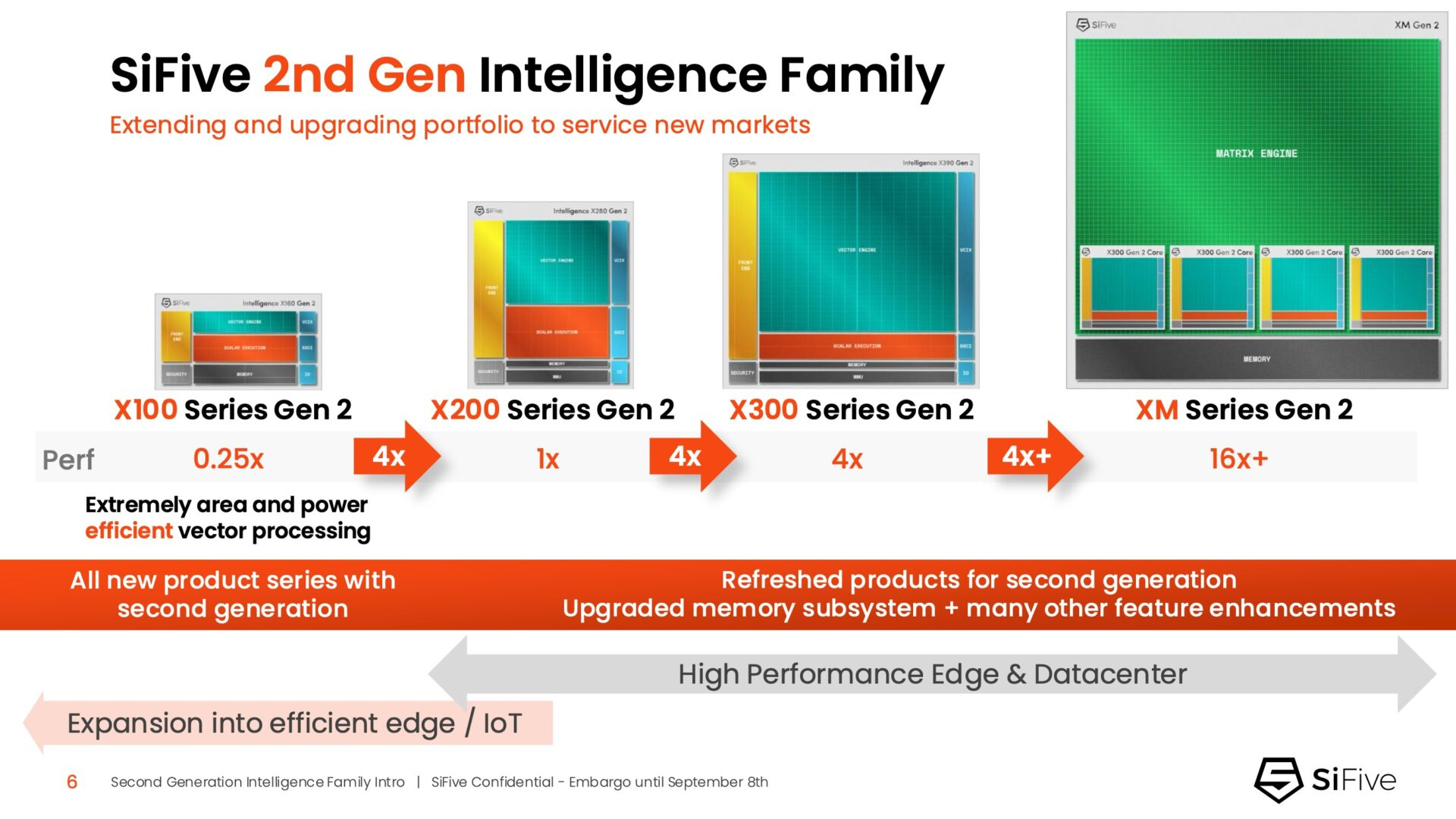
SiFive представила семейство ядер Intelligent второго поколения с архитектурой RISC-V, включающее новые ядра X160 Gen 2 и X180 Gen 2, а также обновлённые решения X280 Gen 2, X390 Gen 2 и XM Gen 2. Новые решения разработаны для расширения возможностей скалярной, векторной и, в случае серии XM, матричной обработки данных, адаптированных для современных задач в сфере ИИ.
