В 2024 году нельзя пожаловаться на отсутствие подходящего интерконнекта, если целью является «сшивка» в единую систему сотен, тысяч или даже десятков тысяч ускорителей. Есть NVIDIA NVLink и InfiniBand. Google использует оптические коммутаторы OCS, AMD вскоре выведет Infinity Fabric на межузловой уровень, да и старый добрый Ethernet отнюдь не собирается сдавать позиций и обретает новую жизнь в виде Ultra Ethernet.
Проблема не в наличии и выборе подходящего интерконнекта, а в резкой потере пропускной способности за пределами упаковки чипа (т.н. Memory Wall). Да, память HBM быстра, но намертво привязана к вычислительным ресурсам, а в итоге, как отметил глава Celestial AI в комментарии изданию The Next Platform, индустрия ИИ использует ускорители NVIDIA в качестве самых дорогих в мире контроллеров памяти.
Celestial AI ещё в прошлом году объявила, что ставит своей целью создание универсального «умного» интерконнекта на основе фотоники, который смог бы использоваться во всех нишах, требующих активного обмена большими потоками данных, от межкристалльной (chip-to-chip) до межузловой (node-to-node). Недавно она получила дополнительный пакет инвестиций объёмом $175 млн.

Источник изображений здесь и далее: Celestial AI
Технология, названная Photonic Fabric, если верить заявлениям Celestial AI, способна в 25 раз увеличить пропускную способность и объёмы доступной памяти при на порядок меньшем энергопотреблении в сравнении с существующими системами соединений. Развивается она в трёх направлениях: чиплеты, интерпозеры и оптический аналог технологии Intel EMIB под названием OMIB.
Наиболее простым способом интеграции своей технологии Celestial AI справедливо считает чиплеты. В настоящее время разработанный компанией модуль обеспечивает пропускную способность за пределами чипа на уровне 14,4 Тбит/с (1,8 Тбайт/с), а по размерам он немного уступает стандартной сборке HBM. Но это лишь первое поколение: во втором поколении Photonic Fabric 56-Гбит/с SerDes-блоки SerDes будут заменены на блоки класса 112 Гбит/с (PAM4).
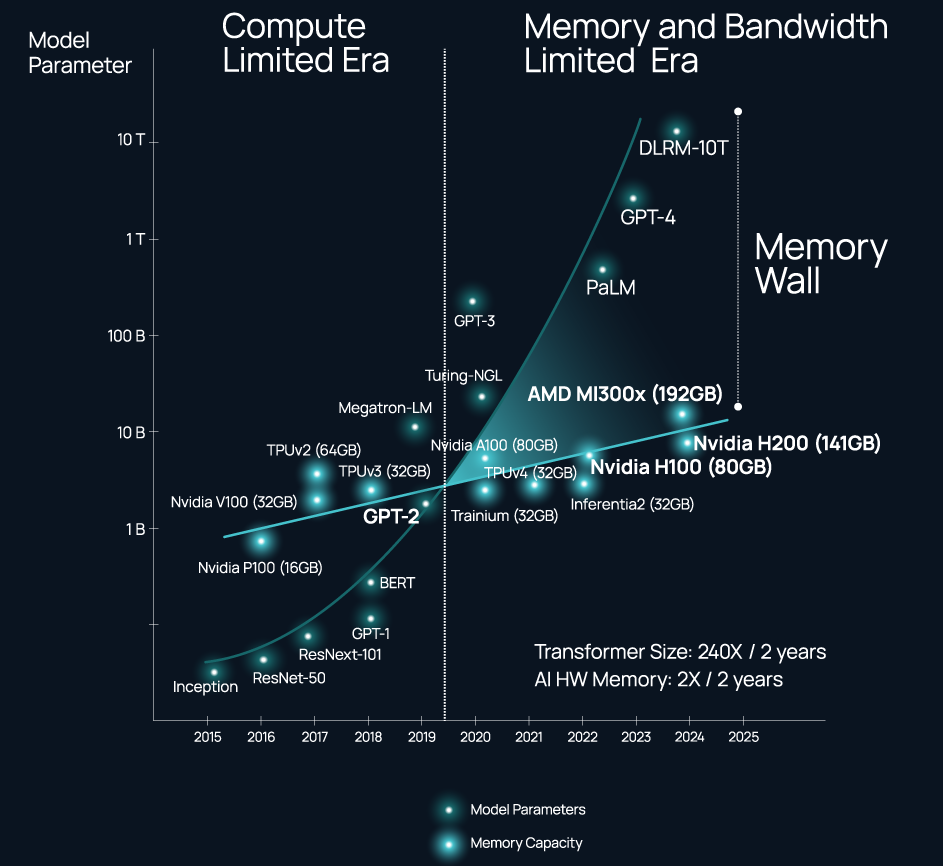
Пресловутая «Стена Памяти»
Поскольку речь идёт о системах с дезагрегацией ресурсов, проблему быстрого доступа к большому объёму памяти Celestial AI предлагает решить следующим образом: новый чиплет, содержащий помимо интерконнекта две сборки HBM общим объёмом 72 Гбайт, получит также поддержку четырёх DDR5 DIMM суммарным объёмом до 2 Тбайт. С использованием 5-нм техпроцесса такой чиплет сможет легко превратить HBM в быстрый сквозной кеш (write through) для DDR5.
Фактически речь идёт об относительно простом и сравнительно доступном способе превратить любой процессор с чиплетной компоновкой в дезагрегированный аналог Intel Xeon Max или NVIDIA Grace Hopper. При этом латентность при удалённом обращении к памяти не превысит 120 нс, а энергозатраты в данном случае составят на порядок меньшую величину, нежели в случае с NVLink — всего 6,2 пДж/бит против 62,5 пДж/бит у NVIDIA.

Новый чиплет Celestial породнит HBM с DDR5 теснее, нежели это сделала NVIDIA
Таким образом, с использованием новых чиплетных контроллеров памяти становятся реальными системы, где все чипы, от CPU до сетевых процессоров и ускорителей, будут объединены единым фотонным интерконнектом и при этом будут иметь общий пул памяти DDR5 большого объёма с эффективным HBM-кешированием. По словам Celestial AI, она уже сотрудничает с некоторыми гиперскейлерами и с одним «крупным производителем процессоров».
По словам руководителя Celestial AI, образцы чиплетов с поддержкой Photonic Fabric появятся во II половине 2025 года, а массовое внедрение начнется уже в 2027 году. Однако это может оказаться гонкой на выживание: Ayar Labs, другой разработчик фотоники, получившая поддержку со стороны Intel, уже показала прототип процессора с интегрированным фотонным интерконнектом.
А Lightmatter ещё в декабре получила финансирование в объёме $155 млн на разработку фотонного интерпозера Passage и якобы уже сотрудничает с клиентами, заинтересованными в создании суперкомпьютера с 300 тыс. узлов. Нельзя сбрасывать со счетов и Eliyan, предлагающую вообще отказаться от технологии интерпозеров и заменить её на контроллеры физического уровня NuLink.
Источник:

