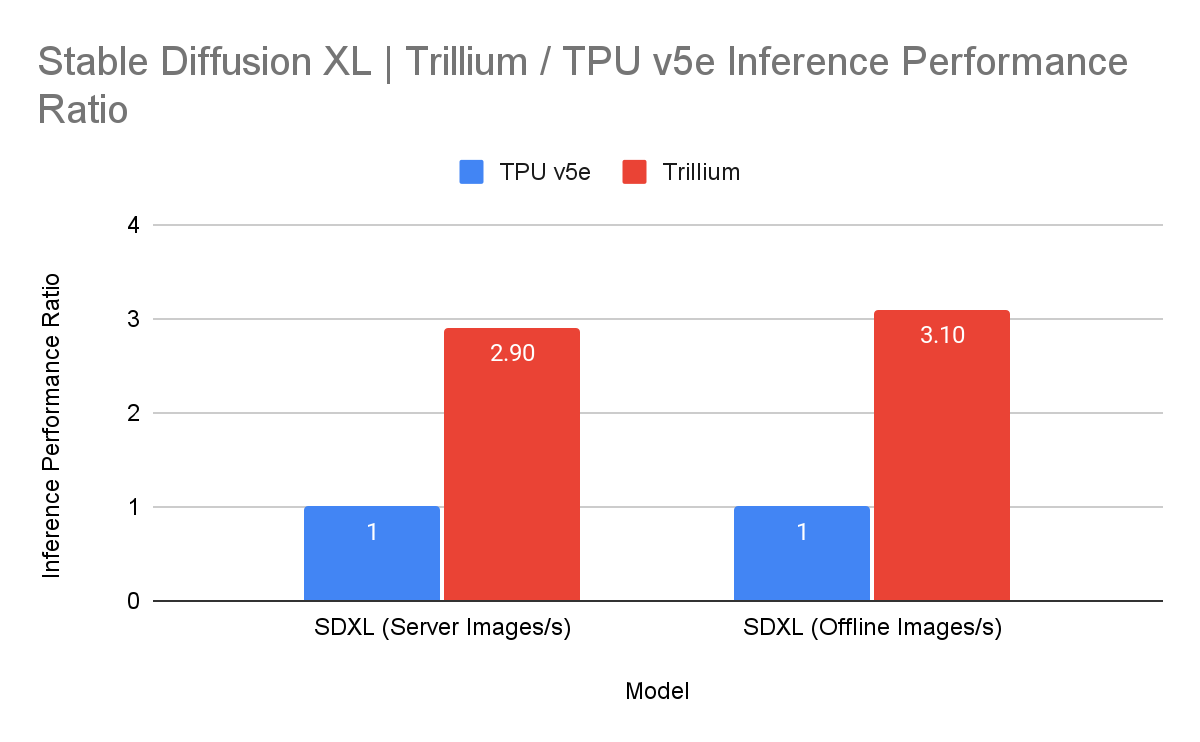 Заявляется, что благодаря ПО Multislice Trillium обеспечивается практически линейное масштабирование производительности для рабочих нагрузок, связанных с обучением ИИ. Производительность кластеров на базе Trillium может достигать 91 Эфлопс на ИИ-операциях: это в четыре раза больше по сравнению с самыми крупными развёртываниями систем на основе TPU v5p. BF16-производительность одного чипа TPU v6e составляет 918 Тфлопс, а INT8 — 1836 Топс. 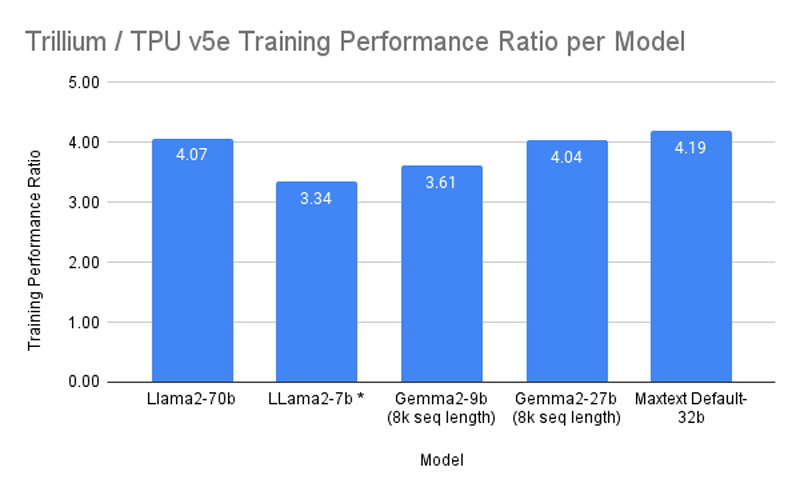 В бенчмарках Trillium по сравнению с TPU v5e показал более чем четырёхкратное увеличение производительности при обучении моделей Gemma 2-27b, MaxText Default-32b и Llama2-70B, а также более чем трёхкратный прирост для LLama2-7b и Gemma2-9b. Кроме того, Trillium обеспечивает трёхкратное увеличение производительности инференса для Stable Diffusion XL (по отношению к TPU v5e). По соотношению цена/производительность TPU v6e демонстрирует 1,8-кратный рост по сравнению с TPU v5e и примерно двукратный рост по сравнению с TPU v5p. Появится ли более производительная модификация TPU v6p, не уточняется.
31.10.2024 [14:56], Владимир Мироненко
DIGITIMES Research: в 2024 году Google увеличит долю на рынке кастомных ИИ ASIC до 74 %Согласно отчету DIGITIMES Research, в 2024 году глобальные поставки ИИ ASIC собственной разработки для ЦОД, как ожидается, достигнут 3,45 млн единиц, а доля рынка Google вырастет до 74 %. Как сообщают аналитики Research, до конца года Google начнёт массовое производство нового поколения ИИ-ускорителей TPU v6 (Trillium), что ещё больше увеличит её присутствие на рынке. В 2023 году доля Google на рынке ИИ ASIC собственной разработки для ЦОД оценивалась в 71 %. В отчёте отмечено, что помимо самой высокой доли рынка, Google также является первым из трёх крупнейших сервис-провайдеров в мире, кто разработал собственные ИИ-ускорители. Первый TPU компания представила в 2016 году. Ожидается, что TPU v6 будет изготавливаться с применением 5-нм процесса TSMC, в основном с использованием 8-слойных чипов памяти HBM3 от Samsung. Также в отчёте сообщается, что Google интегрировала собственную архитектуру оптического интерконнекта в кластеры TPU v6, позиционируя себя в качестве лидера среди конкурирующих провайдеров облачных сервисов с точки зрения внедрения технологий и масштаба развёртывания. Google заменила традиционные spine-коммутаторы на полностью оптические коммутаторы Jupiter собственной разработки, которые позволяют значительно снизить энергопотребление и стоимость обслуживания ИИ-кластеров TPU POD по сравнению с решениями Broadcom или Mellanox. 
Источник изображения: cloud.google.com Кроме того, трансиверы Google получил ряд усовершенствований, значительно нарастив пропускную способность. Если в 2017 году речь шла о полнодуплексном 200G-решении, то в этом году речь идёт уже о 800G-решениях с возможностью модернизации до 1,6T. Скорость одного канала также существенно выросла — с 50G PAM4 в 2017 году до 200G PAM4 в 2024 году.
28.08.2024 [09:14], Владимир Мироненко
Google поделилась подробностями истории создания ИИ-ускорителей TPUВ огромной лаборатории в штаб-квартире Google в Маунтин-Вью (Калифорния, США) установлены сотни серверных стоек с ИИ-ускорителями TPU (Tensor Processing Unit) собственной разработки, с помощью которых производится обучение больших языковых моделей, пишет ресурс CNBC, корреспонденту которого компания устроила небольшую экскурсию. Первое поколение Google TPU, созданное ещё в 2015 году, и представляет собой ASIC для обработки ИИ-нагрузок. Сейчас компания использует такие, хотя и более современные ускорители для обучения и работы собственного чат-бота Gemini. С 2018 года TPU Google доступны облачным клиентам компании. В июле этого года Apple объявила, что использует их для обучения моделей ИИ, лежащих в основе платформы Apple Intelligence. 
TPU v1 (Источник изображений здесь и далее: Google) «В мире есть фундаментальное убеждение, что весь ИИ, большие языковые модели, обучаются на (чипах) NVIDIA, и, конечно, на решения NVIDIA приходится львиная доля объёма обучения. Но Google пошла по собственному пути», — отметил гендиректор Futurum Group Дэниел Ньюман (Daniel Newman). Благодаря расширению использованию ИИ подразделение Google Cloud увеличило доход, и в последнем квартальном отчёте холдинг Alphabet сообщил, что выручка от облачных вычислений выросла на 29 %, впервые превысив $10 млрд за квартал. Google была первым провайдером облачных вычислений, создавшим кастомные ИИ-чипы. Лишь спустя три года Amazon Web Services анонсировала свой первый ИИ-ускоритель Inferentia, Microsoft представила ИИ-ускоритель Azure Maia 100 в ноябре 2023 года, а в мае того же года Meta✴ рассказала об семействе MTIA. Однако лидирует на рынке генеративного ИИ компания OpenAI, обученная на ускорителях NVIDIA, тогда как нейросеть Gemini была представлена Google спустя год после презентации ChatGPT.  В Google рассказали, что впервые задумались о создании собственного чипа в 2014 году, когда в руководстве решили обсудить, насколько большими вычислительными возможностями нужно обладать, чтобы дать возможность всем пользователям поговорить с поиском Google в течение хотя бы 30 с каждый день. По оценкам, для этого потребовалось бы удвоить количество серверов в дата-центрах. «Мы поняли, что можем создать специальное аппаратное обеспечение, <…> в данном случае тензорные процессоры, для обслуживания [этой задачи] гораздо, гораздо более эффективно. Фактически в 100 раз эффективнее, чем было бы в противном случае», — отметил представитель Google. С выходом второго поколения TPU в 2018 году Google расширила круг выполняемых чипом задач, добавив к инференсу обучение ИИ-моделей. Процесс создания ИИ-ускорителя не только отличается высокой сложностью, но и требует больших затрат. Так что реализация таких проектов в одиночку не по силам даже крупным гиперскейлерам. Поэтому с момента создания первого TPU Google сотрудничает с разработчиком чипов Broadcom, который также помогает её конкуренту Meta✴ в создании собственных ASIC. Broadcom утверждает, что потратила более $3 млрд в рамках реализации совместных проектов.  В рамках сотрудничества Google отвечает за собственно вычислительные блоки, а Broadcom занимается разработкой I/O-блоков, SerDes и иных вспомогательных компонентов, а также упаковкой. Самы чипы выпускаются на TSMC. С 2018 года в Google трудятся ещё одни кастомные чипы — Video Coding Unit (VCU) Argos, предназначенной для обработки видео. Что касается TPU, то в этом году клиентам Google будет доступно шестое поколение TPU Trillium. Более того, им станут доступны и первые Arm-процессоры Axion собственной разработки. Google выходит на этот рынок с большим отставанием от конкурентов. Amazon выпустила первый собственный процессор Graviton в 2018 году, Alibaba Yitian 710 появились в 2021 году, а Microsoft анонсировала Azure Cobalt 100 в ноябре. Все эти чипы основаны на архитектуре Arm — более гибкой и энергоэффективной альтернативе x86. Энергоэффективность имеет решающее значение. Согласно последнему экологический отчёту Google, с 2019 по 2023 год выбросы компании выросли почти на 50 %, отчасти из-за увеличения количества ЦОД для ИИ-нагрузок. Для охлаждения ИИ-серверов требуется огромное количество воды. Именно поэтому начиная с третьего поколения TPU компания использует прямое жидкостное охлаждение, которое только теперь становится практически обязательным для современных ИИ-ускорителей вроде NVIDIA Blackwell.
04.08.2024 [15:25], Сергей Карасёв
В Google Cloud появился выделенный ИИ-кластер для стартапов Y CombinatorОблачная платформа Google Cloud, по сообщению TechCrunch, развернула выделенный субсидируемый кластер для ИИ-стартапов, которые поддерживаются венчурным фондом Y Combinator. Предполагается, что данная инициатива поможет Google привлечь в своё облако перспективные компании, которым в будущем могут понадобиться значительные вычислительные ресурсы. Отмечается, что для ИИ-стартапов на ранней стадии одной из самых распространённых проблем является ограниченная доступность вычислительных мощностей. Крупные предприятия обладают достаточными финансами для заключения многолетних соглашений с поставщиками облачных услуг на доступ к НРС/ИИ-сервисам. Однако у небольших фирм с этим возникают сложности. Ожидается, что Google Cloud поможет в решении данной проблемы. Google предоставит выделенный кластер с приоритетным доступом для стартапов Y Combinator. Платформа базируется на ускорителях NVIDIA и тензорных процессорах (TPU) самой Google. Каждый участник программы получит кредиты на сумму $350 тыс. для использования облачных сервисов Google в течение двух лет. Кроме того, Google предоставит стартапам кредиты в размере $12 тыс. на расширенную поддержку и бесплатную годовую подписку Google Workspace Business Plus. Молодые компании также смогут консультироваться с экспертами Google в области ИИ. 
Источник изображения: Google Оказав поддержку ИИ-стартапам, Google в дальнейшем сможет рассчитывать на заключение с ними долгосрочных контрактов на обслуживание. Говорится, что за последние 18 лет примерно 5 % стартапов Y Combinator стали единорогами с оценкой $1 млрд и более. Такие компании могут принести облачной платформе Google значительную выручку в случае заключения соглашения о сотрудничестве. С другой стороны, фонд Y Combinator сможет привлечь больше перспективных ИИ-проектов, предлагая вычислительные ресурсы Google вместе со своей поддержкой. Аналогичные программы есть и у других игроков. Так, венчурный инвестор Andreessen Horowitz (a16z) тоже запасается ИИ-ускорителями, чтобы стать более привлекательным для ИИ-стартапов. AWS предлагает ИИ-стартапам доступ к облаку и сервисам, а Alibaba Cloud готова предоставить ресурсы в обмен на долю в стартапе. Сама Google на днях наняла основателей стартапа Character.AI и лицензировал его модели. Стартапу, по-видимому, не хватило средств на ИИ-ускорители для дальнейшего развития.
07.12.2023 [21:04], Сергей Карасёв
Google представила Cloud TPU v5p — свой самый мощный ИИ-ускорительКомпания Google анонсировала свой самый высокопроизводительный ускоритель для задач ИИ — Cloud TPU v5p. По сравнению с изделием предыдущего поколения TPU v4 обеспечивается приблизительно 1,7-кратный пророст быстродействия на операциях BF16. Впрочем, для Google важнее то, что она наряду с AWS является одной из немногих, кто при разработке ИИ не зависит от дефицитных ускорителей NVIDIA. К этому же стремится сейчас и Microsoft. Решение Cloud TPU v5p оснащено 95 Гбайт памяти HBM с пропускной способностью 2765 Гбайт/с. Для сравнения: конфигурация TPU v4 включает 32 Гбайт памяти HBM с пропускной способностью 1228 Гбайт/с. 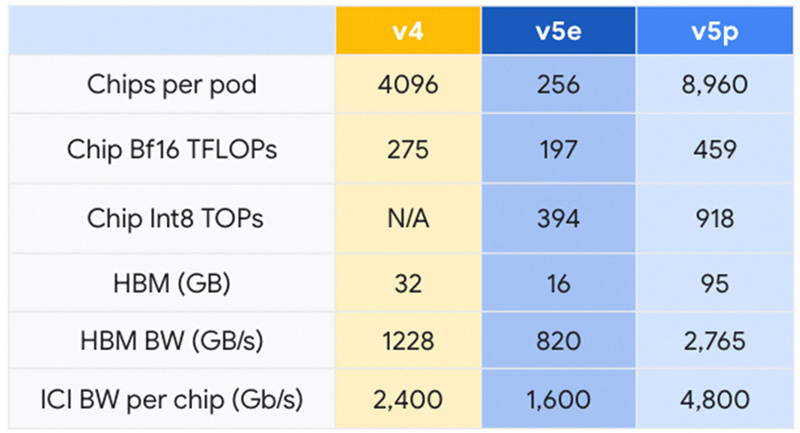
Источник изображений: Google Кластер на базе Cloud TPU v5p может содержать до 8960 чипов, объединённых высокоскоростным интерконнектом со скоростью передачи данных до 4800 Гбит/с на чип. В случае TPU v4 эти значения составляют соответственно 4096 чипов и 2400 Гбит/с. Что касается производительности, то у Cloud TPU v5p она достигает 459 Тфлопс (BF16) против 275 Тфлопс у TPU v4. На операциях INT8 новинка демонстрирует результат до 918 TOPS. 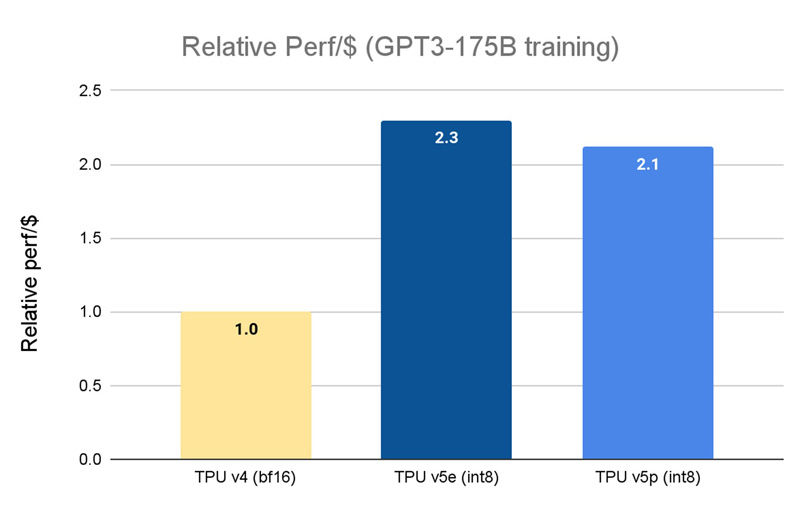 В августе нынешнего года Google представила ИИ-ускоритель TPU v5e, созданный для обеспечения наилучшего соотношения стоимости и эффективности. Это изделие с 16 Гбайт памяти HBM (820 Гбит/с) показывает быстродействие 197 Тфлопс и 394 TOPS на операциях BF16 и INT8 соответственно. При этом решение обеспечивает относительную производительность на доллар на уровне $1,2 в пересчёте на чип в час. У TPU v4 значение равно $3,22, а у новейшего Cloud TPU v5p — $4,2 (во всех случаях оценка выполнена на модели GPT-3 со 175 млрд параметров). 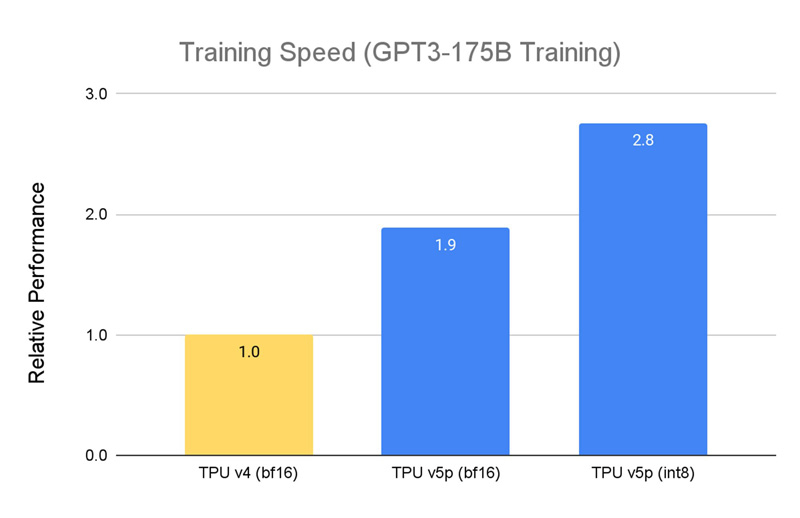 По заявлениям Google, чип Cloud TPU v5p может обучать большие языковые модели в 2,8 раза быстрее по сравнению с TPU v4. Более того, благодаря SparseCores второго поколения скорость обучения моделей embedding-dense увеличивается приблизительно в 1,9 раза. На базе TPU и GPU компания предоставляет готовый программно-аппаратный стек AI Hypercomputer для комплексной работы с ИИ. Система объединяет различные аппаратные ресурсы, включая различные типы хранилищ и оптический интерконнект Jupiter, сервисы GCE и GKE, популярные фреймворки AX, TensorFlow и PyTorch, что позволяет быстро и эффективно заниматься обучением современных моделей, а также организовать инференс.
30.08.2023 [16:04], Алексей Степин
Google Cloud анонсировала новое поколение собственных ИИ-ускорителей TPU v5eКак известно, Google Cloud использует в своей инфраструктуре не только сторонние ускорители, но и TPU собственной разработки. Эти кастомные ASIC компания продолжает активно развивать — она анонсировала предварительную доступность виртуальных машин с новейшими TPU v5e, разработка которых заняла более двух лет. Сам чип TPU v5e позиционируется Google как эффективный со всех точек зрения ускоритель, предназначенный для обучения нейросетей или инференс-систем среднего и большого классов. В сравнении с TPU v4 он, по словам Google, обеспечивает вдвое более высокую производительность в пересчёте на доллар для обучения больших языковых моделей (LLM) и генеративных нейросетей. Для инференс-систем преимущество по тому же критерию составляет 2,5x. В сравнении с аналогичными решениями на базе других чипов, например, GPU, выигрыш может составить и 4x. Каждый чип TPU v5e включает четыре блока матричных вычислений, по одному блоку для скалярных и векторных расчётов, а также HBM2-память. 
Источник изображения: Google Компания отмечает, что не экономит на технических характеристиках TPU v5e в угоду рентабельности. Кластеры могут включать до 256 чипов TPU v5e, объединённых высокоскоростным интерконнектом с совокупной пропускной способностью более 400 Тбит/с. Производительность такой платформы составляет 100 Попс (Петаопс) в INT8-вычислениях. Правда, здесь есть нюанс: INT8-производительности TPU v5e составляет 393 Тфлопс против 275 Тфлопс у v4, но вот BF16-производительность у TPU v4 составляет те же 275 Тфлопс, тогда как у v5e этот показатель равен уже 197 Тфлопс. 
Источник изображения: Google В настоящее время для предварительного тестирования доступно уже восемь вариантов инстансов на базе v5e, а в зависимости от конфигурации количество TPU может составлять от 1 до более чем 250. В рамках платформы обеспечена полная интеграция с Google Kubernetes Engine, собственной платформой Vertex AI, а также с большинством современных фреймворков, включая PyTorch, TensorFlow и JAX. Работа с TPU v5e будет значительно дешевле, чем с TPU v4 — $1,2/час против $3,4/час (за чип). 
Источник изображения: Google В настоящее время машины с TPU v5e доступны только в североамериканском регионе (us-west4), но в дальнейшем возможность их использования появится в регионах EMEA (Нидерланды) и APAC (Сингапур). Также Google предлагает опробовать технологию Multislice, позволяющей объединять в единый комплекс десятки тысяч TPU v5e или TPU v4, где каждый «слайс» может содержать до 3072 чипов TPU (v4). В максимальной конфигурации можно развернуть 64 инстанса, работающих с 256 кластерами TPU v5e. Сама компания уже использует новые чипы для своего поисковика и Google Photos.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
23.09.2022 [19:58], Алексей Степин
Google заявила, что использует процессоры SiFive Intelligence X280 на RISC-V вместе со своим TPUАрхитектура RISC-V продолжает понемногу набирать популярность и завоевывать внимание ведущих игроков на рынке информационных технологий. На мероприятии AI Hardware Summit в совместном выступлении ведущего архитектора SiFive и архитектора Google TPU было отмечено, что Google уже использует процессоры с ядрами Intelligence X280. Эти ядра — один из вариантов воплощения архитектуры RISC-V, из продвигаемых SiFive. Анонс Intelligence X280 состоялся ещё в апреле 2021 года, когда SiFive выпустила апдейт 21G1, основной упор в котором был сделан на максимизацию характеристик уже существующих ядер RISC-V в области операций с плавающей запятой. 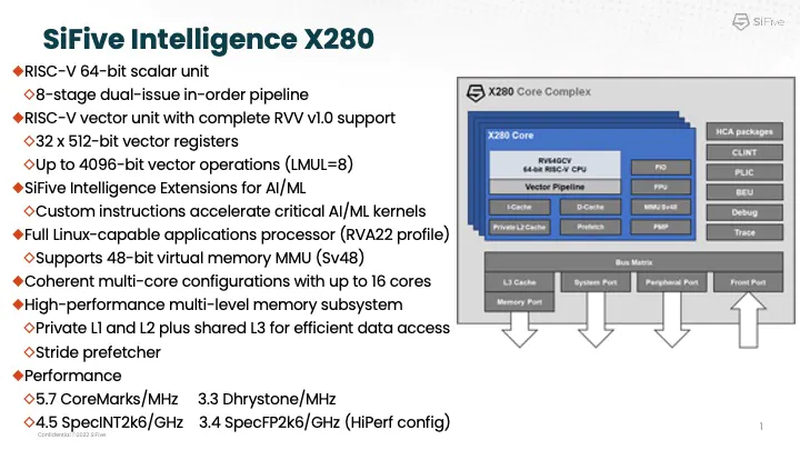
Процессорное ядро Intelligence X280 и его возможности. Источник: SiFive Как следует из названия, данный вариант процессора оптимизирован под задачи машинного интеллекта: ядра RISC-V в нём дополнены векторными конвейерами RISC-V Vector (RVV) с производительностью 4,5 Тфлопс BF16 и 9,2 Топс INT8 на ядро. Одной из самых интересных технологий в Intelligence X280 является интерфейс Vector Coprocessor Interface eXtension (VCIX). 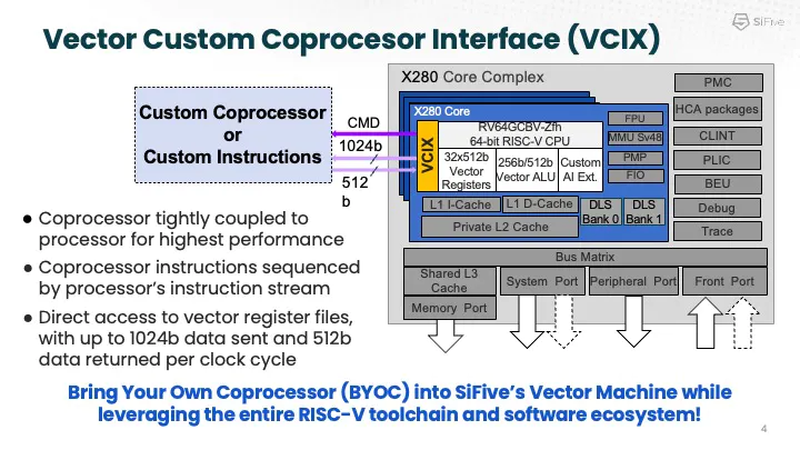
Устройство VCIX. Источник: SiFive Он позволяет подключать внешние ускорители векторных операций напрямую к регистровому файлу X280, минуя основную шину и кеши. Такой подход минимизирует накладные расходы и не требует использования специальных средств при программировании системы, поскольку связка из X280 и подключённого по VCIX ускорителя работает полностью прозрачно в рамках стандартных средств разработки SiFive. 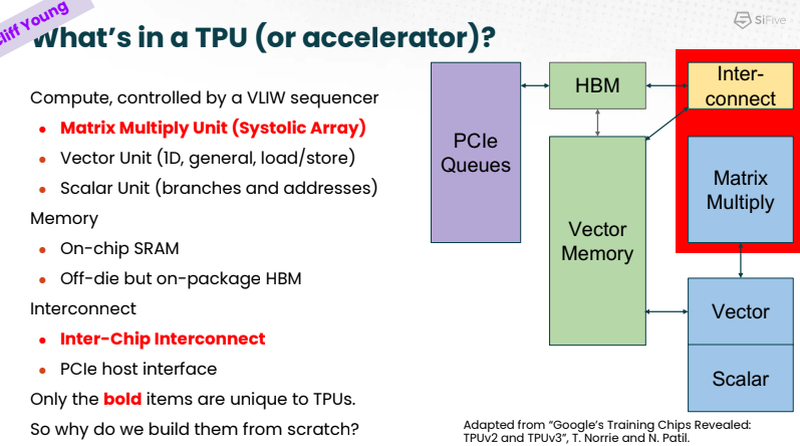
Сильные стороны Google TPU. Источник: SiFive На саммите в Санта-Кларе разработчики SiFive и Google TPU рассказали, что процессоры Intelligence X280 используются в качестве хост-процессоров к ускорителям систолической векторной математики Google MXU; правда, о масштабах внедрения RISC-V в Google сведений приведено не было. 
Разделение труда Intelligence X280 и Google TPU. Источник: SiFive Ранее уже появлялась информация, что Google активно тестирует ASIC сторонних разработчиков в связке со своим TPU, в частности, чипы Broadcom, дабы разгрузить его от второстепенных задач и сделать упор на сильных сторонах — матричной математике и быстром интерконнекте. Похоже, SiFive Intelligence X280 решает задачу интеграции подобного рода задач более изящно: как отметил в выступлении Клифф Янг (Cliff Young), архитектор Google TPU, с помощью VCIX можно построить машину, позволяющую усидеть на двух стульях (build a machine that lets you have your cake and eat it too). |
|

