Астрологи объявили месяц AMD EPYC. Количество материалов о Rome увеличилось вдвое.
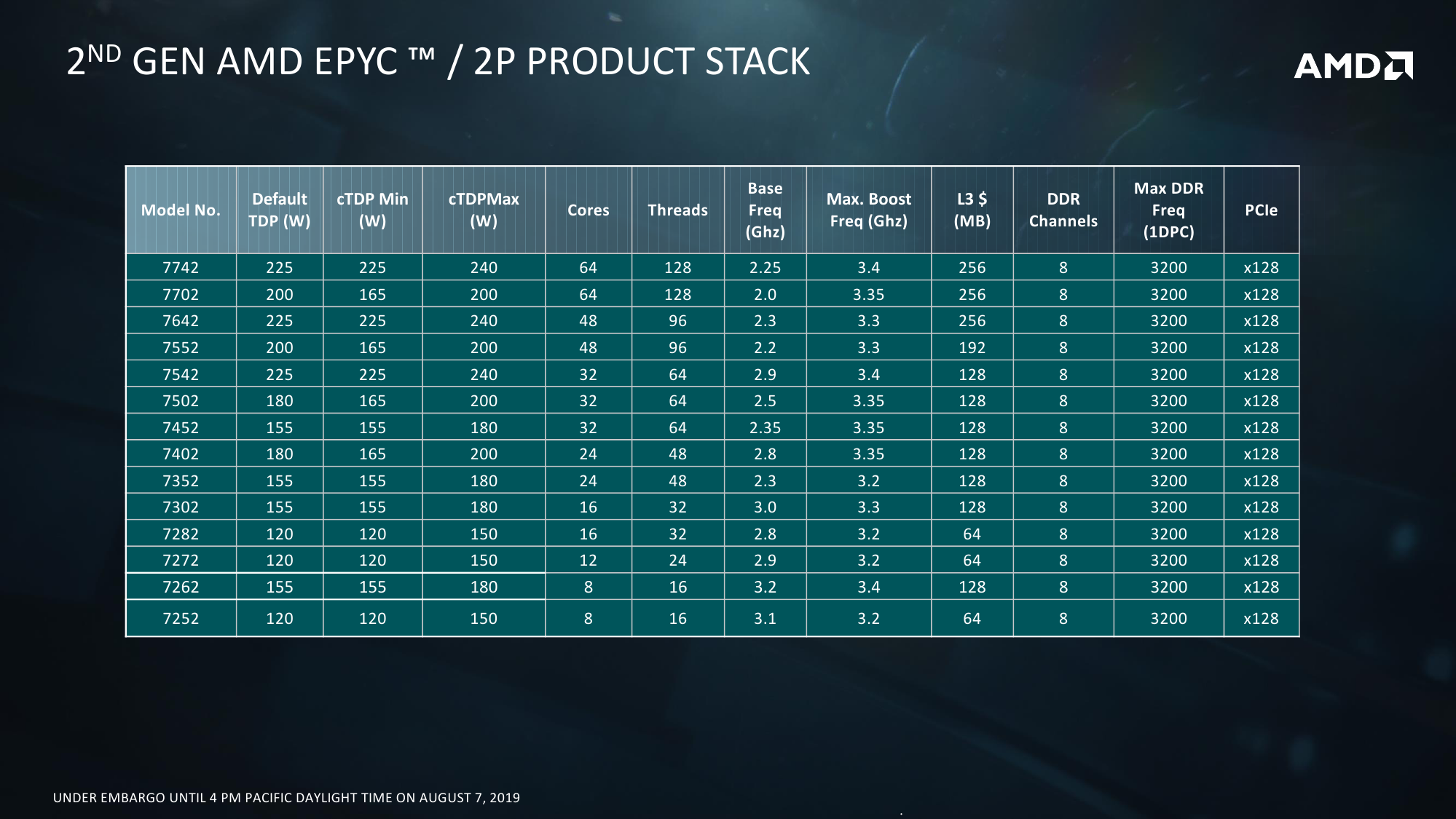
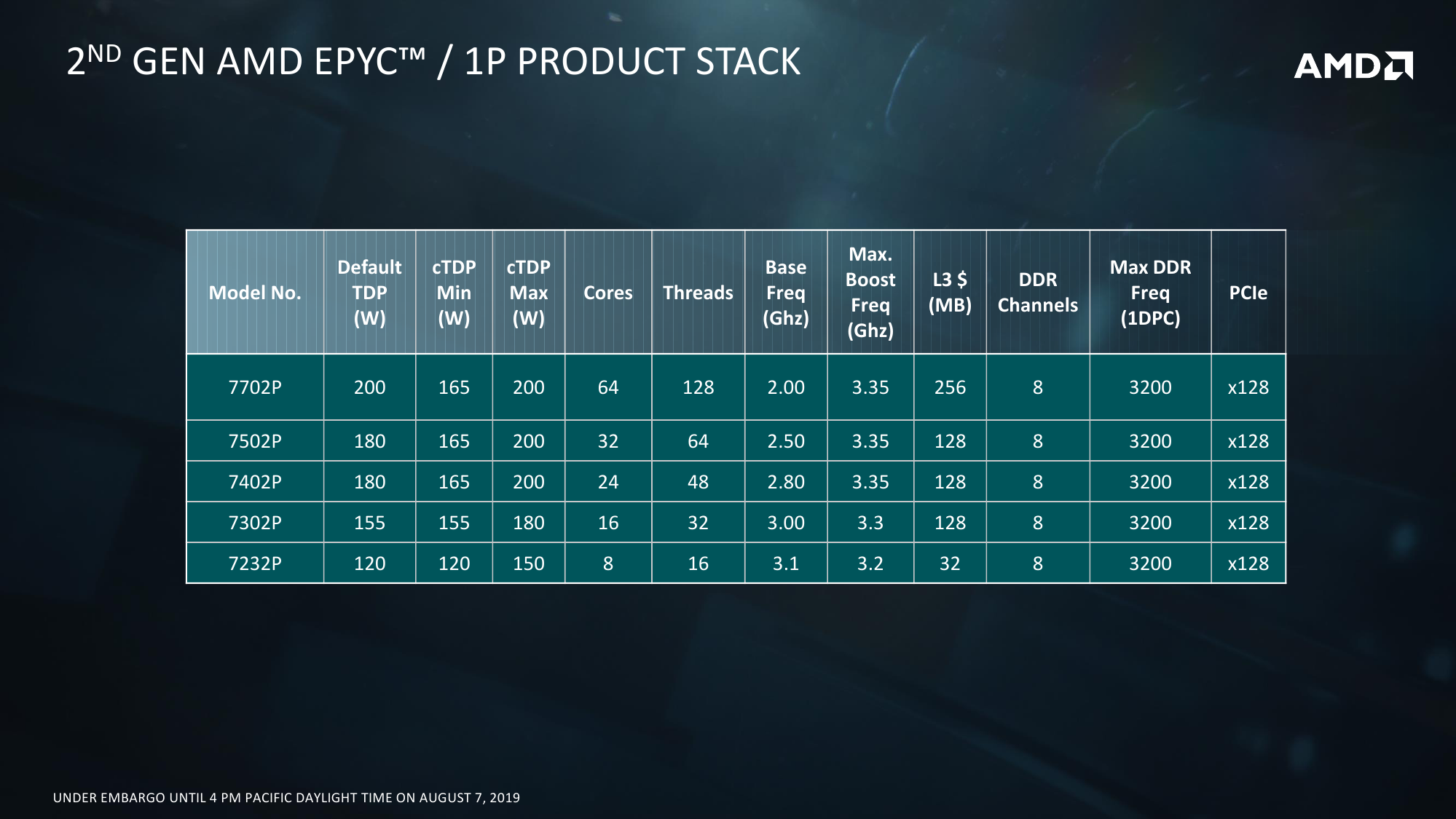
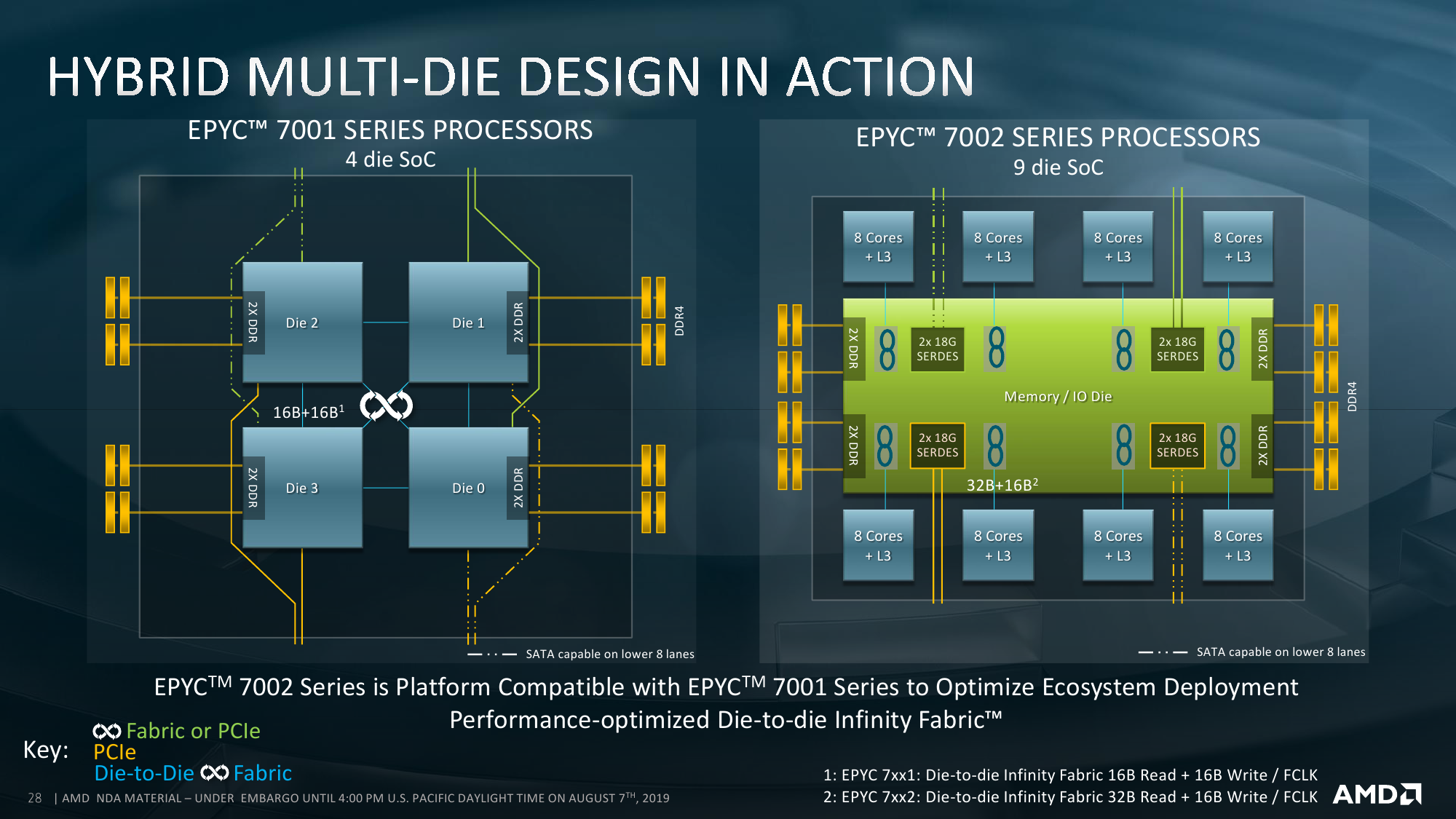
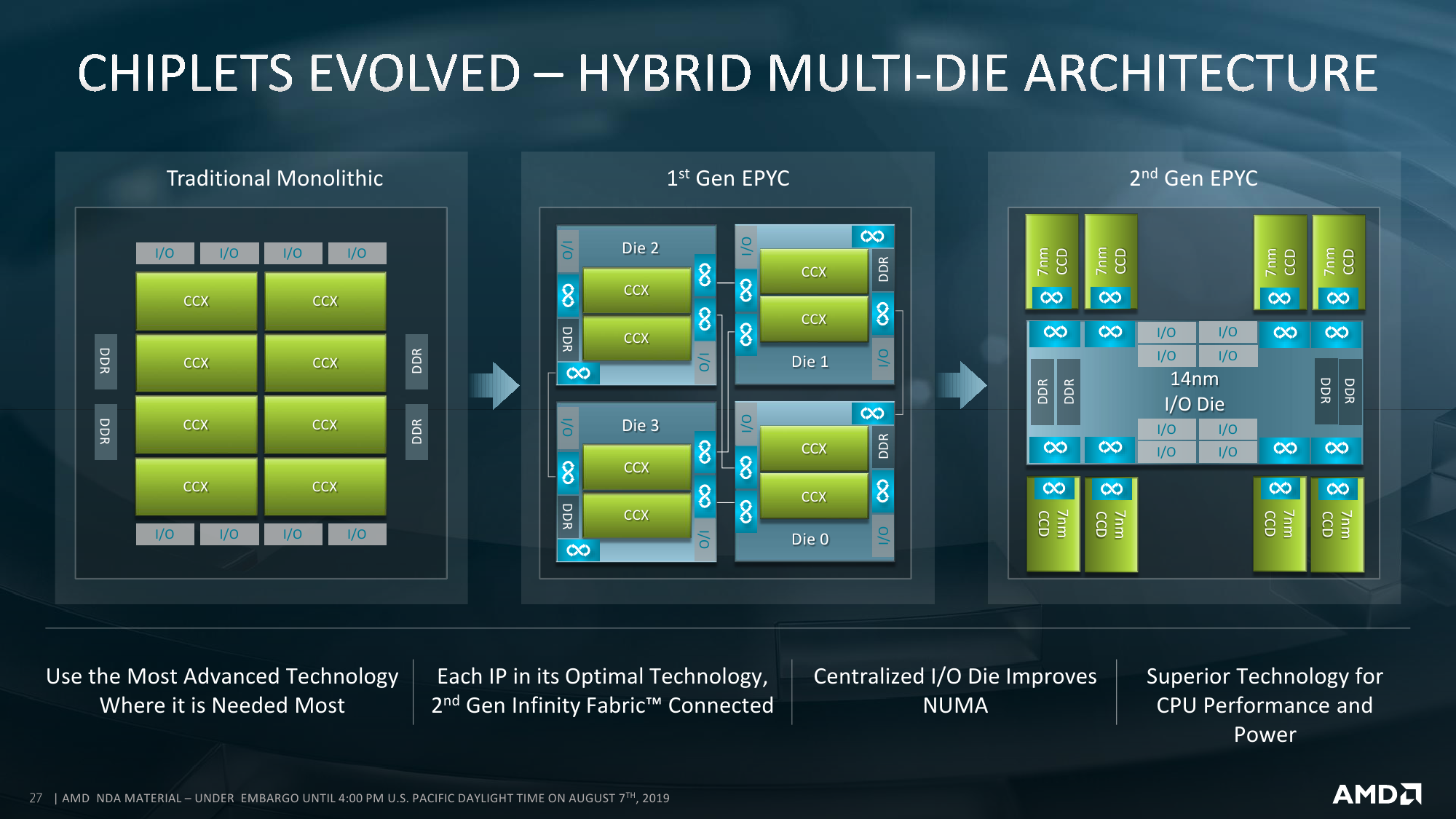
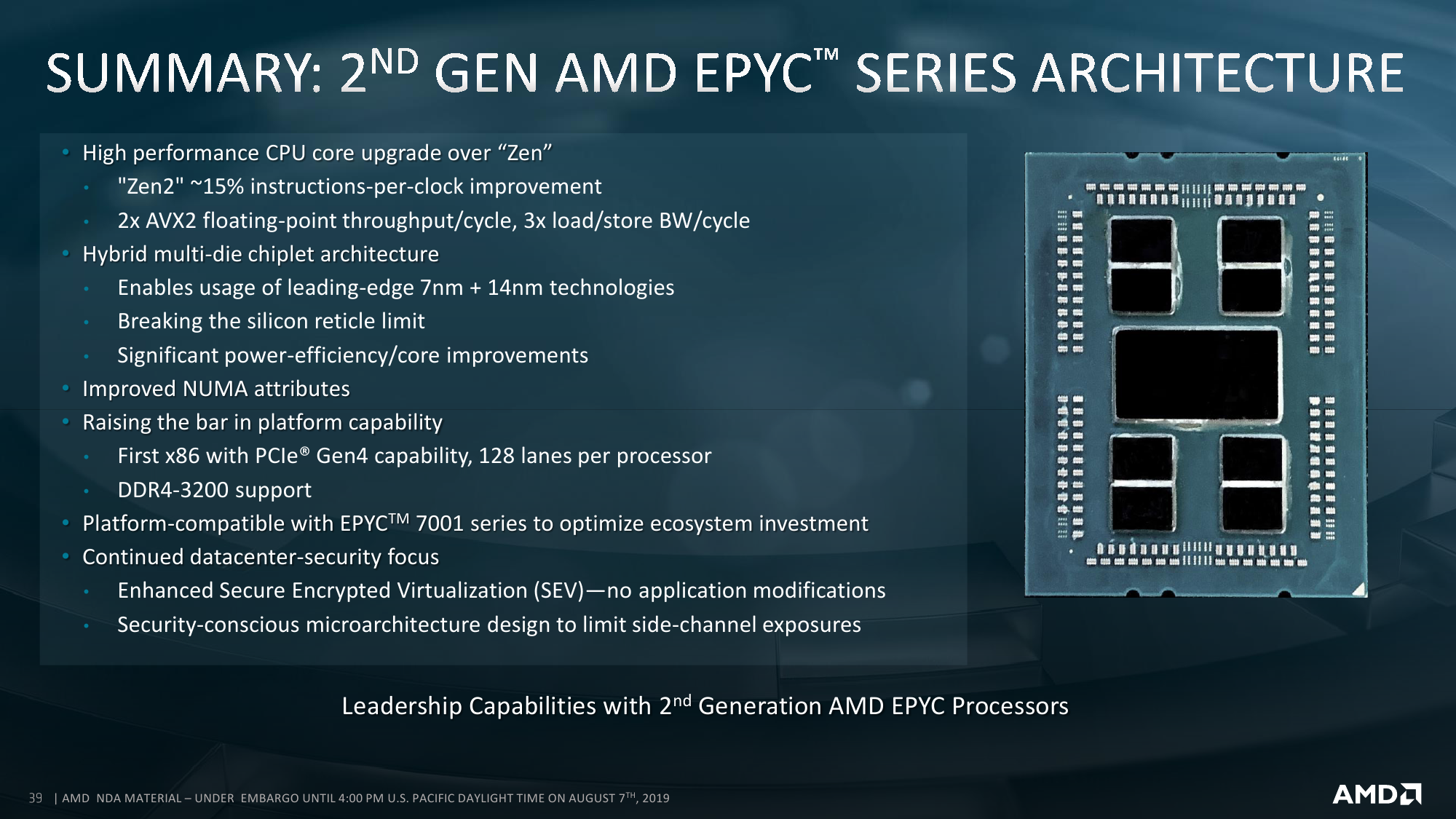
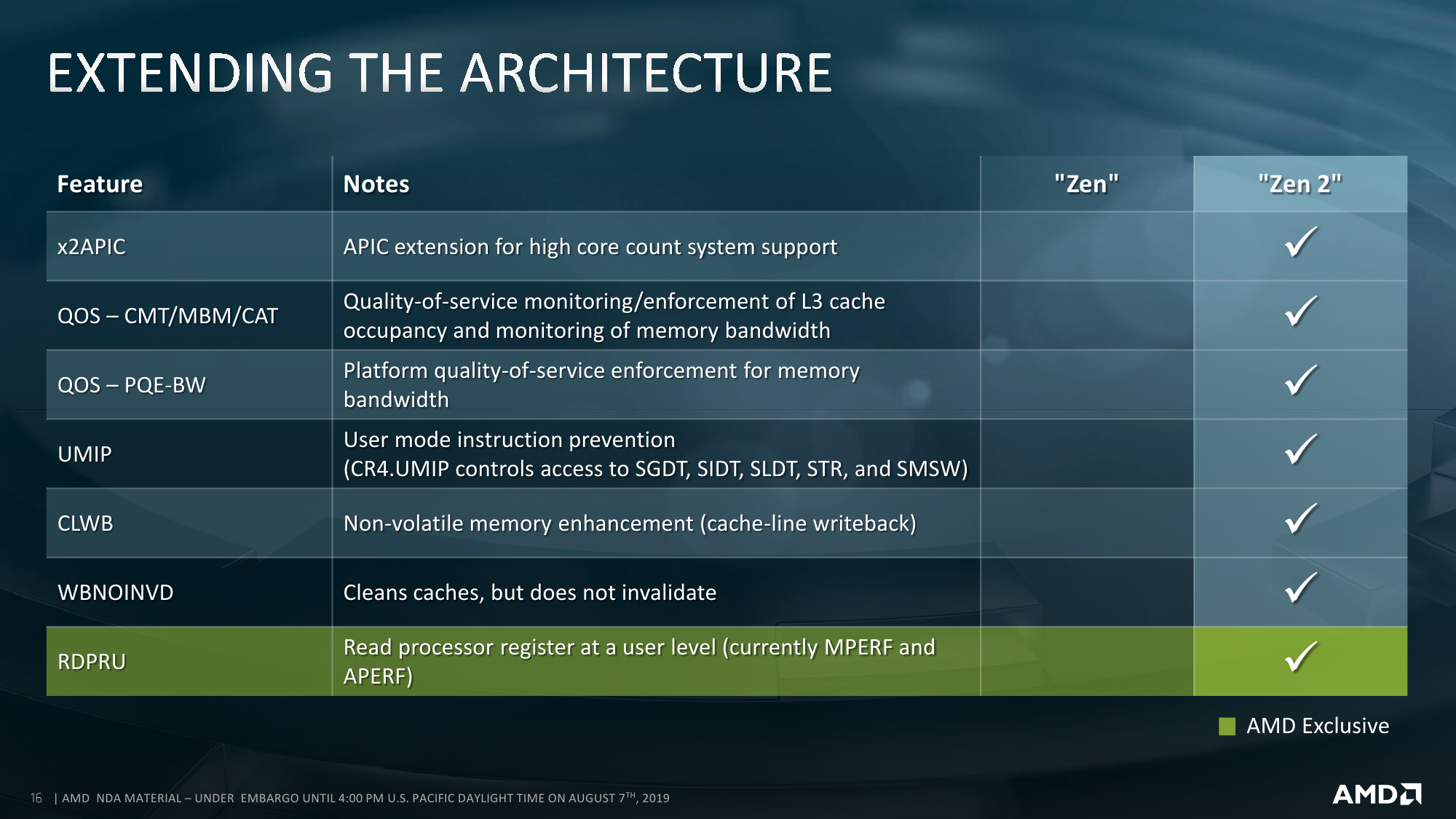
Про внутреннее строение новых ядер всё прекрасно расписано в обзоре микроархитектуры Zen2. На более высоком уровне строение тоже принципиально не отличается — мультичип процессора набирается из тех же CCD, то есть блоков с ядрами и L3-кешем. Исключительно количественное отличие в том, что в CCD может быть восемь ядер, то есть в сумме на один сокет приходится до 64 ядер. То есть в двух сокетах мы получаем до 128 ядер и до 256 потоков. Любопытный побочный эффект — Windows Server 2019 требует патчи для корректной работы APIC. Без них для двухсокетных систем придётся либо искусственно занижать число ядер, либо использовать CPU с меньшим их числом — до 48.

AMD EPYC Rome

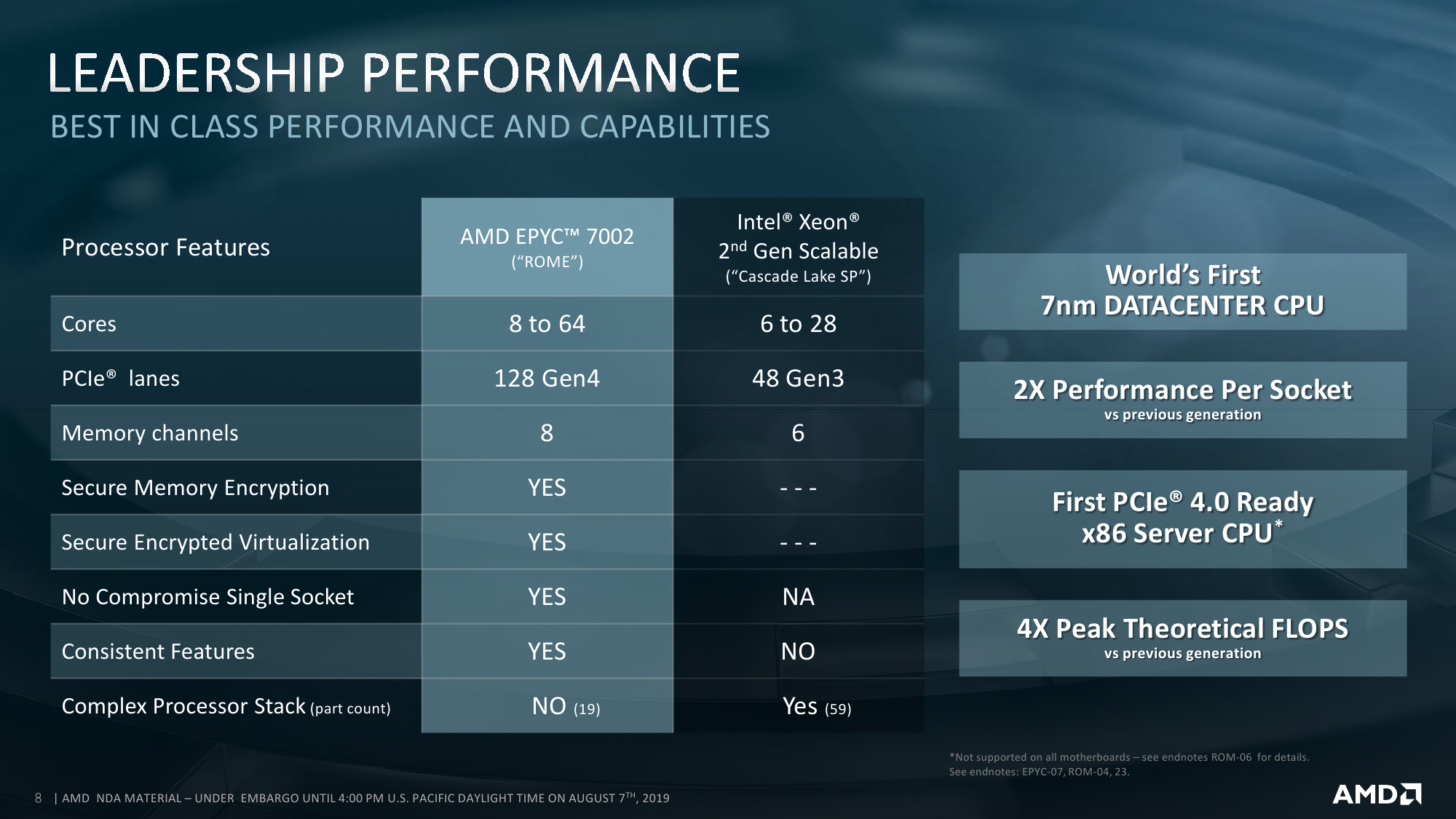
Так или иначе, выбранный подход позволяет более гибко варьировать число ядер в процессоре и системе. Возможны конфигурации как с меньшим числом CCD на процессор, так и с меньшим числом активных ядер в CCD. Бывают варианты на 8, 6, 4 и 2 CCD. Ориентироваться можно на объём L3-кеша, который может достигать объёма 32 Мбайт на CCD: L3-блоки объёмом 16 Мбайт выделяются на каждые четыре ядра. Если часть из этих четырёх ядер отключена, то размер L3 всё равно не меняется. Есть даже экзотические варианты: 8 ядер с максимальной среди всех SKU базовой частотой + 128 Мбайт кеша. Состав I/O Die при этом остаётся единым для всех вариантов: 128 линий PCI-Express 4.0 + 8 каналов памяти DDR4-3200 ECC.
Поддерживаются модули (L)RDIMM и 3DS, вплоть до «восьмиранговых» (2S4R) ёмкостью 256 Гбайт (с 16 Гбит чипами). Из NVDIMM есть только поддержка типа N (по спецификации JEDEC), то есть таких модулей, у которых доступ извне есть только к DRAM, а флеш-массив не виден. AMD рекомендует равномерно заполнять все восемь каналов, не смешивая при этом тип и объём модулей. В принципе, запустить систему можно даже с одним DIMM, но это странная затея сама по себе. При числе модулей меньше восьми, а этот вариант оптимален лишь для CPU с 32 ядрами и менее, рекомендуется размещать их парами буквально наискосок друг от друга относительно I/O Die.

Внутреннюю топологию I/O Die разработчик не раскрывает, говоря лишь о том, что в среднем для всех восьми каналов одного сокета задержка обращения к памяти составляет около 100 нс. Конкретные значения зависят от частот памяти и ядер, типа модулей и сценария доступа. Формально все каналы равны и обеспечивают примерно равные задержки и пропускную способность для всех CCD, но они всё же разбиты на условные пары (“paired” internally) для оптимизации производительности PCI Express и других компонентов. Отдельно стоит отметить, что при использовании двух DIMM на канал максимальная скорость падает с 3200 до 2933 MT/s, а при наборе 3DS-модулями 2S2R/2S4R — до 2666 MT/s. Впрочем, те, кому действительно нужны большие объёмы, это может быть не так критично — для NUMA, например, который тоже улучшился в Rome. К тому же контроллер памяти достаточно умён для того, чтобы оптимальным образом распределять запросы между разными рангами памяти.


Есть и другой ограничитель производительности, даже два. Но первый скучный, так как касается совместимости между платформами EPYC первого и второго поколения. На бумаге всё выглядит гладко — один и тот же Socket P3, полное совпадение по пинам. На практике ставить новый процессор в старую плату не всегда имеет смысл, потому что PCI-E будет работать в режиме 3.0, а скорость памяти не поднимется выше 2667 MT/s. Более того, «штраф» за установку двух DIMM на канал суровей. В лучшем случае будет 2400 MT/s, в худшем — 1866. Обратная совместимость «наборот» — установка старых процессоров в новые платы — в большинство случаев потребует смены BIOS, а часть возможностей Rome может оказаться недоступной.

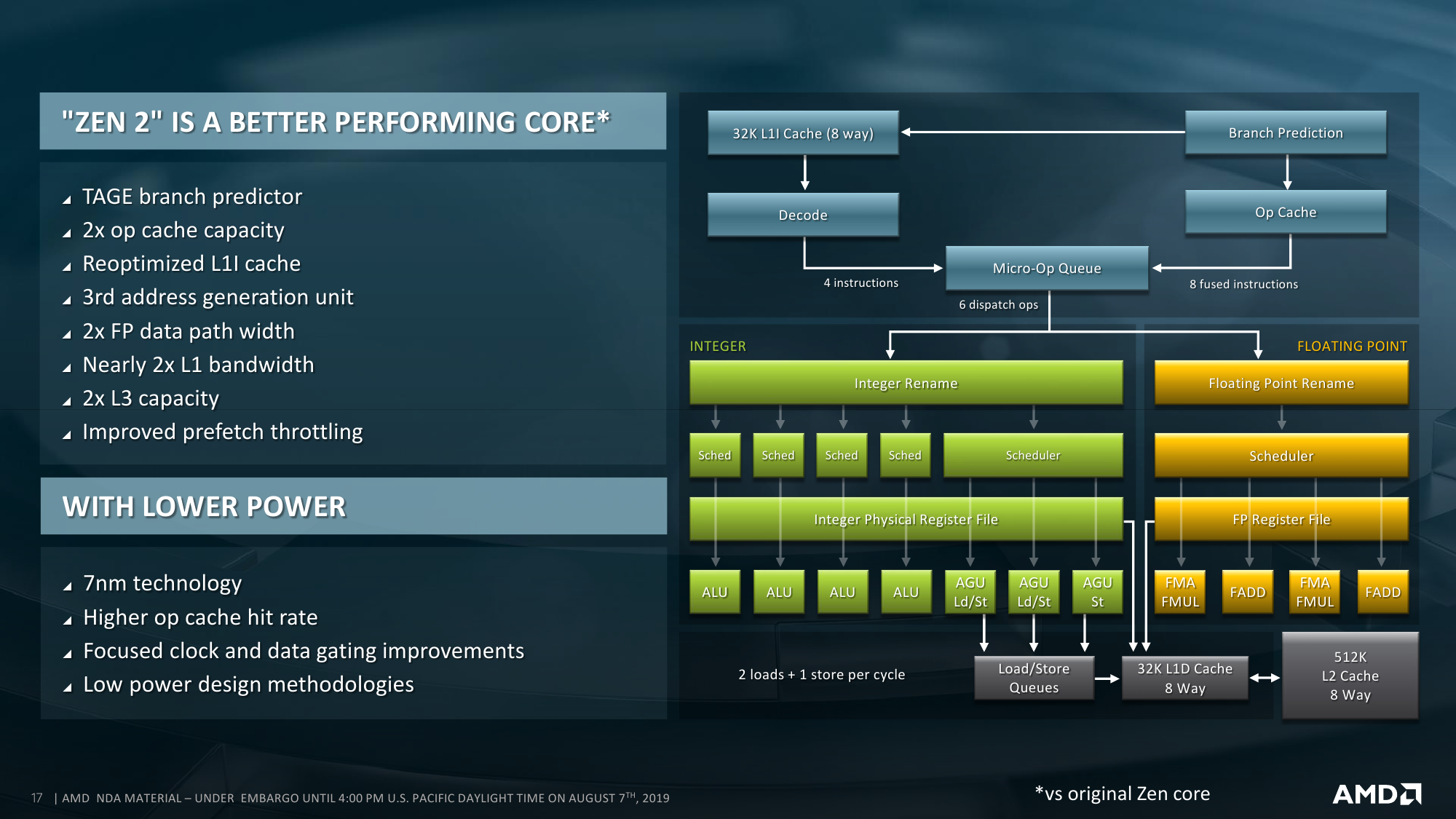
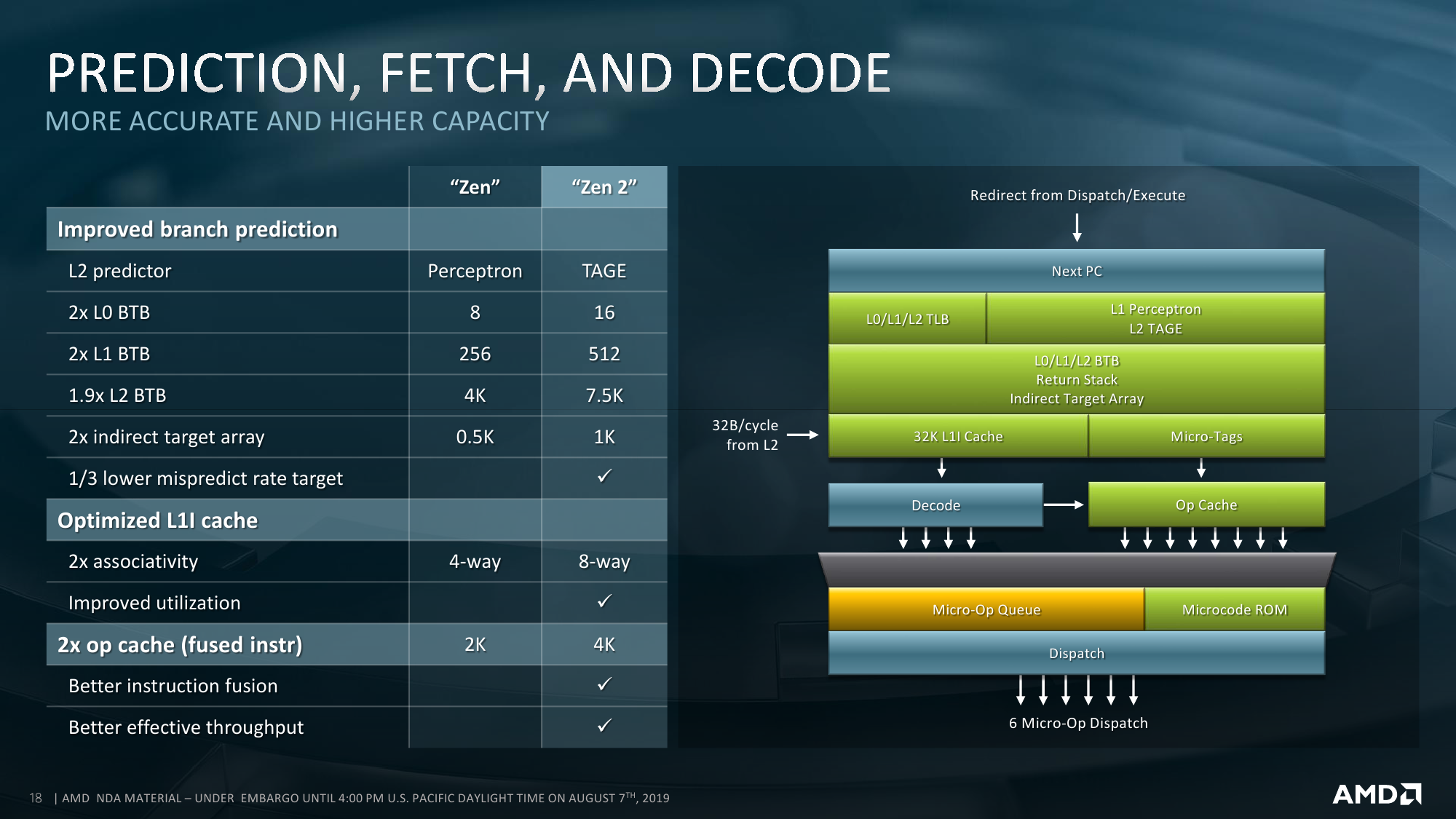
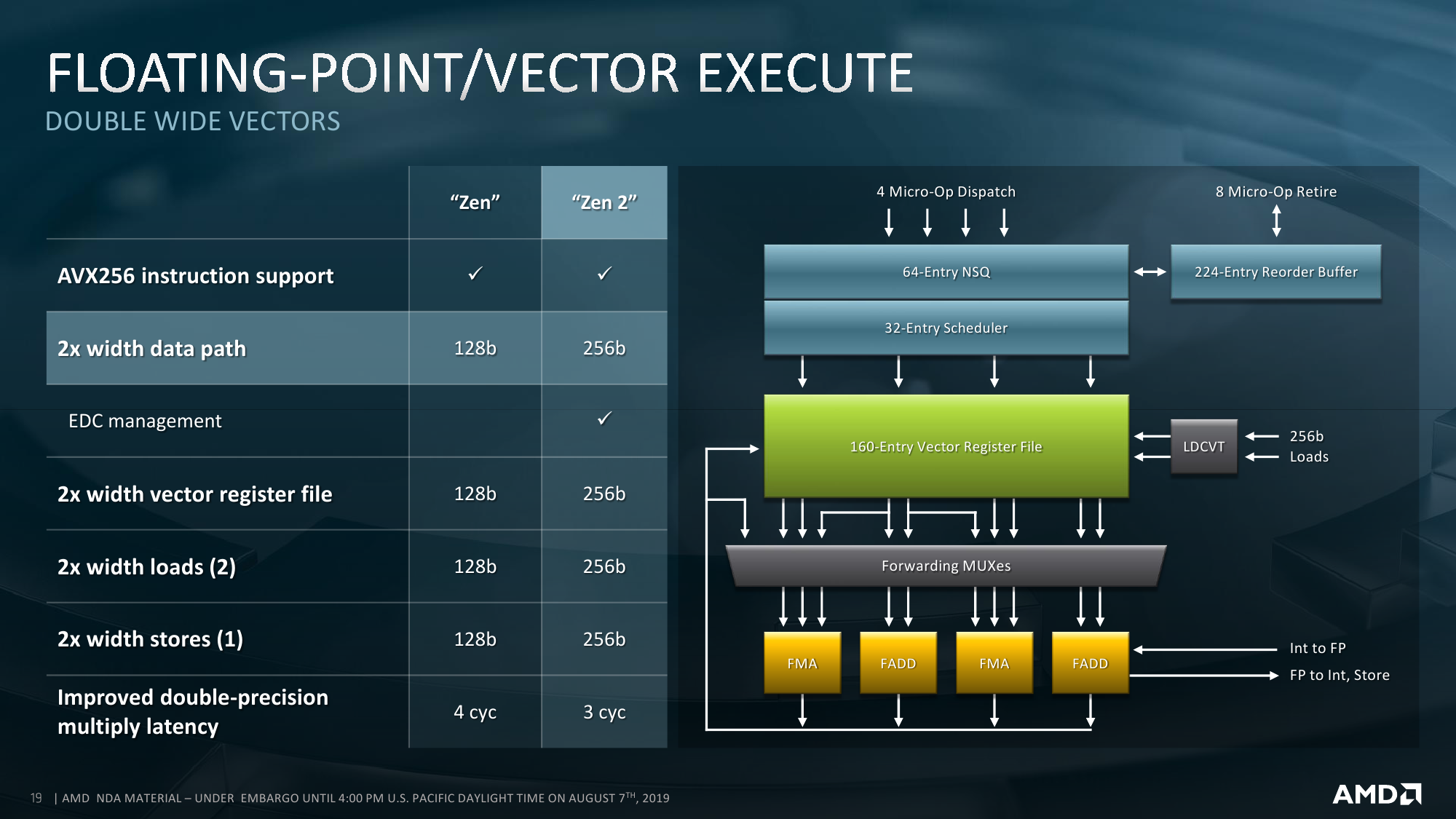
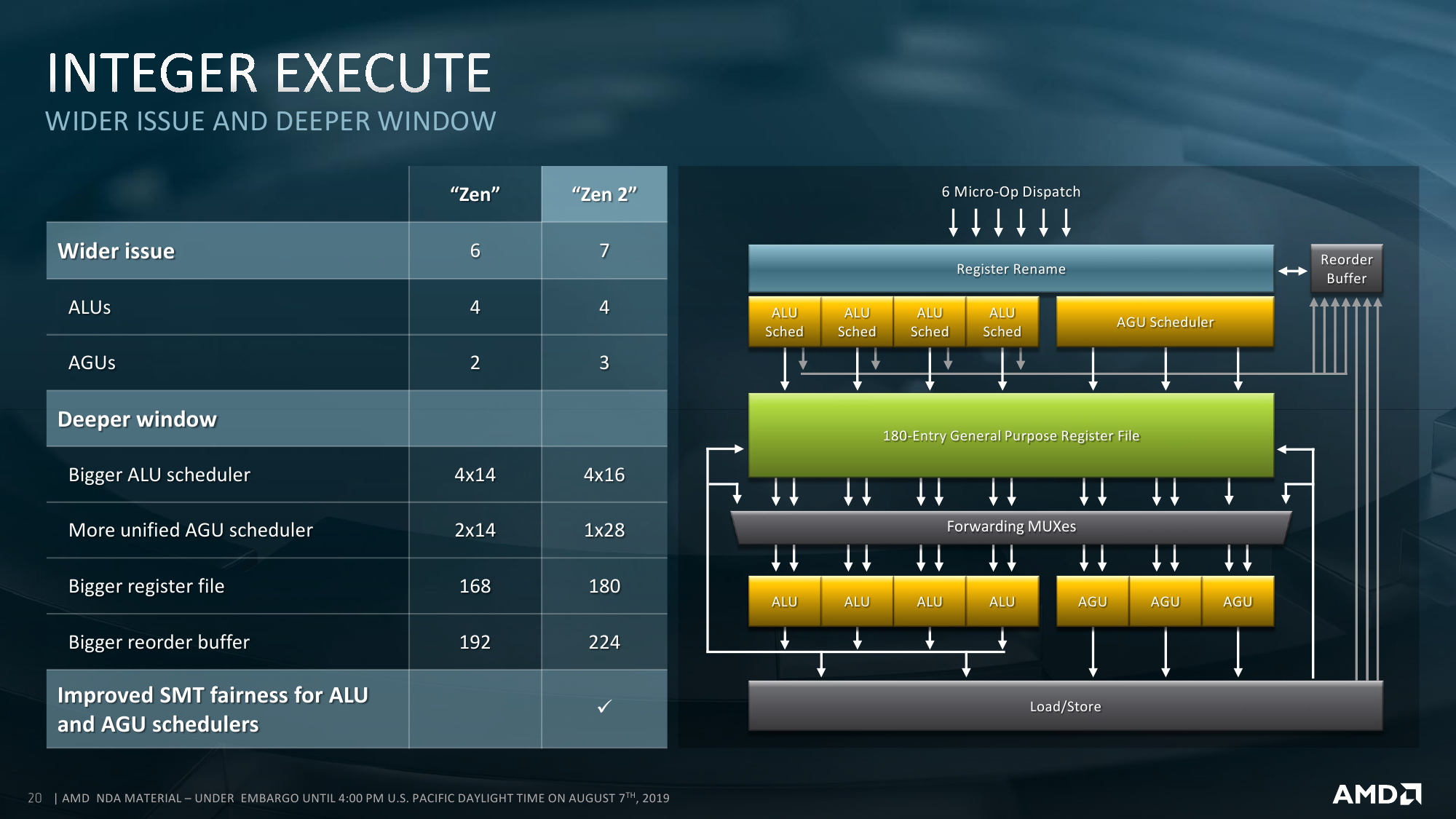
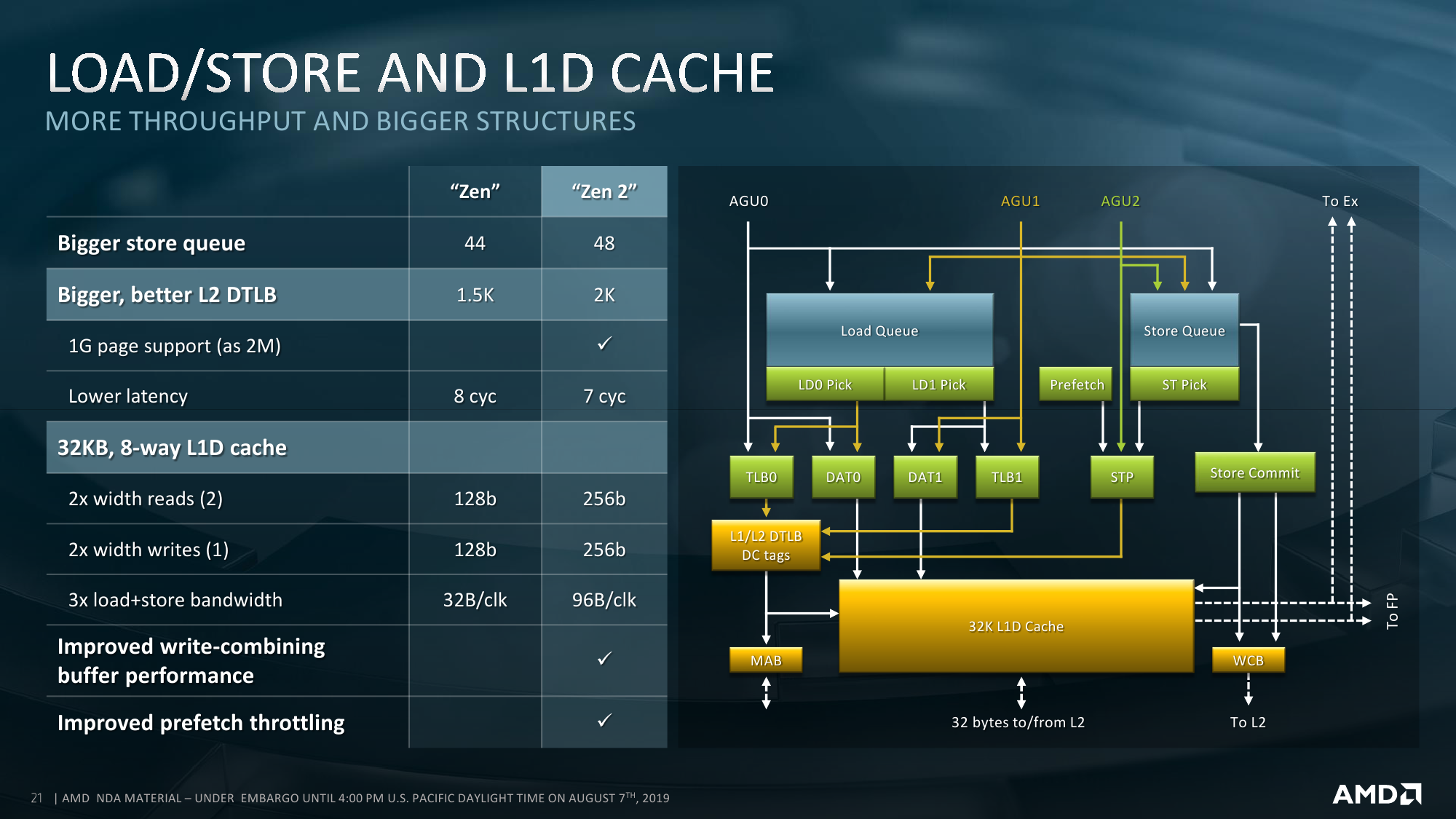


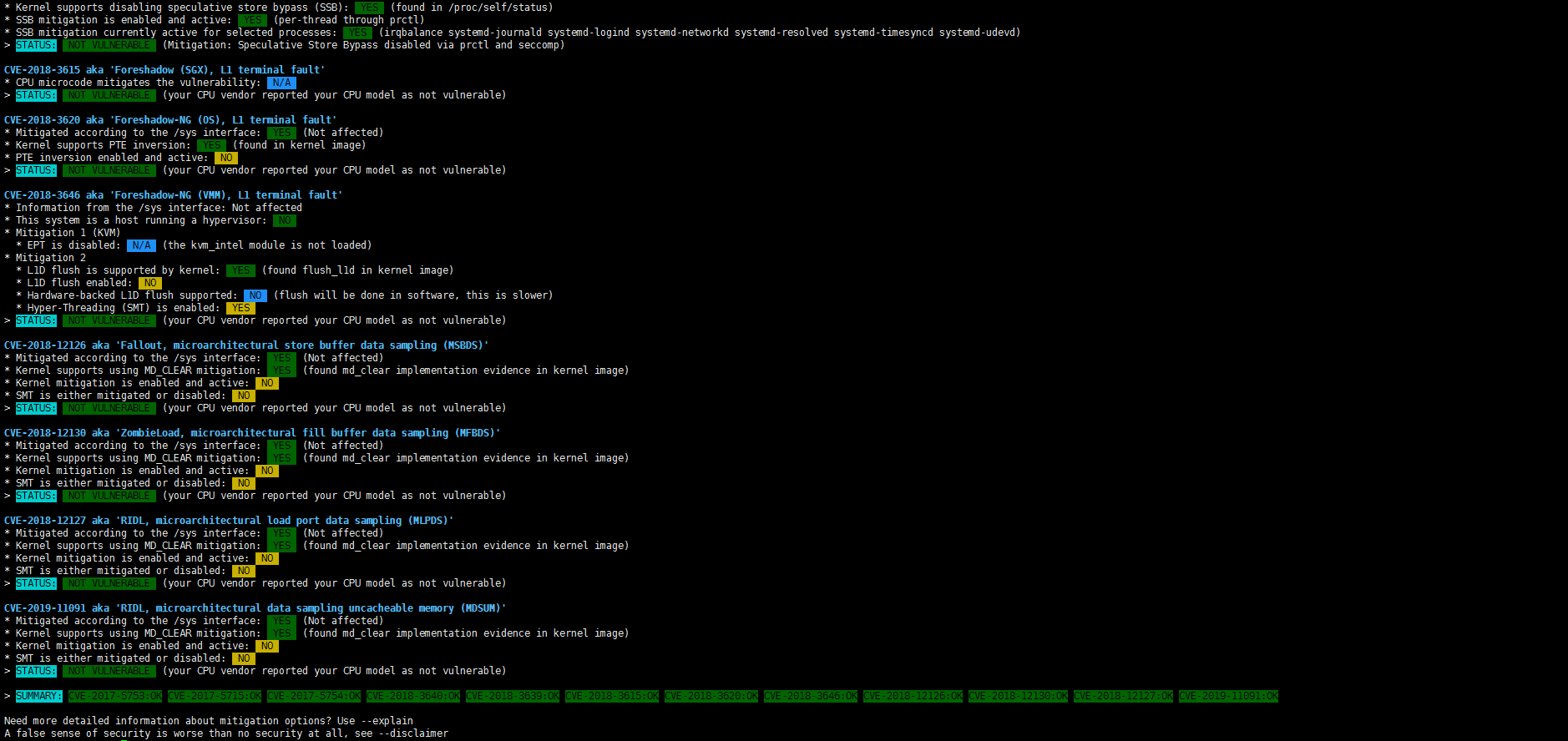
Второй, и самый очевидный, ограничитель — это TDP. В таблице явно не обозначены, но, по словам инженеров, существуют процессоры с двумя базовыми уровнями тепловыделения. При меньшем значении происходит откат к вышеупомянутым характеристикам PCI-E и DDR4 первого поколения EPYC. Данные о TDP непосредственно IO Die не приводятся, но вот этот самый откат может «стоить» и пару десятков Вт, хотя всё очень сильно зависит от параметров всей системы. Для всех моделей указана не просто стандартная величина TDP, а дан диапазон, который может простираться как в сторону увеличения, так и уменьшения. Настроить конкретный уровень можно с точностью до 1 Вт. Чем выше лимит и чем лучше соответственно охлаждение, тем дольше процессор сможет работать на турбочастотах.

С PCI Express ситуация примерно та же, что и была. Да, у нас есть 128 линий PCI-E 4.0 для одного сокета. Да, у нас есть 128 линий PCI-E 4.0 для двух сокетов. Потому что по 64 линии (xGMI) от каждого CPU забирает Infinity Fabric. Все линии процессора разбиты на восемь групп по x16. Каждая группа поддерживают бифуркацию вплоть до x1, но суммарное число слотов на группу не должно быть больше 8. Половина групп также поддерживает переключение 8 линий PCI-E в режим SATA3. В сумме получается до 32 SATA- или NVMe-накопителей x4 на сокет. Чисто технически есть ещё одна, так называемая WAFL-линия x1 для подключения BMC, но она в любом случае занята. Как и прежде, AMD упирает на то, что EPYC это SoC, а не просто процессор, поэтому он может работать без отдельного чипсета и ряда дополнительных компонентов, что должно положительно сказываться на стоимости платформы.


Фактически часть линий всё равно уйдёт на базовые адаптеры и контроллеры, на что в своё время упирала Intel, напоминая как минимум о нормальном сетевом контроллере в собственном чипсете и VROC (Virtual RAID on CPU). С приходом Xeon Scalable добавился ещё один аргумент, хотя и слабый — поддержка Intel Optane DCPMM в DIMM-формате. Однако в Rome всё-таки полновесный PCI-E 4.0, который хоть и считается многими временным, переходным стандартом, всё равно позволит выжать больше даже из меньшего числа линий. Так что для DCPMM вполне может найтись альтернатива из быстрых NVMe SSD вкупе с технологиями ScaleMP. На брифинге по Rome один из докладчиков вскользь упомянул про варианты с большим, чем 128, числом линий PCI-E. Для двухсокетных систем действительно есть возможность получить 192 линии PCI-E. Однако в этом случае часть линий забирается у шины Infinity Fabric, связывающей процессоры, поэтому её производительность будет хуже.

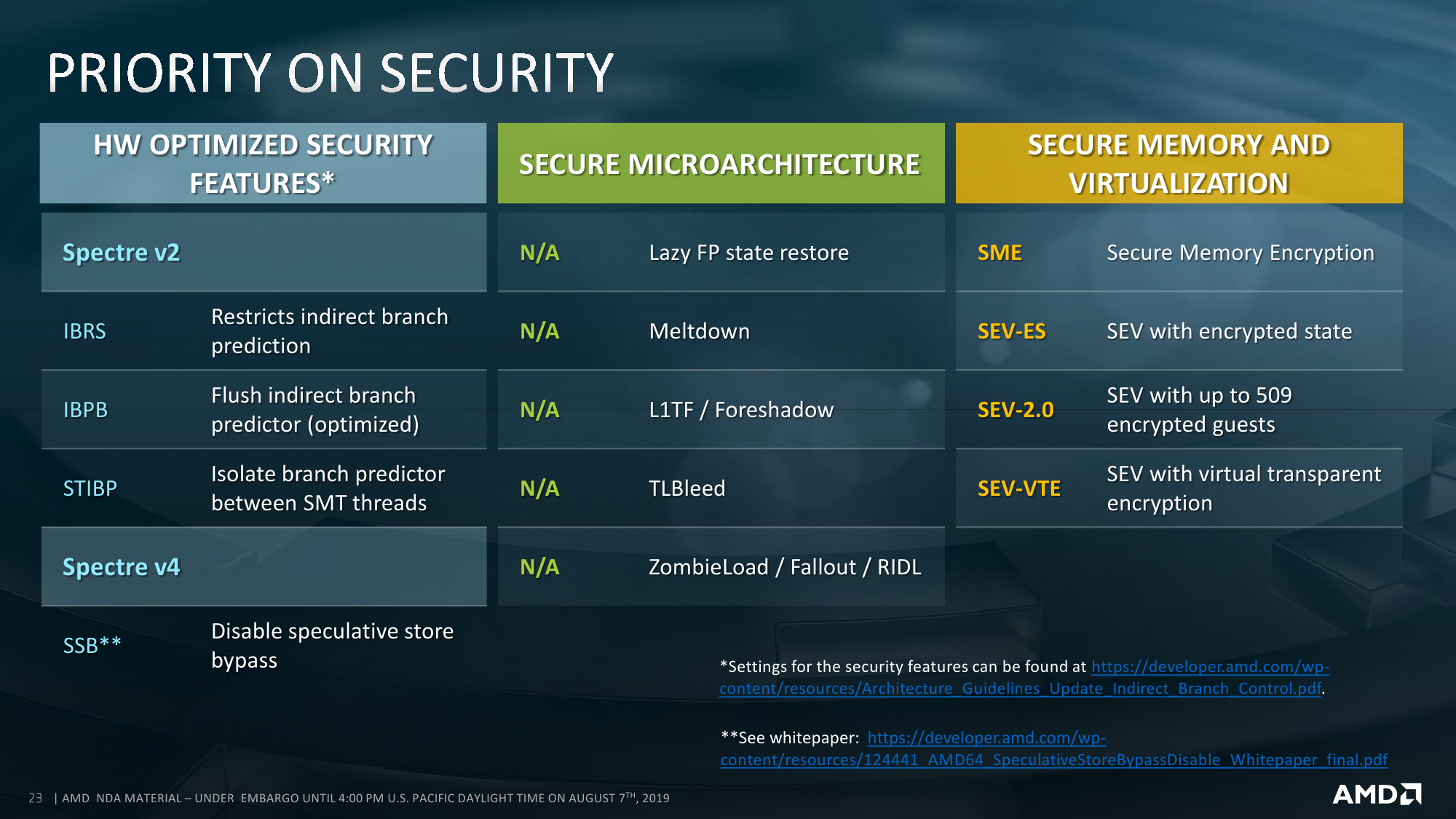
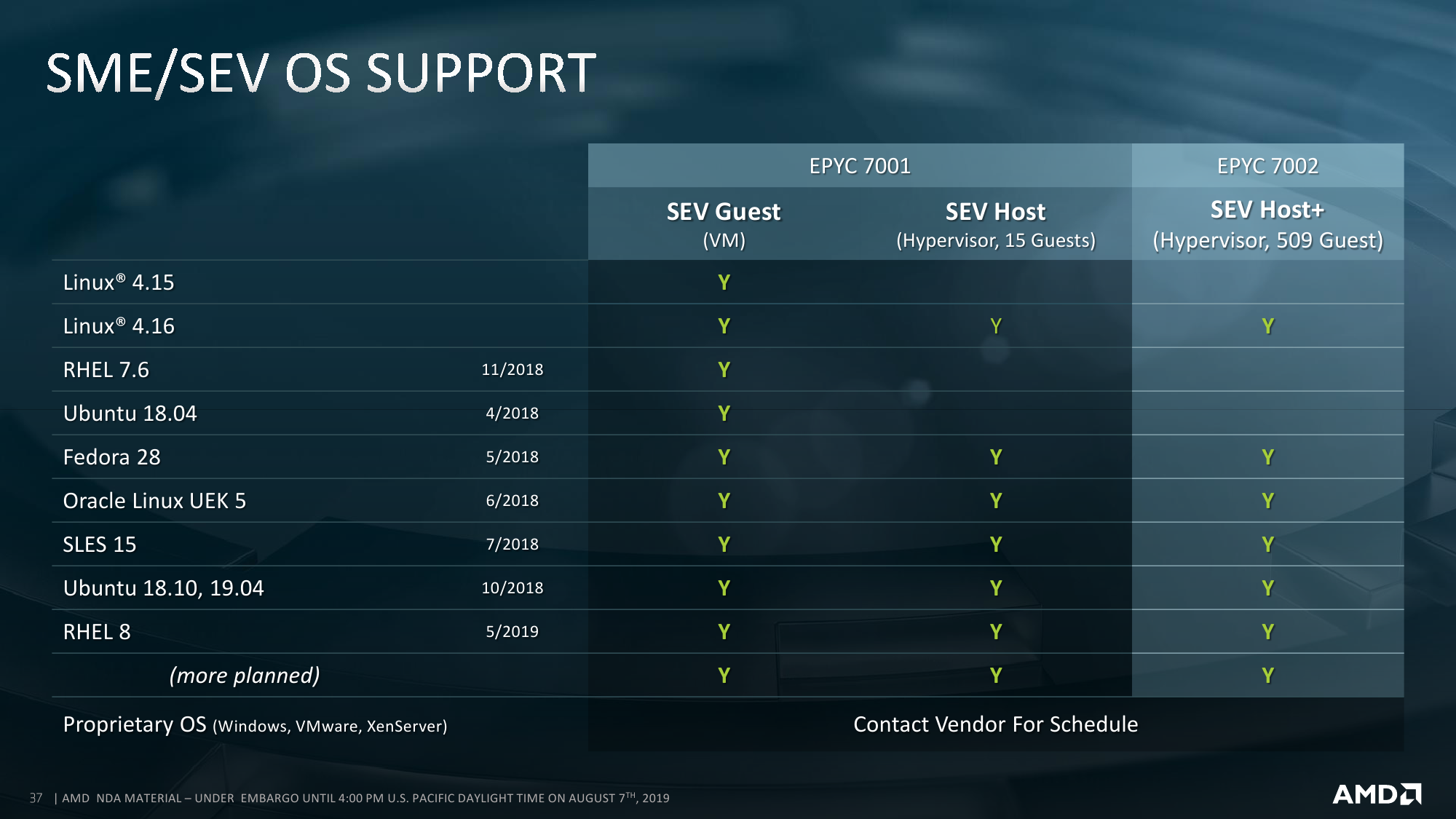
Ещё одно важное обновление — как минимум для виртуализированных и облачных окружений — заключается в расширении возможностей шифрования оперативной памяти по алгоритму AES-128, влияние которого на производительность составляет, как утверждается, менее 1%. В основе всё тот же AMD Secure Processor на базе ARM Cortex-A5, интегрированный непосредственно в CPU. Ключевое отличие от прошлого поколения — увеличение числа ключей шифрования до 509.


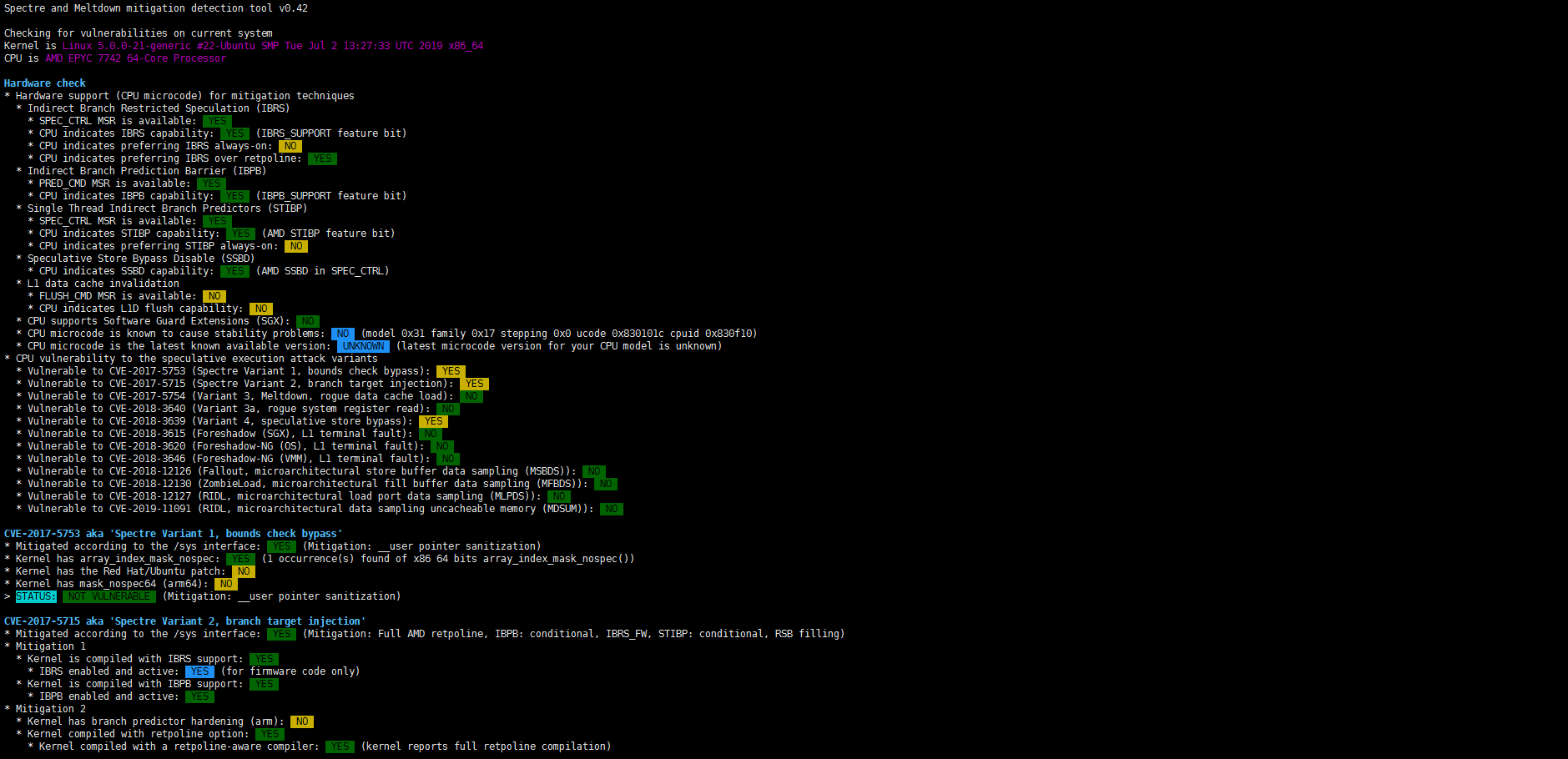
Впрочем, это нужно для защиты с помощью Secure Encrypted Virtualization (SEV), а для простого полного шифрования всей оперативной памяти, то есть функции Secure Memory Encryption (SME), достаточно одного ключа. SEV же позволяет изолировать друг от друга гипервизор, виртуальные машины и контейнеры или их группы, а также отдельные приложения. Однако в последнем случае требуется поддержка со стороны ОС. Особенностью реализации SEV является полная прозрачность, то есть (де-)шифровка на лету, для остальных аппаратных средств, обращающихся к памяти посредством DMA. Помимо прочего, есть и другие обновления касающиеся безопасности и производительности: аппаратные патчи против Spectre, расширенные управление и мониторинг памяти и L3-кеша (вплоть до отдельных CCD), а также некоторые другие инструкции.

На уровне ПО совместимость начинается как минимум с версии ядра Linux 4.19. Ключевые дистрибутивы также поддерживают новые процессоры. Microsoft и VMWare должны подтянуться к выходу на рынок и пока дают бета-версии. С компиляторами ситуация чуть сложнее. Ещё в LLVM Clang 9.0 появилась первичная поддержка оптимизации для ядер Zen 2 (znver2). В GCC полноценная оптимизация ожидается в версии 10 и что-то уже портировано в 9.2, но в репозиториях они появятся не сразу. Что касается собственного оптимизирующего компилятора AMD, то релиз AOCC 2.0, «заточенный» под EPYC, намечен на момент официального анонса.

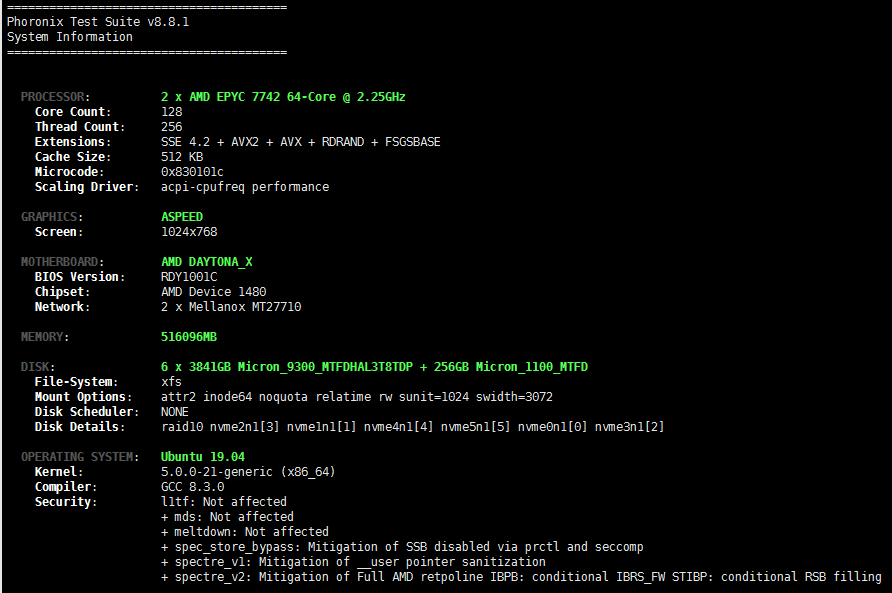
На тестовой системе под кодовым именем Daytona, которая для EPYC Rome произведена Quanta (оригинал ссылки был спешно удалён ещё в прошлом году), использовалось по возможности наиболее общедоступная платформа: Ubuntu 19.04 с ядром 5.0.0-21-generic, компилятор GCC 8.3.0. ОС была установлена на 2,5” SATA SSD Micron 1100 ёмкостью 256 Гбайт. Шесть U.2 NVMe-дисков Micron 9300 объёмом 3,84 Тбайт каждый были собраны в программный md-массив RAID-10. На массиве была создана ФС xfs, смонтированная с параметрами по умолчанию (defaults), а на неё положена директория /var. В неё в свою очередь был установлен Phoronix Test Suite (PTS) текущей стабильной версии 8.8.1, и все тесты работали именно в ней.
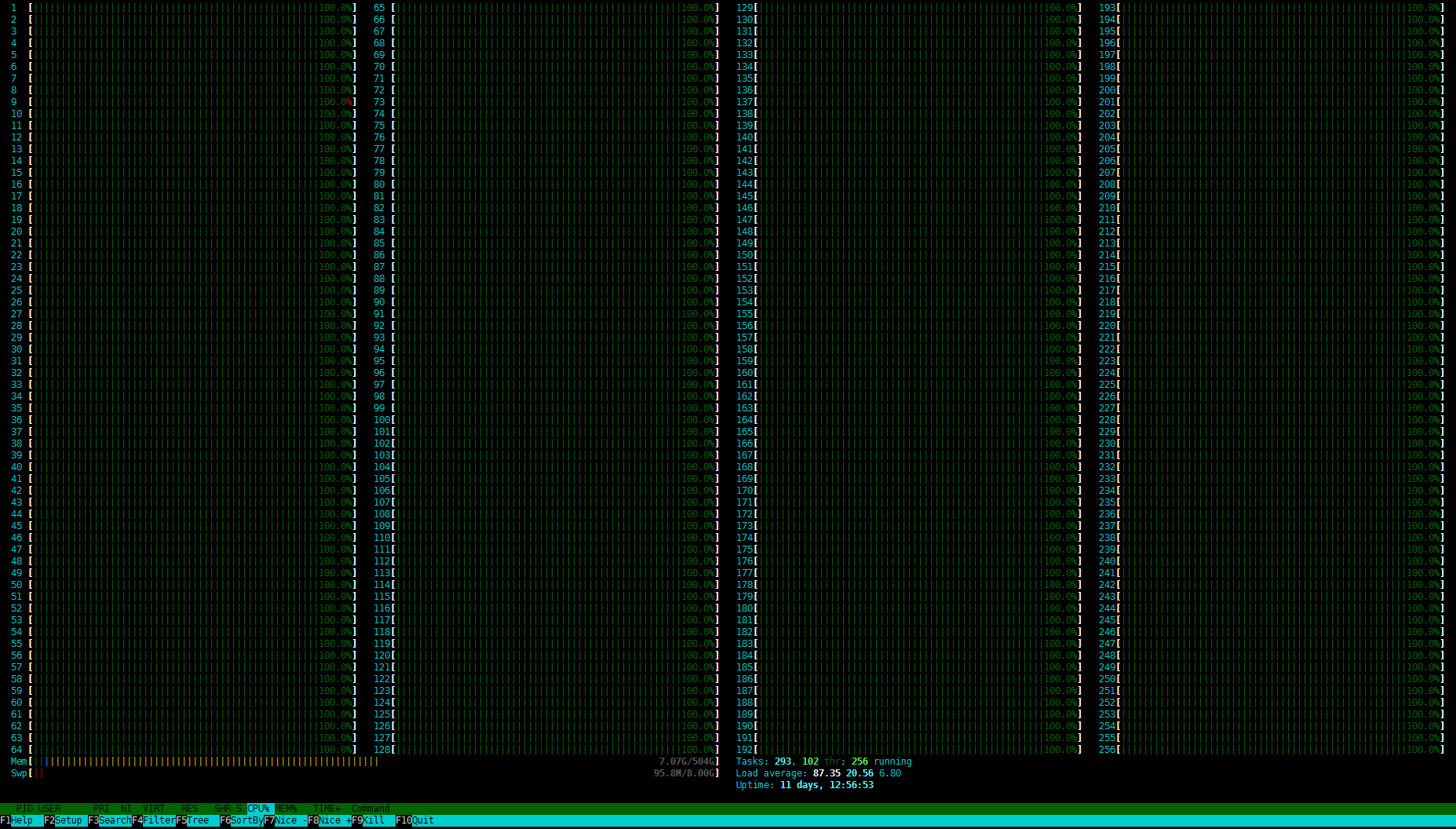
В тестовой системе установлено два процессора AMD EPYC Rome 7742: 64 ядра, 128 потоков, 2,25/3,2 ГГц, L3-кеш 128 Мбайт, TDP выставлен на базовые 225 Вт. Параметр governor для теста был переведён в режим performance. Авторазгон ядер хоть и не совсем корректно детектировался в ОС, всё же работал — те самые 3,2 ГГц на нескольких ядрах можно было увидеть. На каждый из 16 каналов памяти приходился один RDIMM-модуль Micron DDR4-3200 ECC ёмкостью 32 Гбайт, что в сумме даёт 512 Гбайт RAM. Отслеживать энергопотребление и температуры во время тестирования AMD не рекомендовалось, потому что это скорее отладочная платформа. Первый показатель для тестового стенда, пожалуй, не очень важен, а второй нужен лишь для управления системой охлаждения. Впрочем, в нашем случае это всё несущественно, так как физически сервер располагался в Мюнхене.
Что же со всем этим добром делать? Любоваться, не иначе! Дело в том, что конфигурация 2 × 64 ядра, мягко говоря, не средняя. Она ближе к сегменту HPC, а не корпоративным серверам. Сравнивать её попросту не с чем. Если взять те же публично доступные Intel Xeon Platinum 8280(L), то это будет не сравнение, а надругательство. Непубличные Cascade Lake AP серии 9200 Intel предоставить отказалась, но с ними всё равно сравнить цены не получилось бы, так как доступны они только в виде готовых систем тех же HPC-платформ. Сама AMD предоставить систему 32-ядерными Rome пока что тоже не смогла, равно как и систему с EPYC 7601 первого поколения.
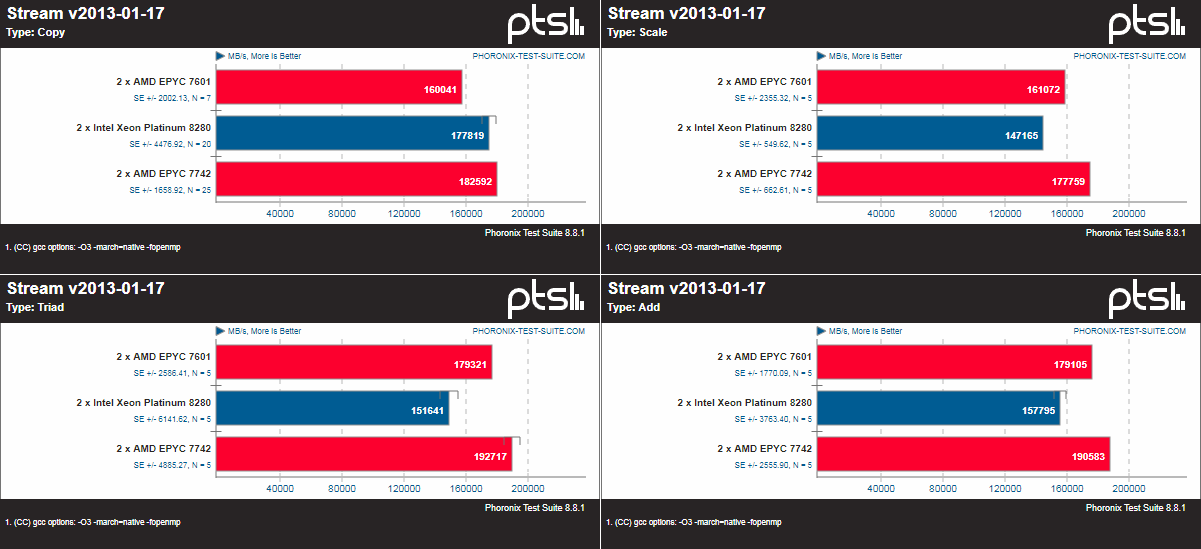
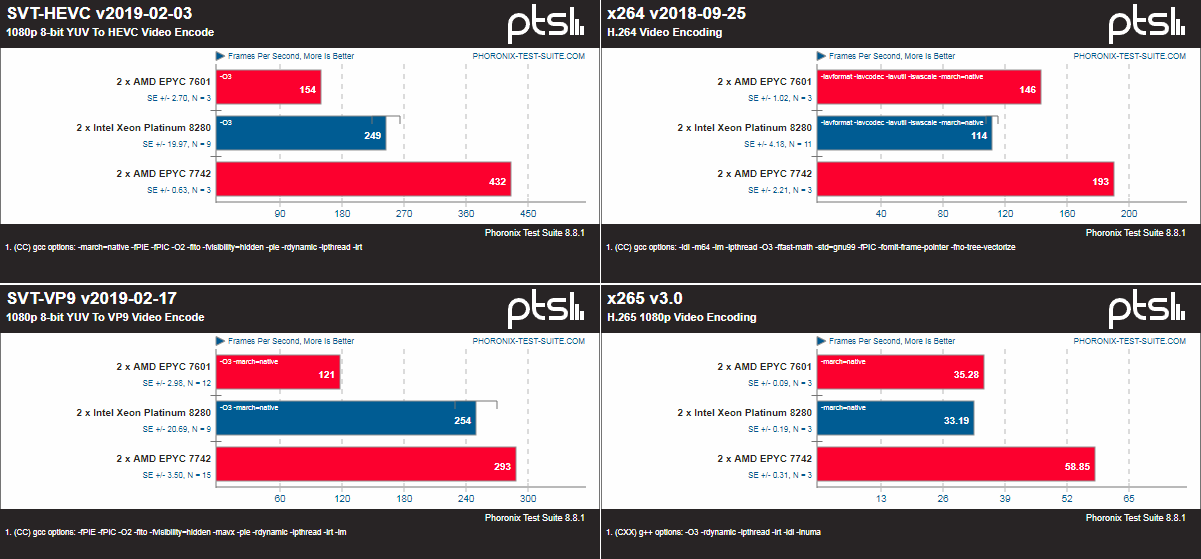
Поэтому в качестве временного решения приведены некоторые сравнения результатов EPYC 7742 с публично доступными тестами Xeon 8280 от Phoronix, которые дают возможность примерной оценки соотношения сил. Результаты тестовой платформы доступны здесь. Обратите внимание, что системы отличаются по железу и ПО. Впрочем, показатели тестовой системы практически идентичны результатам внутренних бенчмарков самой AMD, которые, увы, публиковать нельзя. Да и соотношение с конкурентами примерно то же. Отдельно стоит отметить, что, как всегда, многое зависит от оптимизации. Например, тот же Stream показывает значительно более высокие результаты благодаря только «правильному» компилятору AOCC.
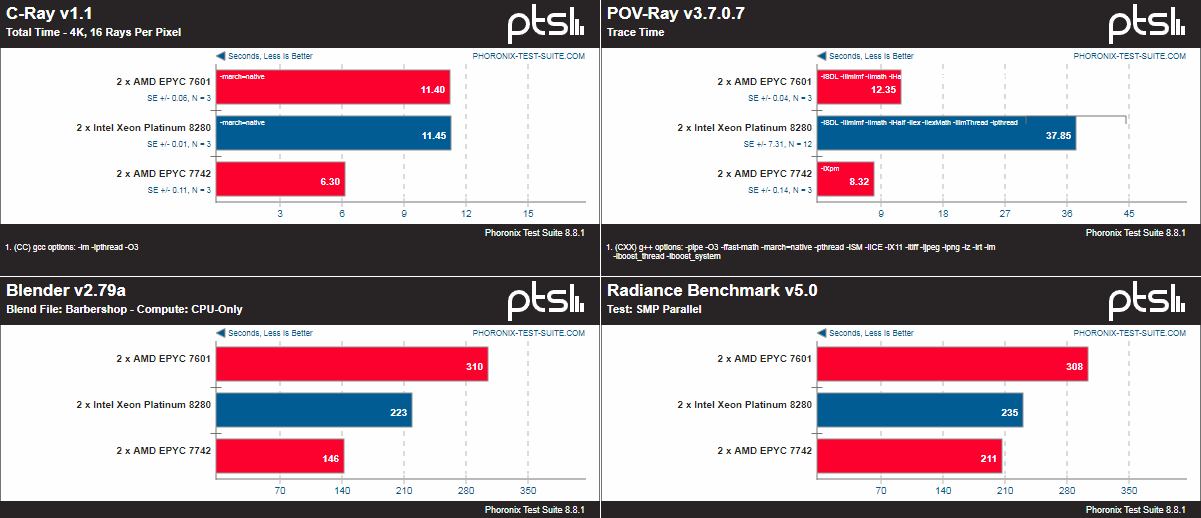
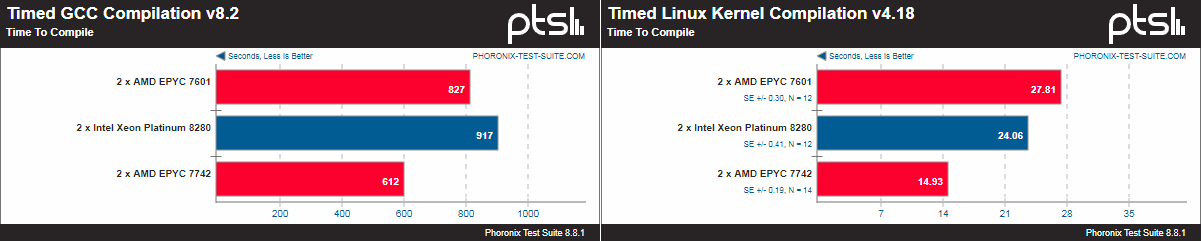

Да, EPYC 7742 зачастую выигрывает просто за счёт числа ядер. И тем более интересно будет взглянуть на 32-ядерные модели. Прямо сейчас есть только одна, но очень важная неизвестная — цена для партнёров компании. Либо AMD захочет всё-таки неплохо заработать на новинках, либо продолжит давление на конкурента. На это у неё, надо полагать, есть около года-полутора. Слегка неожиданный анонс Cooper Lake может удержать производителей от поползновений в сторону конкурента просто потому, что серверный рынок достаточно инертен. Но полностью от них не избавит. Основным фокусом должно стать выстраивание экосистемы ПО, его перенос и адаптация к новой аппаратной платформе. Фундамент для неё готов, ведь всё-таки есть что-то неуловимо приятное в сообщении очередного бенчмарка о подозрительно быстром завершении теста: мол, не может же такого быть. Может! Теперь может.
Продолжение следует…
P.S: если у вас есть пожелания по бенчмаркам (консольных, для Linux), оставляйте их в комментариях.
P.P.S.: чтобы не пропустить новые материалы, подписывайтесь на нас в Я.Дзен, Telegram, Twitter и LinkedIn.

