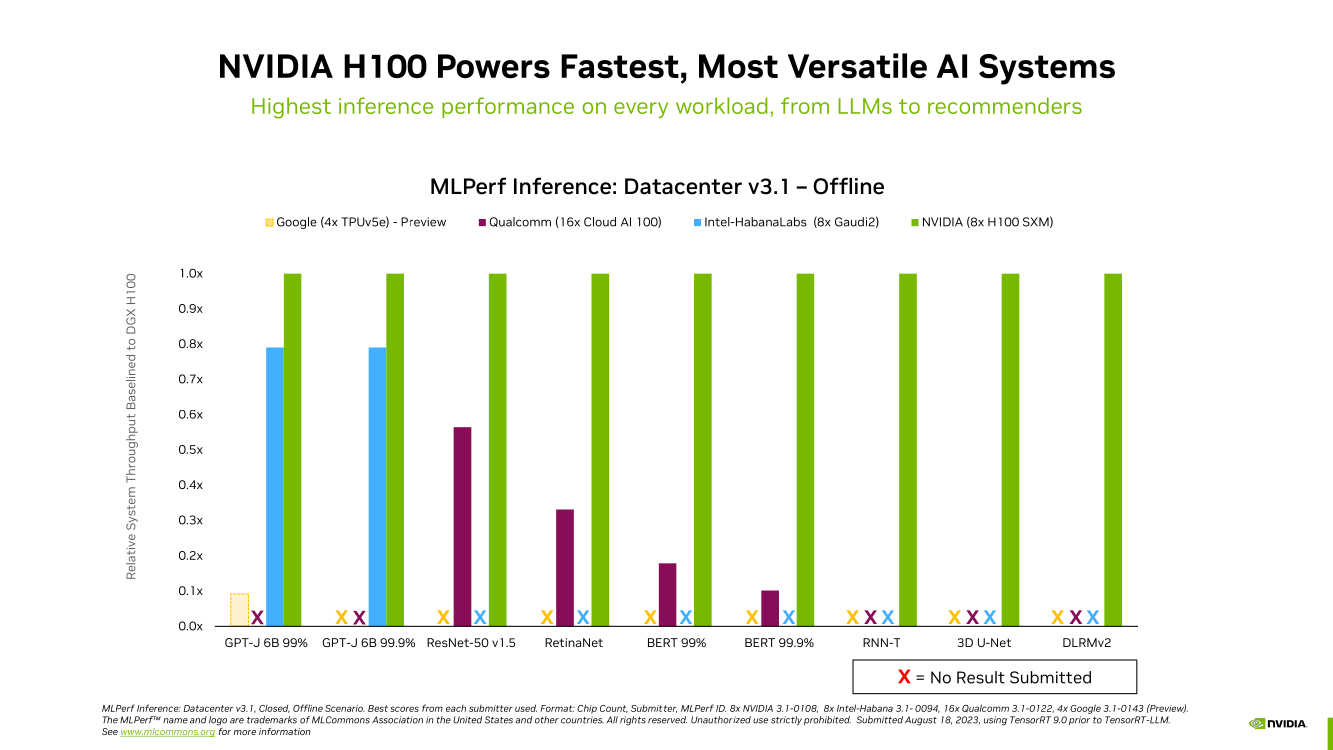
Компания NVIDIA сообщила о том, что суперчип NVIDIA GH200 Grace Hopper и ускоритель H100 лидируют во всех тестах производительности ЦОД в бенчмарке MLPerf Inference v3.1 для генеративного ИИ, который включает инференс-задачи в области компьютерного зрения, распознавания речи, обработки медицинских изображений, а также работу с большими языковыми моделями (LLM).
Ранее NVIDIA уже объявляла о рекордах H100 в новом бенчмарке MLPerf. Теперь говорится, что суперчип GH200 Grace Hopper впервые прошёл все тесты MLPerf. Вместе с тем системы, оснащенные восемью ускорителями H100, обеспечили самую высокую пропускную способность в каждом тесте MLPerf Inference. Решения NVIDIA прошли обновленное тестирование в области рекомендательных систем (DLRM-DCNv2), а также выполнили первый эталонный тест GPT-J — LLM с 6 млрд параметров.
Примечательно, что GH200 оказался до 17 % быстрее H100, хотя чип самого ускорителя в обоих продуктах один и тот же. NVIDIA объясняет это несколько факторами. Во-первых, у GH200 больше набортной памяти — 96 Гбайт против 80 Гбайт. Во-вторых, ПСП составляет 4 Тбайт/с, а сам чип является гибридным, так что для передачи данных между LPDDR5x и HBM3 не используется PCIe. В-третьих, GH200 при низкой нагрузке на CPU умеет отдавать часть энергии ускорителю, оставаясь в заданных рамках энергопотребления. Правда, в тестах GH200 работал на полную мощность, т.е. с TDP на уровне 1 кВт (UPD: NVIDIA уточнила, что реально потребление GH200 под полной нагрузкой составляет 750–800 Вт).

Источник изображений: NVIDIA
Отдельно внимание уделено оптимизации ПО — на днях NVIDIA анонсировала открый программный инструмент TensorRT-LLM, предназначенный для ускорения исполнения LLM на продуках NVIDIA. Этот софт даёт возможность вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B (входит в состав MLPerf Inference v3.1). NVIDIA отмечает, что улучшение ПО позволяет клиентам с течением времени повышать производительность ИИ-систем без дополнительных затрат.
Также отмечается, что модули NVIDIA Jetson Orin благодаря новому ПО показали прирост производительности до 84 % на задачах обнаружения объектов по сравнению с предыдущим раундом тестирования MLPerf. Ускорение произошло благодаря задействованию Programmable Vision Accelerator (PVA), отдельного движка для обработки изображений и алгоритмов компьютерного зрения работающего независимо от CPU и GPU.

Сообщается также, что ускоритель NVIDIA L4 в последних тестах MLPerf выполнил весь спектр рабочих нагрузок, показав отличную производительность. Так, в составе адаптера с энергопотреблением 72 Вт этот ускоритель демонстрирует в шесть раз более высокое быстродействие, нежели CPU, у которых показатель TDP почти в пять раз больше. Кроме того, NVIDIA применила новую технологию сжатия модели, что позволило продемонстрировать повышение производительности в 4,4 раза при использовании BERT LLM на ускорителе L4. Ожидается, что этот метод найдёт применение во всех рабочих нагрузках ИИ.
В число партнёров при проведении тестирования MLPerf вошли поставщики облачных услуг Microsoft Azure и Oracle Cloud Infrastructure, а также ASUS, Connect Tech, Dell Technologies, Fujitsu, Gigabyte, Hewlett Packard Enterprise, Lenovo, QCT и Supermicro. В целом, MLPerf поддерживается более чем 70 компаниями и организациями, включая Alibaba, Arm, Cisco, Google, Гарвардский университет, Intel, Meta✴, Microsoft и Университет Торонто.
Источник:

