Материал подготовлен командой Catalyst.
Мнение авторов может не совпадать с мнением редакции
Высокопроизводительные GPU сегодня востребованы во всех областях IT-индустрии, в научных проектах, в системах безопасности и других направлениях. Инженерам, архитекторам и дизайнерам мощные компьютеры нужны для рендеринга и 3D-анимации, для тренировки нейронных сетей и для анализа данных, для аналитики в режиме реального времени и для других задач, связанных с большим объемом вычислений. В общем, высокопроизводительные GPU-серверы — весьма популярное решение на рынке.
С каждым годом во всех сферах получают все большее распространение методы искусственного интеллекта (ИИ) и машинного обучения (ML). Эти технологии уже сейчас совершают революцию в области медицинской диагностики, помогают развивать финансовые инструменты, создавать новые сервисы интеллектуальной обработки данных, позволяют реализовывать различные проекты в области фундаментальной науки, робототехники, управления человеческими ресурсами, транспорта, тяжелой промышленности, городского хозяйства, распознавания речи, лиц и объектов, доставки контента. Например, NVIDIA призвала владельцев компьютеров с мощными GPU использовать их для помощи в борьбе со вспышкой пандемии коронавирусной инфекции COVID-19.
GPU как сервис
Поскольку многие современные задачи машинного обучения используют графические процессоры, перед людьми все чаще встает вопрос: что же для этих целей выбрать? Чтобы ответить на него, очень важно разбираться в показателях стоимости и производительности разных GPU. В настоящее время целый ряд провайдеров предлагает виртуальные, облачные (GPUaaS) и выделенные серверы с GPU для машинного обучения.
Выделенные серверы — оптимальный вариант, когда вычислительные мощности требуются на постоянной основе, а содержать собственную машину невыгодно или попросту невозможно. Некоторые провайдеры сдают в помесячную аренду такие сервера, и при наличии необходимого количества задач, способных этот сервер загрузить, в пересчете на часы и минуты цены могут быть весьма привлекательными. Однако в большинстве случаев все же предпочтительнее виртуальные серверы (VDS/VPS) с тарификацией по часам или минутам либо облачные сервисы — это обычно и дешевле, и более гибко.
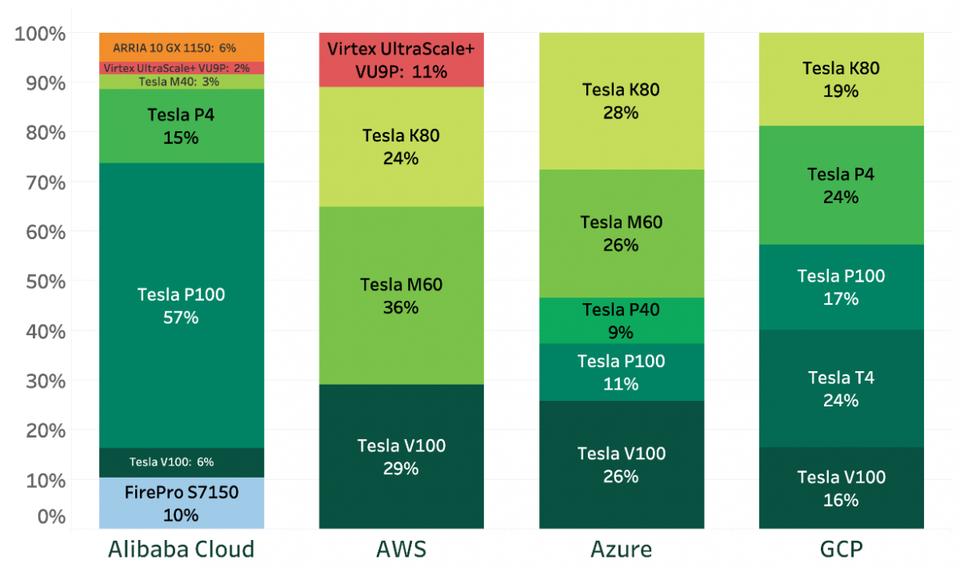
Доли выделенных инстансов GPU разных типов четырех ведущих провайдеров (по данным Lliftr Cloud Insight, май 2019 г.)
Согласно последнему отчету Global Market Insights, объем мирового рынка GPUaaS к 2025 году превысит $7 млрд. Участники рынка разрабатывают GPU-решения специально для глубокого обучения (DL) и ИИ. Например, NVIDIA Deep Learning SDK обеспечивает высокопроизводительное GPU-ускорение для алгоритмов глубокого обучения и предназначен для создания готовых DL-фреймворков.
Компании, работающие на рынке GPUaaS, фокусируются на технологических инновациях, стратегических приобретениях и слияниях для укрепления своих рыночных позиций и приобретения новых клиентов. В числе ключевых игроков рынка GPUaaS: AMD, Autodesk, Amazon Web Services (AWS), Cogeco Communications, Dassault Systems, IBM, Intel, Microsoft, Nimbix, NVIDIA, Penguin Computing, Qualcomm, Siemens, HTC. Для машинного обучения, пожалуй, наиболее популярны GPU-инстансы в AWS, Google Cloud Engine, IBM Cloud и Microsoft Azure.
Можно также воспользоваться мощностями графических ускорителей менее известных провайдеров — их GPU-серверы тоже подойдут для самых разных проектов. Каждая платформа имеет свои плюсы и минусы. Считается, что высокопроизводительные серверы с мощными GPU позволяют быстрее достигнуть поставленных целей и получить значимые результаты, но стоят ли дорогие инстансы своих денег, и в каких случаях?
Учиться и еще раз учиться
Процесс обучения модели является более затратным с вычислительной точки зрения и требует гораздо большего количества ресурсов, нежели требуется для исполнения уже обученной модели. Если задача не предполагает какой-то сверхвысокой нагрузки, такой как распознавание лиц с большого числа видеокамер, то для работы достаточно одной-двух карт уровня GeForce GTX 1080 Ti, что очень важно для экономии бюджета проекта. Наиболее мощные современные GPU Tesla V100 же обычно используются именно для обучения.
Более того, рабочая версия модели может обойтись даже частью ресурсов GPU — ну или одну карту можно использовать для исполнения нескольких моделей. Однако для обучения такой подход не подойдет в силу особенностей устройства шины памяти, и для обучения каждой модели используется целое число графических ускорителей. Кроме того, процесс обучения зачастую является набором экспериментов по проверке гипотез, когда модель многократно обучается с нуля с использованием различных параметров. Эти эксперименты удобно запускать параллельно на соседних видеокартах.
Модель считается обученной, когда достигнута ожидаемая точность, либо когда точность при дальнейшей тренировке больше не повышается. Иногда в процессе обучения модели возникают «узкие места». Вспомогательные операции вроде предобработки и загрузки картинок могут требовать много процессорного времени — это значит, что конфигурация сервера не была сбалансирована для данной конкретной задачи: CPU не способен «прокормить» GPU.
Это одинаково применимо и для выделенных, и для виртуальных серверов. У виртуального сервера причиной данной проблемы может являться и то, что один CPU фактически обслуживает несколько инстансов. У выделенного же процессор находится в полном распоряжении, но его возможности все равно могут быть недостаточными. Проще говоря, во многих задачах важна мощность центрального процессора, чтобы его производительности хватало на обработку данных на начальном этапе.
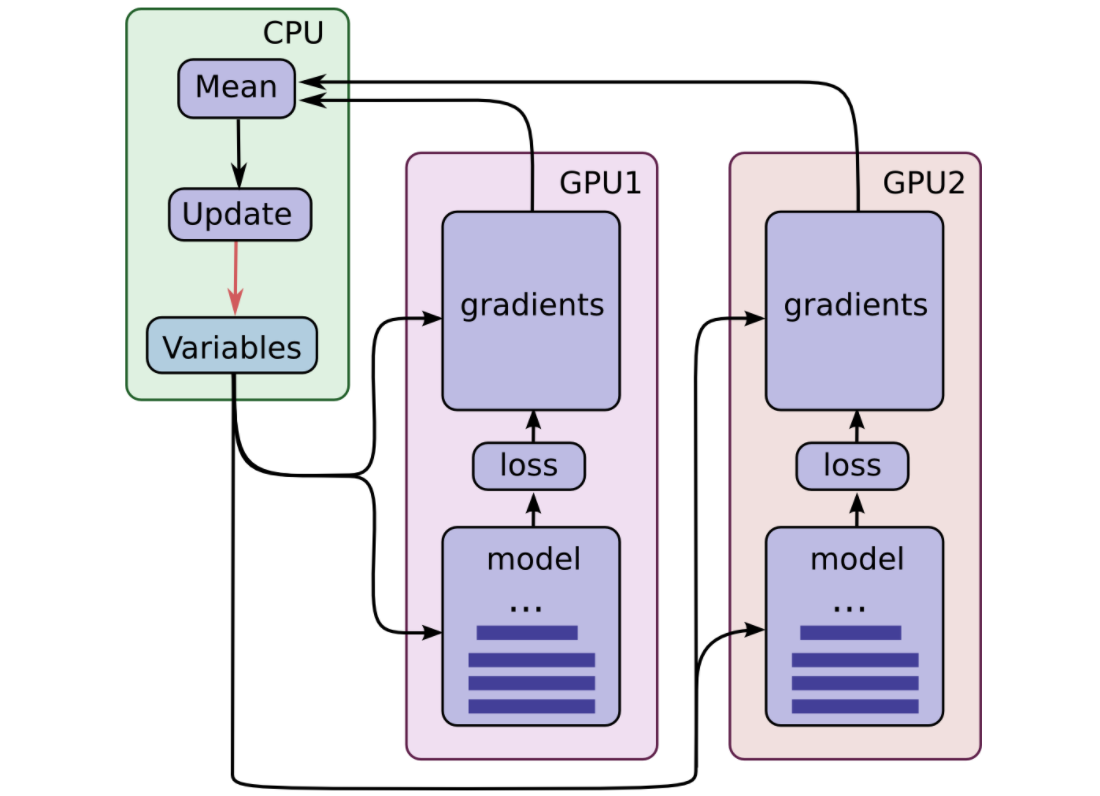
Упрощенная схема обучения модели
Обучение на нескольких (N) GPU происходит следующим образом:
- Берется набор картинок, делится на N частей и «раскладывается» по ускорителям;
- Для каждого ускорителя вычисляется ошибка на своем наборе картинок и будущий градиент (направление, в котором нужно сместить коэффициенты, чтобы ошибка стала меньше);
- Градиенты со всех ускорителей собираются на один из них и складываются;
- Модель делает шаг в этом усредненном направлении на одном ускорителе и обучается;
- Новая, улучшенная модель рассылается на остальные GPU, и повторяется шаг 1.
Если модель очень легкая, то выполнение N таких циклов на одном GPU оказывается быстрее, чем распределение на N GPU с последующим объединением результатов. При этом при активных экспериментах с моделью финансовые затраты могут быть весьма существенными. При проверке множество гипотез время расчетов иногда растягивается на много дней, и компании подчас тратят, например, на аренду серверов Google десятки тысяч долларов в месяц.
Catalyst в помощь
Catalyst — это высокоуровневая библиотека, которая позволяет проводить Deep Learning-исследования и разрабатывать модели быстрее и эффективнее, уменьшая количество boilerplate-кода. Catalyst берет на себя масштабирование пайплайнов и дает возможность быстро и воспроизводимо обучать большое количество моделей. Таким образом, можно меньше заниматься программированием и больше фокусироваться на проверке гипотез. Библиотека включает в себя как ряд лучших отраслевых решений, так и уже готовые пайплайны для задач классификации, детекции и сегментации.
Недавно команда Catalyst начала сотрудничество с Университетом штата Джорджия, Технологическим институтом штата Джорджия и Emory University joint center for Translational Research in Neuroimaging and Data Science (TReNDS), чтобы упростить обучение моделей для приложений нейровизуализации и обеспечить воспроизводимые Deep Learning исследования при визуализации мозга. Совместная работа над этими важными проблемами поможет лучше понять, как работает мозг, и улучшить качество жизни людей с психическими расстройствами.
Возвращаясь к теме статьи, для проверки скорости работы серверов Catalyst использовался во всех трех случаях: на серверах HOSTKEY, Amazon и Google. Вот и сравним, как это было.
Удобство использования
Важный показатель – удобство использования решения. Лишь немногие сервисы предлагают удобную систему управления виртуальными серверами с необходимыми библиотеками и инструкцией, как ими пользоваться. При использовании Google Cloud, например, нужно самостоятельно устанавливать библиотеки. Вот субъективная оценка веб-интерфейсов:
| Сервис | Веб-интерфейс |
| AWS | Анти-лидер: все конфигурации закодированы названиями в стиле p2.xlarge — чтобы понять, какое железо скрывается под каждым именем, нужно перейти на отдельную страницу, а таких имен порядка сотни |
| Средняя оценка, не совсем интуитивная настройка инстансов | |
| Google Colab | Аналог Jupyter Notebook |
| HOSTKEY | Веб-сервис не использовался |
На самом деле, чтобы начать применять эти инструменты, требуется еще порядка 20–60 минут (в зависимости от квалификации) на подготовку — установку программного обеспечения и загрузку данных. Что касается удобства использования уже выданных, готовых к использованию инстансов, то здесь ситуация следующая:
| Сервис | Набор ПО |
| AWS | Абсолютный лидер, на инстансе есть все популярные версии библиотек машинного обучения + предустановленный NVIDIA-Docker. Предусмотрен файл Readme с краткой информацией о том, как переключаться между версиями всего этого многообразия. |
| Сопоставим с HOSTKEY, но можно смонтировать свой Google-диск и иметь очень быстрый доступ к набору данных без необходимости его перегонять на инстанс. | |
| Google Colab | Предлагается бесплатно, но раз в 6–10 часов инстанс «умирает». ПО отсутствует начисто, включая Docker+NVIDIA-Docker2 вместе с возможностью их установки, хотя можно обойтись без них. Нет прямого SSH-подключения, но возможен быстрый доступ к Google-диску. |
| HOSTKEY | Сервер может предоставляться как без ПО, так и уже полностью настроенным. При самостоятельной настройке можно использовать ПО в виде Docker + NVIDIA-Docker2. Для опытного пользователя это не является проблемой. |
Результаты экспериментов
Команда специалистов из проекта Catalyst провела сравнительное тестирование стоимости и скорости обучения модели с использованием GPU NVIDIA на серверах следующих провайдеров: HOSTKEY (от одной до трёх GeForce GTX 1080 Ti + Xeon E3), Google (Tesla T4) и AWS (Tesla K80). В тестах использовалась стандартная для подобных задач компьютерного зрения архитектура ResNet, которая определяла имена художников по их картинам.
В случае HOSTKEY было два варианта размещения. Первый: физическая машина с одной или тремя видеокартами, CPU Intel Xeon E5-2637 v4 (4/8, 3,5/3,7 ГГц, 15 Мбайт кеш), 16 Гбайт RAM и SSD 240 Гбайт. Второй: виртуальный выделенный сервер VDS в той же конфигурации с одной видеокартой. Разница лишь в том, что во втором случае физический сервер имеет сразу восемь карт, но только одна из них отдаётся в полное распоряжение клиента. Все серверы располагались в ЦОД в Нидерландах.
Инстансы обоих облачных провайдеров были запущены в дата-центрах Франкфурта-на-Майне. В случае AWS использовался вариант p2.xlarge (Tesla K80, 4 vCPU, 61 Гбайт RAM), и часть машинного времени ожидаемо ушла на подготовку данных. Аналогичная ситуация произошла и в облаке Google, где использовался инстанс с 4 vCPU и 32 Гбайт памяти, к которым добавлялся ускоритель. Карта Tesla T4, пусть она и ориентирована на инференс, была выбрана потому, что по производительности на обучении она находится где-то между GTX 1080 Ti и Tesla V100. Так что на практике её иногда всё же задействуют под обучение, так как она обходится заметно дешевле V100.
| Таблица сравнения времени обучения и стоимости тренировки модели на разных платформах | |||||||
|---|---|---|---|---|---|---|---|
| Платформа | GPU | К-во GPU | Модель | Итоговое качество, AUC | Время обучения, с | Цена обучения, ¢/с | Стоимость обучения, € |
| HOSTKEY | 1 × GeForce GTX 1080 Ti VDS | 1 | Тяжелая | 0,9835 | 7 581 | 0,0062 | 0,47 |
| HOSTKEY | 1 × GeForce GTX 1080 Ti | 1 | Тяжелая | 0,9835 | 7 092 | 0,0062 | 0,44 |
| HOSTKEY | 3 × GeForce GTX 1080 Ti | 3 | Тяжелая | 0,9835 | 2 430 | 0,0202 | 0,49 |
| AWS | 1 × Tesla K80 | 1 | Тяжелая | 0,9835 | 13 080 | 0,0429 | 5,61 |
| 1 × Tesla T4 | 1 | Тяжелая | 0,9835 | 1 003 | 0,4087 | 4,50 | |
| HOSTKEY | 1 × GeForce GTX 1080 Ti VDS | 1 | Легкая | 0,9091 | 1 445 | 0,0062 | 0,09 |
| HOSTKEY | 1 × GeForce GTX 1080 Ti | 1 | Легкая | 0,9091 | 1 157 | 0,0061 | 0,07 |
| AWS | 1 × Tesla K80 | 1 | Легкая | 0,9091 | 3 930 | 0,0545 | 2,14 |
| 1 × Tesla T4 | 1 | Легкая | 0,9091 | 872 | 0,2294 | 2,00 | |
Модель использовалась в двух версиях: «тяжелой» (resnet101) и «легкой» (resnet34). Тяжелая версия имеет лучший потенциал для достижения высокой точности, в то время как легкая дает больший прирост производительности при несколько большем числе ошибок. Более тяжелые модели обычно используются там, где нужно достигать максимальных результатов в качестве предсказания, например при участии в соревнованиях, в то время как легкие — в местах, где необходимо соблюдать баланс точности и скорости обработки, например в нагруженных системах, ежедневно обрабатывающих десятки тысяч запросов.
.png)
Стоимость обучения модели на сервере HOSTKEY с «домашними» картами оказывается почти на порядок ниже, чем в случае Google или Amazon, и занимает незначительно больше времени. И это несмотря на то, что GeForce GTX 1080 Ti — далеко не самая быстрая на сегодня карта для решения задач глубокого обучения. Однако, как показывают результаты экспериментов, в целом недорогие карты вроде GeForce GTX 1080 Ti не настолько хуже своих более дорогих собратьев по быстродействию, если учитывать их заметно меньшую стоимость.
.png)
Если карта на порядок дешевле, то по производительности на тяжелых моделях она уступает всего лишь в 2-3 раза, и можно «добрать» скорость, добавив еще карт. Все равно это решение будет дешевле Tesla-конфигураций в пересчете на стоимость тренировки модели. По результатам также видно, что Tesla K80 в AWS, которая демонстрирует высокие характеристики в вычислениях с двойной точностью, с одинарной точностью показывает очень большое время — хуже, чем 1080 Ti.
Выводы
Общая тенденция такова: более дешевые графические карты потребительского уровня обеспечивают в целом лучшее соотношение цены и производительности, чем дорогие GPU Tesla. Проигрыш в «чистой» скорости GTX 1080 Ti по сравнению с Tesla можно компенсировать увеличением числа карт, всё равно оставаясь при этом в выигрыше.
Если вы планируете выполнять задачу, расчет которой займет продолжительное время, серверов с недорогими GTX 1080 Ti будет достаточно. Они подходят для пользователей, которые планируют долговременную работу с этими ресурсами. Дорогие инстансы на основе Tesla следует выбирать в тех случаях, когда обучение модели занимает мало времени и можно тарифицировать работу по минутам обучения.
Также следует учитывать простоту подготовки среды на платформах — установку библиотек, развёртывание ПО и загрузку данных. GPU-серверы — и реальные, и виртуальные — всё же заметно дороже классических CPU-инстансов, так что длительное время подготовки ведёт к лишним расходам.

