Материалы по тегу: mosaicml
|
04.07.2023 [17:20], Владимир Мироненко
Обойдёмся без NVIDIA: MosaicML перенесла обучение ИИ на ускорители AMD Instinct MI250 без модификации кодаРазработчик решений в области генеративного ИИ MosaicML, недавно перешедший в собственность Databricks, сообщил о хороших результатах в обучении больших языковых моделей (LLM) с использованием ускорителей AMD Instinct MI250 и собственной платформы. Компания рассказала, что подыскивает от имени своих клиентов новое «железо» для машинного обучения, поскольку NVIDIA в настоящее время не в состоянии обеспечить своими ускорителями всех желающих. MosaicML пояснила, что требования к таким чипам просты:

Источник изображений: MosaicML Как отметила компания, ни один из чипов до настоящего времени смог полностью удовлетворить все требования MosaicML. Однако с выходом обновлённых версий фреймворка PyTorch 2.0 и платформы ROCm 5.4+ ситуация изменилась — обучение LLM стало возможным на ускорителях AMD Instinct MI250 без изменений кода при использовании её стека LLM Foundry. 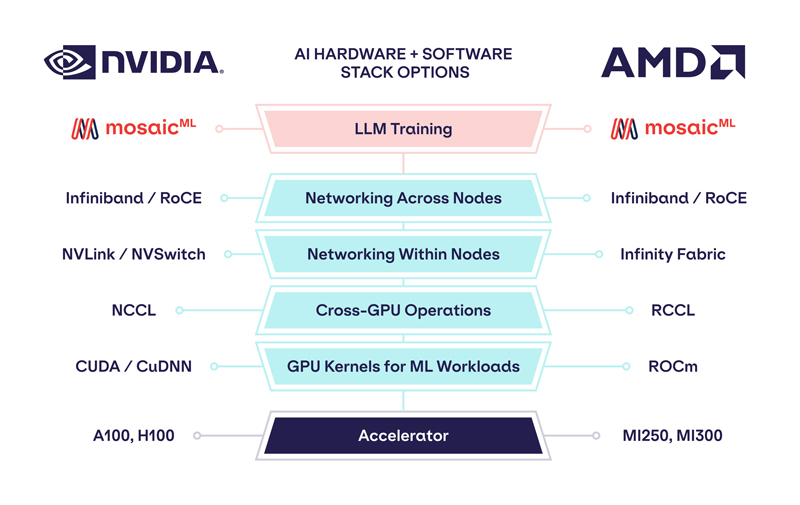 Некоторые основные моменты:
При этом никаких изменений в коде не потребовалось. 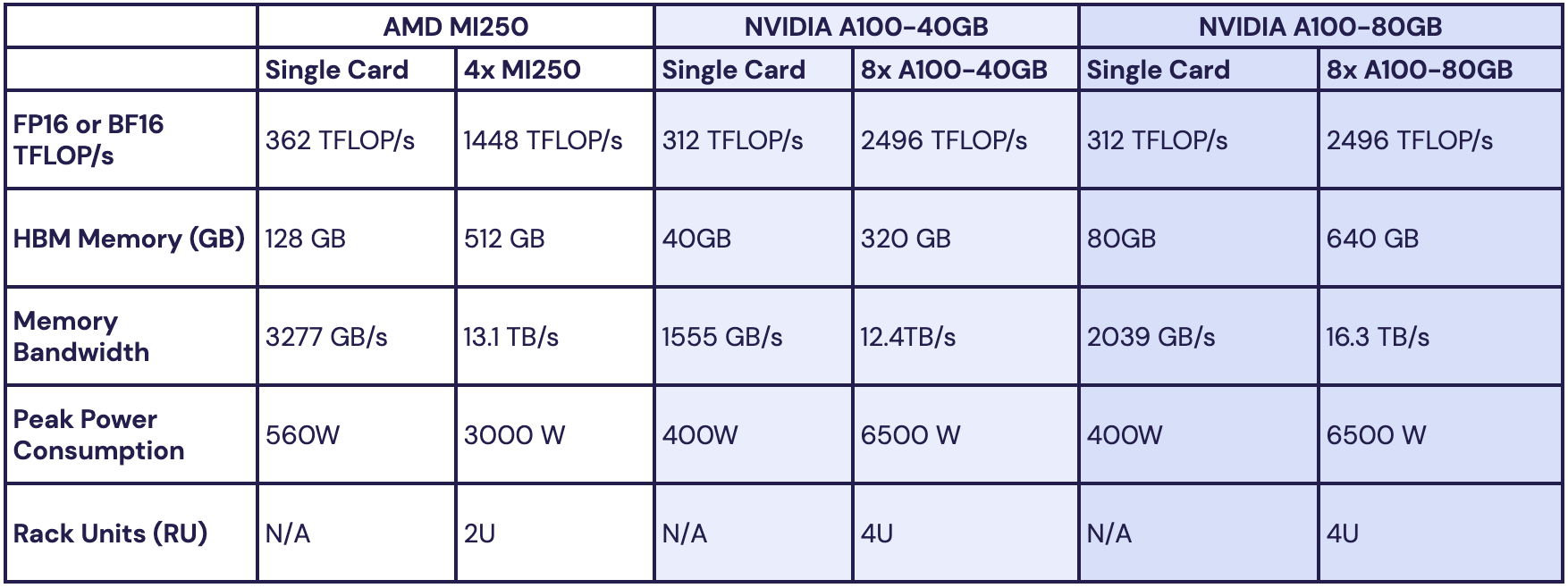 Все результаты получены на одном узле из четырёх MI250, но компания работает с гиперскейлерами для проверки возможностей обучения на более крупных кластерах AMD Instinct. «В целом наши первоначальные тесты показали, что AMD создала эффективный и простой в использовании программно-аппаратный стек, который может конкурировать с NVIDIA», — сообщила MosaicML. Это важный шаг в борьбе с доминирующим положением NVIDIA на рынке ИИ. |
|