Как отметил ресурс EE Times, анонсируя новую линейку продуктов, SiFive стремится воспользоваться быстрорастущим спросом на решения для обработки ИИ-нагрузок, который, по прогнозам Deloitte, вырастет как минимум на 20 % во всех технологических средах, включая впечатляющий скачок на 78 % в сфере периферийных вычислений с использованием ИИ.
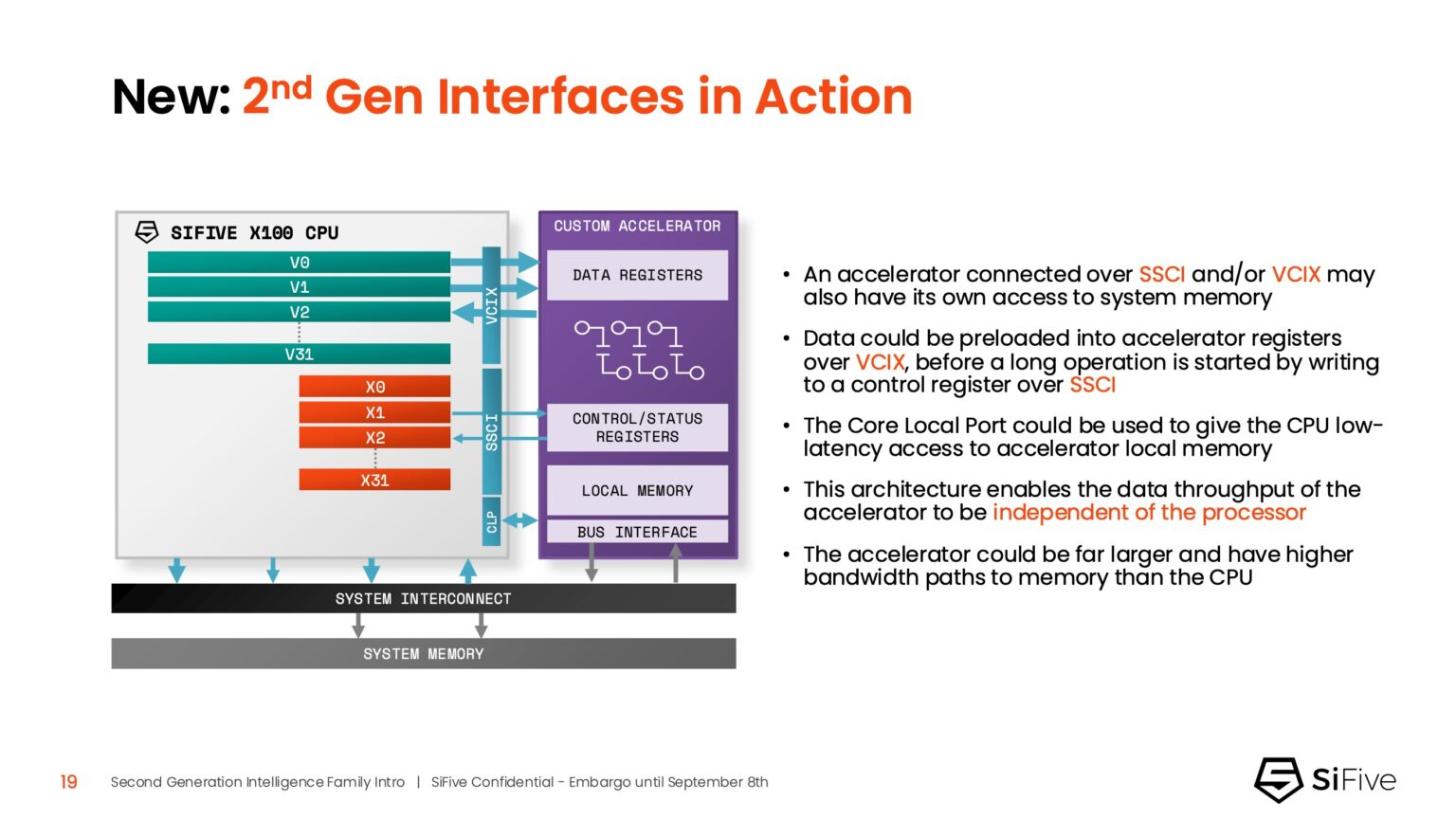
Ядра SiFive второго поколения позволяют решать критически важные задачи в области внедрения ИИ, в частности, в области управления памятью и ускорения нелинейных функций. Ключевым нововведением в процессорах серии X является их способность функционировать в качестве блока управления ускорителем (ACU). Это позволяет ядрам SiFive обеспечивать основные функции управления и поддержки для ускорителя заказчика через интерфейсы SiFive Scalar Coprocessor Interface (SSCI) и Vector Coprocessor Interface eXtension (VCIX). Данная архитектура позволяет заказчикам сосредоточиться на инновациях в обработке данных на уровне платформы, оптимизируя программный стек.
Источник изображений: SiFive/ServeTheHome
Джон Симпсон (John Simpson), главный архитектор SiFive, сообщил ресурсу EE Times, что интеллектуальные ядра SiFive обеспечивают гибкость, сокращают трафик системной шины за счёт локальной обработки на чипе ускорителя и обеспечивают более тесную связь для задач пред- и постобработки. Он рассказал, что SiFive представила два важных усовершенствования в архитектуре, которые напрямую устраняют узкие места производительности: устойчивость к задержкам памяти и более эффективную подсистему памяти.
Функцию Memory Latency Tolerance позволяет снизить задержку загрузки. Симпсон рассказал, что блок скалярных вычислений, обрабатывающий все инструкции, отправляет векторные инструкции в очередь векторных команд (VCQ). При обнаружении такого инструкции одновременно отправляется запрос в подсистему памяти (кеш L2 или выше). Ранняя отправка запросов, отделённая от исполнения, позволяет быстрее получить ответ от памяти и поместить его в переупорядочиваемую настраиваемую очередь загрузки векторных данных (VLDQ). Это гарантирует готовность данных к моменту, когда инструкция в конечном итоге покинет VCQ, что приводит к «загрузке вектора в течение одного цикла».
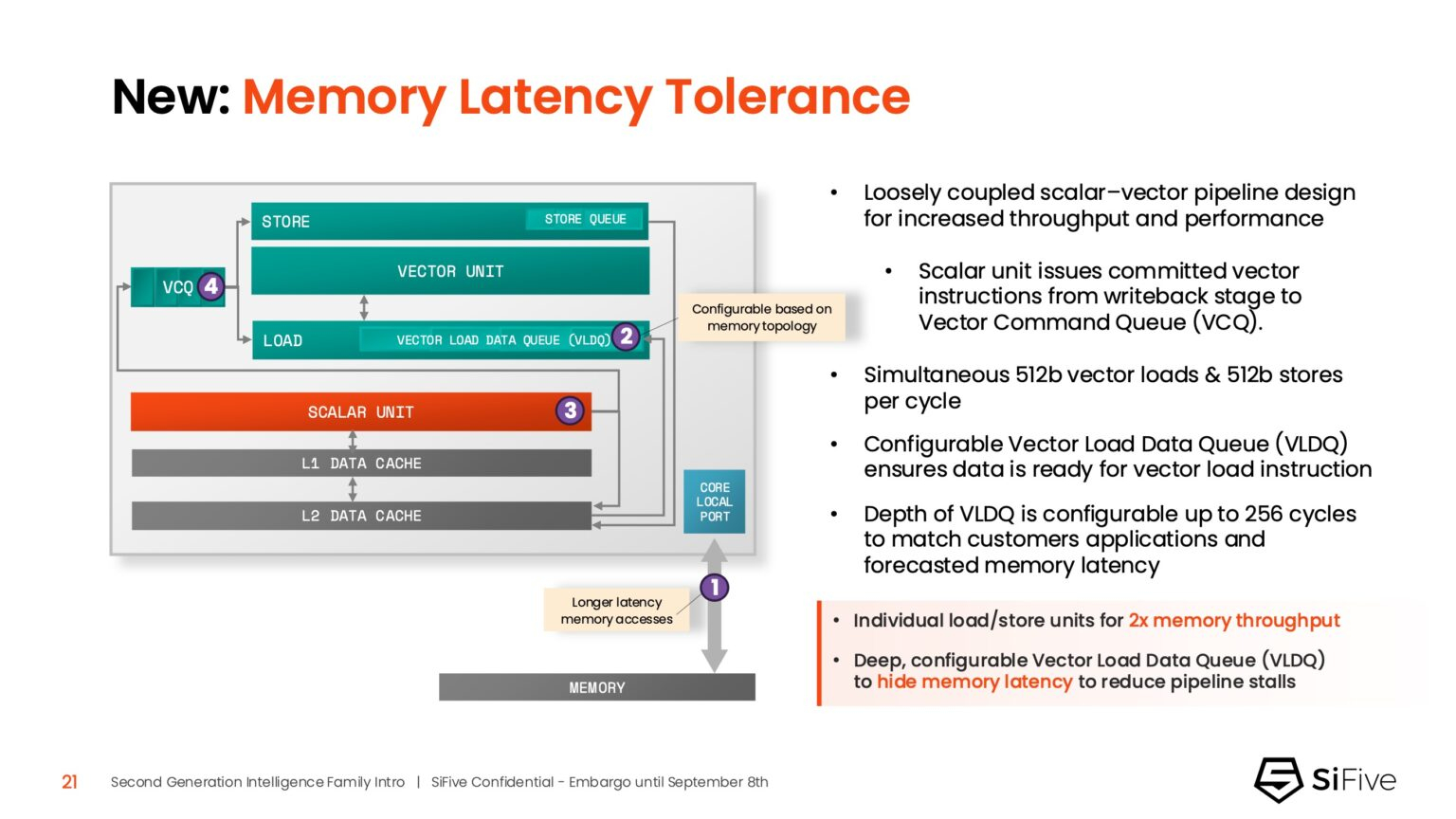
Симпсон подчеркнул конкурентное преимущество решения, отметив: «Xeon, представленный на Hot Chips, может обслуживать 128 невыполненных запросов, и это топовый показатель для Xeon, а в нашем четырёхъядерном процессоре этот показатель составляет 1024». Эта «прекрасная технология» обеспечивает непрерывную обработку данных, эффективно предотвращая простои конвейера.

Более эффективная подсистема памяти, которая представляет собой ещё одно существенное обновление, основана на переходе от инклюзивной к неинклюзивной иерархии кешей. В инклюзивной системе кеширования предыдущего поколения данные из общего кеша L3 реплицировались в частные кеши L1/L2, что компания посчитала неэффективным расходом «кремния». Конструкция ядер второго поколения исключает копирование, что, по словам Симпсона, даёт «в 1,5 раза большую производительность по сравнению с первым поколением» при меньшей занимаемой площади на кристалле.
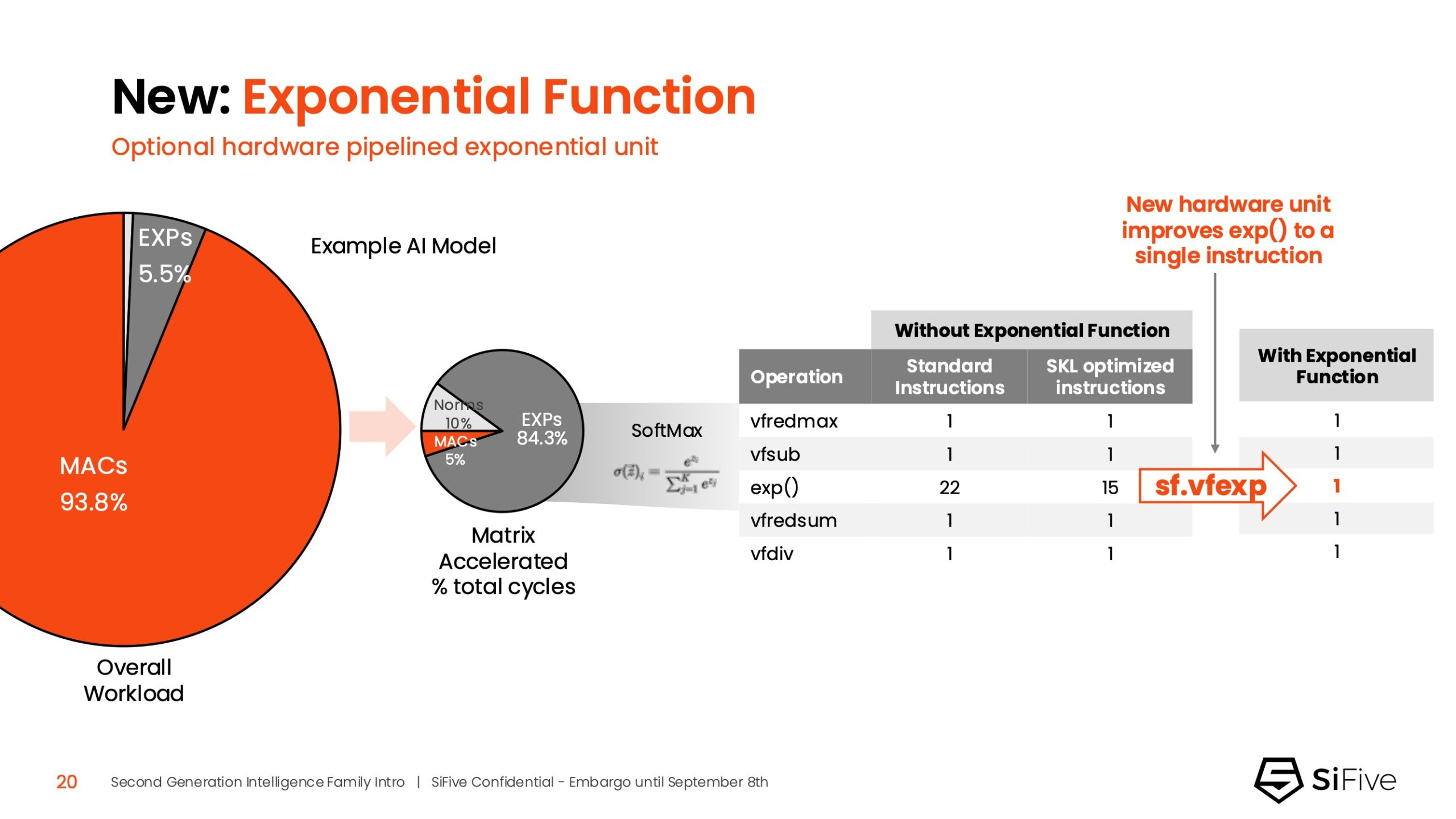
SiFive также интегрировала новый аппаратный конвейерный экспоненциальный блок. В то время как MAC-операции доминируют в рабочих ИИ-нагрузках, возведение в степень становится следующим серьёзным узким местом. Например, в BERT LLM, ускоренных матричным движком, операции softmax, включающие возведение в степень, занимают более 50 % оставшихся циклов. Программными оптимизациями SiFive сократила выполнение функции возведения в степень с 22 до 15 циклов, а новый аппаратный блок сокращает её до одной инструкции, уменьшая общее время выполнения функции до пяти циклов.
Программный стек для семейства Intelligence второго поколения поддерживает масштабируемость. В серии XM среда выполнения машинного обучения уже распределяет рабочие нагрузки между несколькими кластерами XM на одном кристалле. Впрочем, пока масштабирование за пределы одного кристалла требует дальнейшей разработки библиотеки межпроцессорного взаимодействия (IPC).

Флагманские решения X160 Gen 2 и X180 Gen 2 могут быть настроены для работы под управлением операционной системы реального времени, пишет SiliconANGLE. 32-бит IP-ядро Intelligence X160 разработано для оптимизации энергоэффективности и приложений с жесткими ограничениями по площади кристалла, в то время как 64-бит IP-ядро Intelligence X180 обеспечивает более высокую производительность и лучшую интеграцию с более крупными подсистемами памяти, сообщил ресурс CNX-Software.

X160 поставляется с кеш-памятью объёмом до 200 КиБ и памятью объёмом 2 МиБ. Помимо промышленного оборудования, ядро может найти применение в потребительских устройствах, таких как фитнес-трекеры. Кроме того, X160 можно установить в системах с несколькими ИИ-ускорителями для управления чипами и предотвращения изменения прошивки. Благодаря двум встроенным кешам общей ёмкостью более 4 МиБ ядро позволяет работать с большим объёмом данных. По данным SiFive, X160 подходит для обучения ИИ-моделей и использования в оборудовании ЦОД.

В свою очередь, ядро X280 ориентировано на потребительские устройства, такие как гарнитуры дополненной реальности, а X390 также может использоваться в автомобилях и инфраструктурных системах. Последнее ядро выполняет векторную обработку в четыре раза быстрее, чем X280.

Все пять продуктов Intelligence Gen 2 уже доступны для лицензирования, а появление первых чипов на их основе ожидается во II квартале 2026 года. SiFive сообщила, что два ведущих американских производителя полупроводников лицензировали новую серию X100 ещё до её публичного анонса. Они используют IP-ядро X100 в двух различных сценариях: одна компания задействует сочетание скалярного векторного ядра SiFive с матричным движком, выступающим в качестве блока управления ускорителем, а вторая использует векторный движок в качестве автономного ИИ-ускорителя.
Источники:

