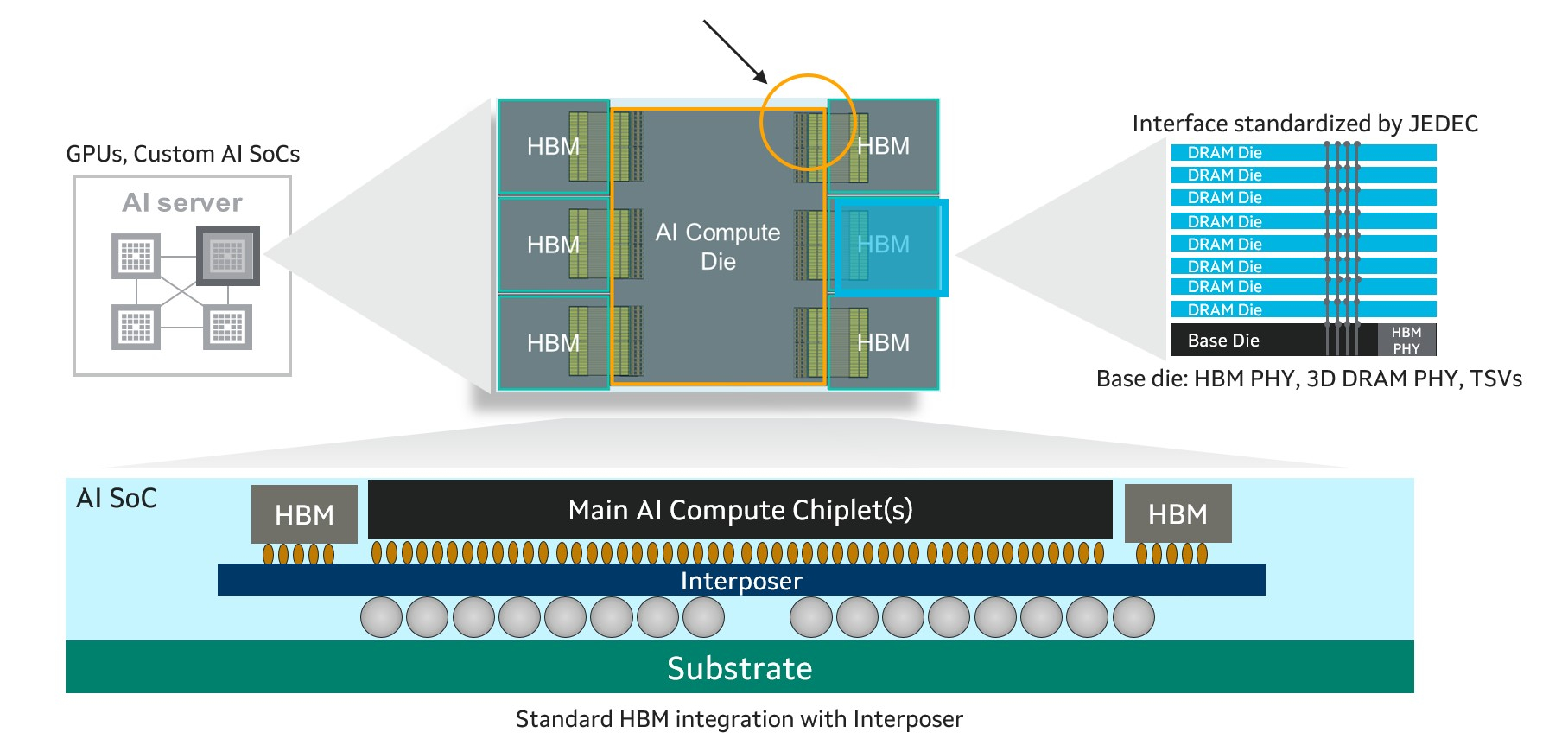
Marvell Technology анонсировала новый подход к интеграции HBM (CHBM) в специализированные XPU, который предоставляет адаптированные интерфейсы для оптимизации производительности, мощности, размера кристалла и стоимости для конкретных конструкций ИИ-ускорителей. Как указано в пресс-релизе, этот подход учитывает вычислительный «кремний», стеки HBM и упаковку. Marvell сотрудничает с облачными клиентами и ведущими производителями HBM, такими, как Micron, Samsung и SK hynix.
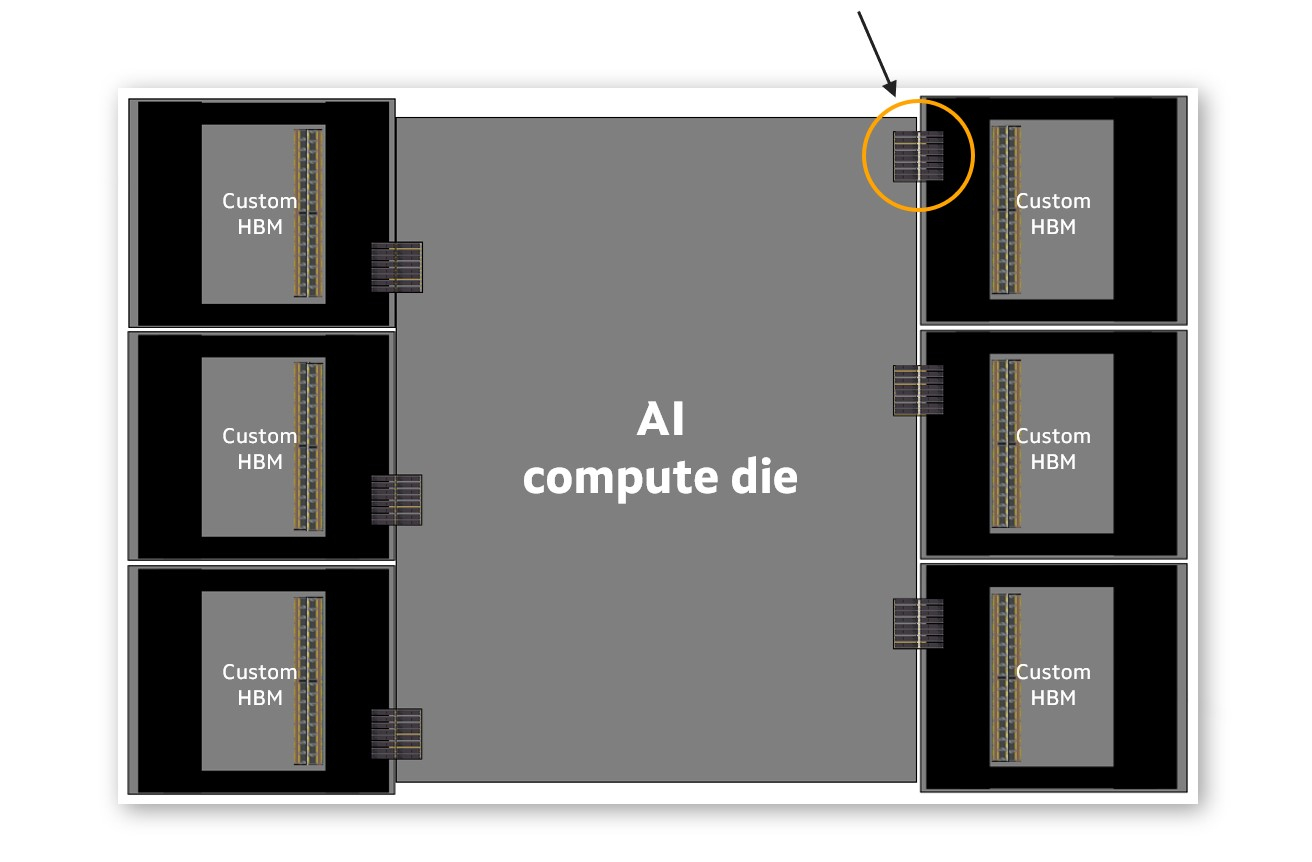
CHBM повышает возможности XPU, ускоряя ввода-вывод между внутренними кристаллами самого ускорителя и базовыми кристаллами HBM. Это приводит к повышению производительности и снижению энергопотребления интерфейса памяти до 70 % по сравнению со стандартными интерфейсами HBM. Оптимизированные интерфейсы также уменьшают требуемую площадь кремния в каждом кристалле, позволяя интегрировать логику для поддержки HBM в базовый кристалл и сэкономить до 25 % площади.
Источник изображений: Marvell
Высвободившееся пространство может быть использовано для размещения дополнительных вычислительных или функциональных блоков и поддержки до 33 % большего количества стеков HBM. Всё это повышает производительность и энергоэффективность XPU, одновременно снижая совокупную стоимость владения для операторов облачных инфраструктур. Правда, это же означает и несоответствие стандартами JEDEC. Как отметил ресурс ServeTheHome, HBM4 требует более 2000 контактов, т.е. вдвое больше, чем HBM3. Для кастомного решения нет необходимости в таком количестве контактов, что также высвобождает место для размещения других компонентов.
«Ведущие операторы ЦОД масштабируются с помощью индивидуальной инфраструктуры. Улучшение XPU путем адаптации HBM к конкретной производительности, мощности и общей стоимости владения — это последний шаг в новой парадигме разработки и поставки ускорителей ИИ», — сказал Уилл Чу (Will Chu), старший вице-президент Marvell и генеральный менеджер группы Custom, Compute and Storage. В свою очередь, Гарри Юн (Harry Yoon), корпоративный исполнительный вице-президент Samsung Electronics, отметил, что оптимизация HBM для конкретных XPU и программных сред значительно повысит производительность облачной инфраструктуры операторов и её энергоэффективность.
Согласно данным ServeTheHome, в этом году гиперскейлеры увеличили капзатраты примерно на $100 млрд. Следующее поколение ИИ-кластеров будет в десять и более раз превосходить по мощности систему xAI Colossus на базе 100 тыс. NVIDIA H100. Отказ от стандартов JEDEC и появление возможности настройки памяти с учётом потребностей гиперскейлеров является монументальным шагом для отрасли. Также этого говорит о нацеленности архитектуры Marvell XPU на гиперскейлеров, поскольку в таком «тюнинге» памяти небольшие заказчики не нуждаются.
Источники:

