Стартап Groq сообщил о значительных достижениях в области инференса с использованием ускорителя LPU, разработанного для запуска больших языковых моделей (LLM), таких как GPT, Llama и Mistral. Groq LPU имеет один массивно-параллельный тензорный процессор TSP, который обеспечивает производительность до 750 TOPS INT8 и до 188 Тфлопс FP16. LPU Groq оснащён локальной SRAM объемом 230 Мбайт с пропускной способностью 80 Тбайт/с.
Как сообщает компания, при запуске модели Mixtral 8x7B ускоритель LPU обеспечил скорость инференса 480 токенов в секунду, что является одним из ведущих показателей инференса в отрасли. В таких моделях, как Llama 2 70B с длиной контекста 4096 токенов, Groq может обеспечить скорость инференса 300 токенов/с, тогда как в меньшей модели Llama 2 7B с 2048 токенами контекста скорость инференса составляет 750 токенов/с.

Изображение: Groq
Согласно рейтингу бенчмарка LLMPerf, LPU Groq превосходит результаты систем облачных провайдеров на базе традиционных ИИ-ускорителей в деле запуска LLM Llama в конфигурациях от 7 до 70 млрд параметров. Groq лидирует по скорости инференса и занимает второе место по показателю задержки.
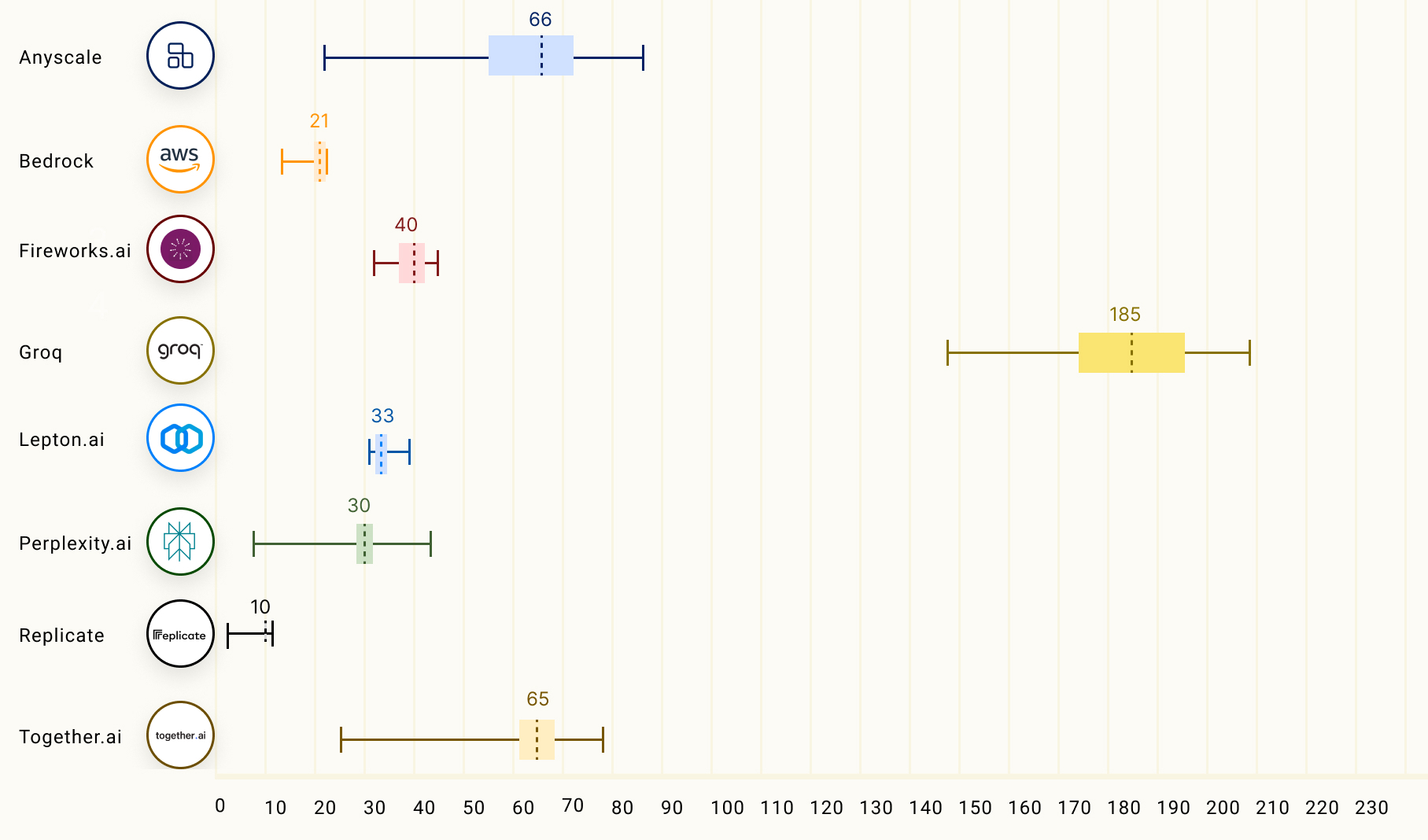
Источник: The Ray Team
Для сравнения, бесплатный чат-бот ChatGPT на базе GPT-3.5 обеспечивает обработку около 40 токенов/с. Текущие LLM с открытым исходным кодом, такие как Mixtral 8x7B, могут превосходить GPT 3.5 в большинстве тестов, и теперь могут работать со скоростью почти 500 токенов/с.
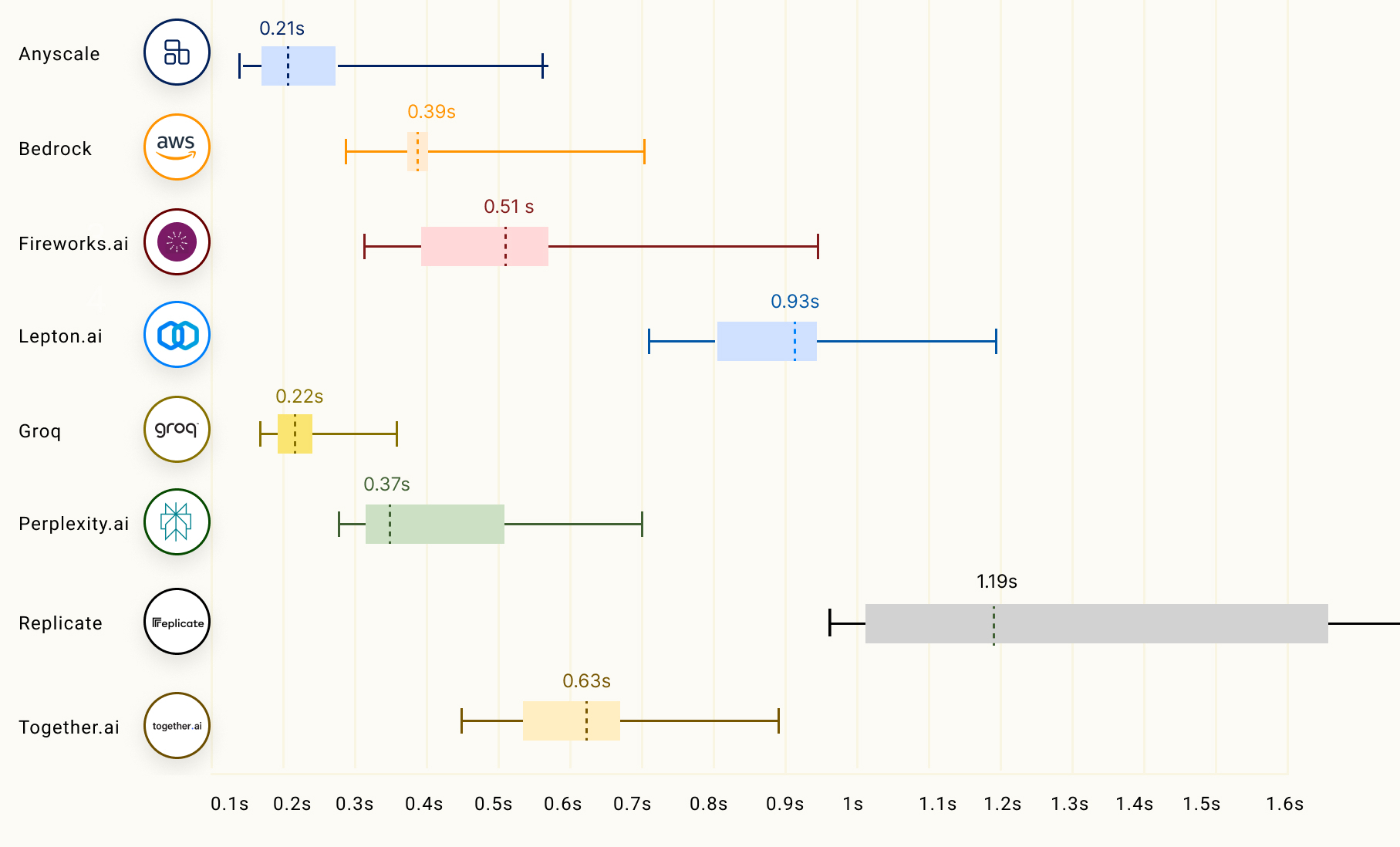
Источник: The Ray Team
Опубликованные данные наглядно подтверждают, что предлагаемый Groq ускоритель LPU Groq значительно превосходит системы для инференса, предлагаемые NVIDIA, AMD и Intel, говорит компания. Groq не раскрывает имена своих заказчиков, но в настоящее время её ИИ-решения используются, например, Аргоннской национальной лабораторией Министерства энергетики США.
Источники:

