Google Cloud объявила о масштабном обновлении программно-аппаратного стека AI Hypercomputer, а также о новых инстансах на базе передовых ускорителей NVIDIA, пишет ресурс SiliconANGLE. Также компания представила обновлённую инфраструктуру хранения данных для рабочих нагрузок ИИ, базовое ПО для запуска моделей и более гибкие варианты использования ресурсов.
Компания объявила о доступности TPU v5p в GKE, что позволит клиентам обучать и обслуживать ИИ-модели, работающие в крупномасштабных кластерах TPU. В качестве альтернативы клиенты также смогут использовать ускорители NVIDIA H100 в составе инстансов A3. Одним из основных преимуществ нового подсемейства A3 Mega является поддержка конфиденциальных вычислений. В Google подчеркнули важность этой функции, поскольку обработка чувствительных данных в облаке считалась слишком рискованной из-за возможной утечки. Google Cloud пообещала предоставить клиентам ускорители NVIDIA Blackwell.
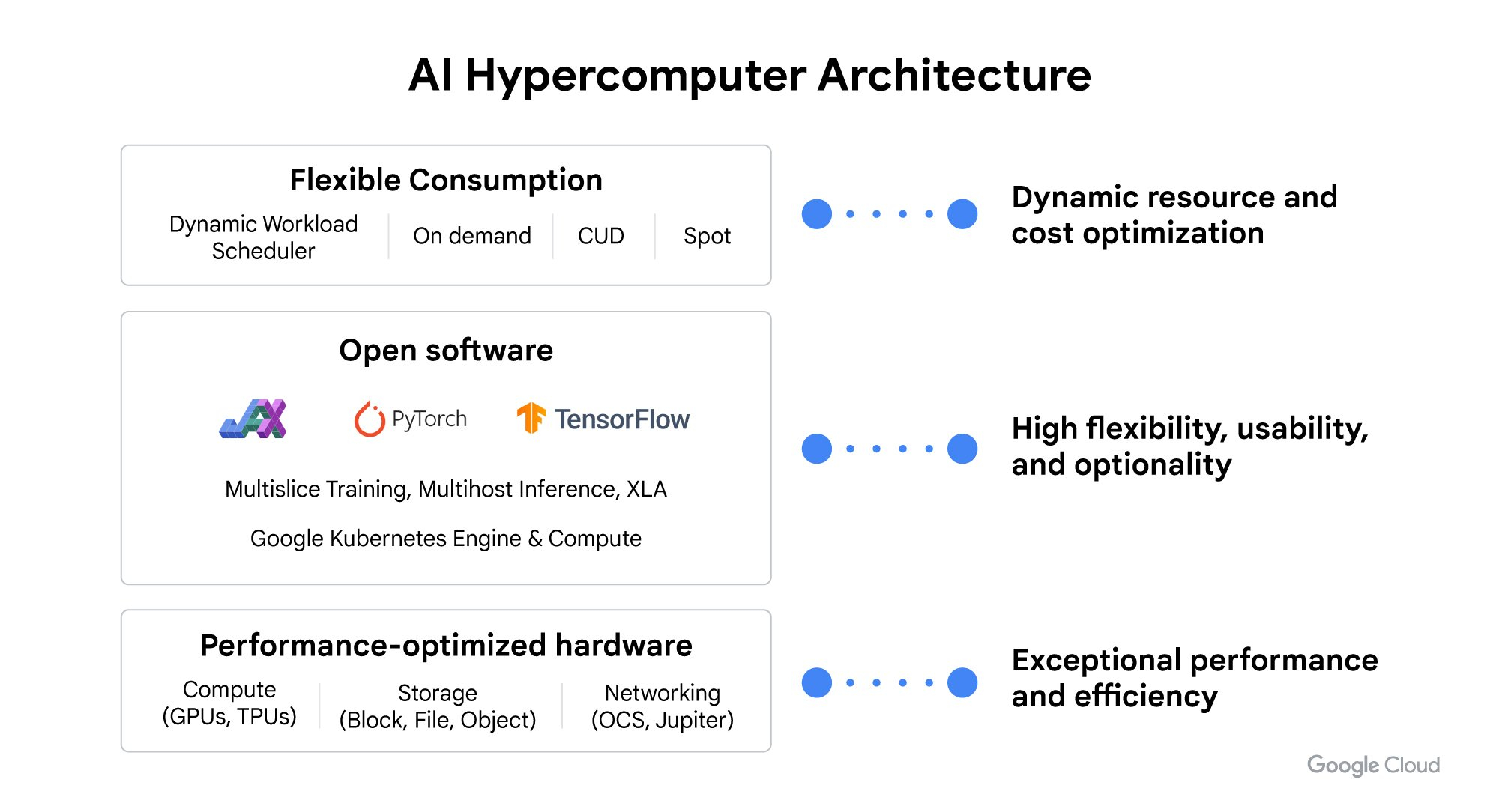
Источник изображений: Google
Обновления включают в себя доступность модуля Cloud Storage FUSE, который предоставляет файловый доступ к ресурсам облачного хранилища. По данным Google, GCS FUSE обеспечивает увеличение производительности обучения в 2,9 раза по сравнению с существующими СХД. Другие улучшения включают появление поддержки кеширования в превью Parallelstore, высокопроизводительной параллельной файловой системы, оптимизированной для нагрузок ИИ и HPC. Благодаря кешированию Parallelstore позволит сократить время обучения до 3,9 раз и повысить производительность обучения в 3,7 раза.

Компания также объявила об оптимизации службы Google Cloud Filestore, ориентированной на ИИ, которая представляет собой сетевую файловую систему, позволяющую целым кластерам ускорителей получать одновременный доступ к одним и тем же данным. Ещё одно новшество — сервис Hyperdisk ML, предоставляющий блочное хранилище, доступный сейчас в качестве превью. Google Cloud сообщила, что его использование позволит ускорить загрузку модели до 12 раз по сравнению с альтернативными сервисами.

Кроме того, компания представила Jetstream, новую систему инференса LLM. Это открытое решение, оптимизированное по пропускной способности и использованию памяти для ИИ-ускорителей вроде TPU. По словам компании, новинка обеспечит в три раза более высокую производительность на доллар для Gemma 7B и других открытых ИИ-моделей, а это важно, поскольку клиенты переносят свои ИИ-нагрузки в облако и им нужен экономичный, но производительный инференс. JetStream предлагает поддержку моделей, обученных с помощью JAX и PyTorch/XLA, а также включает оптимизацию для популярных открытых моделей, таких как Llama 2 и Gemma.

Что касается собственно моделей, то компания представила MaxDiffusion для генерации изображений, добавила в MaxText ряд новых моделей, в том числе Gemma, GPT3, Llama 2 и Mistral. MaxDiffusion и MaxTest базируются на высокопроизводительном фреймворке JAX, который интегрирован с оптимизирующим компилятором OpenXLA. Заодно Google объявила о поддержке последней версии PyTorch — PyTorch/XLA 2.3.
Источник:

