Материалы по тегу: tensordyne
|
19.06.2026 [19:34], Владимир Мироненко
«Логарифмический» ИИ-ускоритель Tensordyne Napier обещает выскоую производительность при минимальном энергопотребленииИИ-стартап Tensordyne (ранее Recogni) анонсировал платформу Tensordyne Napier (TDN) для ИИ-инференса, разработанную в партнёрстве с Broadcom и HPE Juniper Networks, которая «сочетает в себе инновационные логарифмические математические вычисления в области ИИ, тесно интегрированную архитектуру памяти и высокопроизводительный масштабируемый интерконнект, обеспечивая существенно более высокую пропускную способность, меньшее энергопотребление и улучшенную экономику инфраструктуры для крупномасштабных задач ИИ-инференса». По словам Tensordyne, новый «логарифмический» чип позволит решить, как проблему скорости, так и стоимости ИИ-инференса. В нём компания заменила крупномасштабные операции умножения упрощёнными вычислениями на основе сложения, значительно повысив эффективность на Вт. Сумматоры меньше размером и как правило потребляют меньше энергии, чем умножители, поэтому их использование обеспечит больше полезной площади для SRAM и лучшую сбалансированность системы. 
Источник изображений: Tensordyne Чип включает 138 млрд транзисторов и поддерживает обработку данных в режимах NVFP4, FP8 и FP16. Tensordyne сообщила о 2,1 Пфлопс в формате плотных вычислений FP8 на кристалл. Частота ядра ускорителя составляет 1,33 ГГц, поддерживающих ядер RISC-V — 1,5 ГГц. Чип получил четыре блока HBM4 (по данным ServeTheHome — HBM3E), каждый по 36 Гбайт (144 Гбайт в сумме) с пропускной способностью 4,7 Тбайт/с. Также на чипе размещено 256 Мбайт SRAM с суммарной пропускной способностью 40 Тбайт/с. Интеграция значительного объёма быстрой SRAM с HBM позволила минимизировать циклы простоя вычислений и обеспечить эффективную поддержку выполнения самых больших моделей в отрасли.  Как рассказал ресурсу The Next Platform Р.К. Ананд (RK Anand), сооснователь и директор по продуктам Tensordyne, ускоритель имеет 48 ядер, которые связаны с блоками обработки векторов. В векторном блоке тоже есть ALU, но он также может использовать таблицу поиска (LUT) и работать полностью параллельно. В целом доступны чередование операций и управляемый конвейер. По словам Ананд, Napier потребляет всего 300 Вт по сравнению с 1200-Вт NVIDIA B300, поскольку новый чип довольно компактен. Ананд не уточнил, состоит ли чип Napier из чиплетов или представляет собой монолитный кристалл. 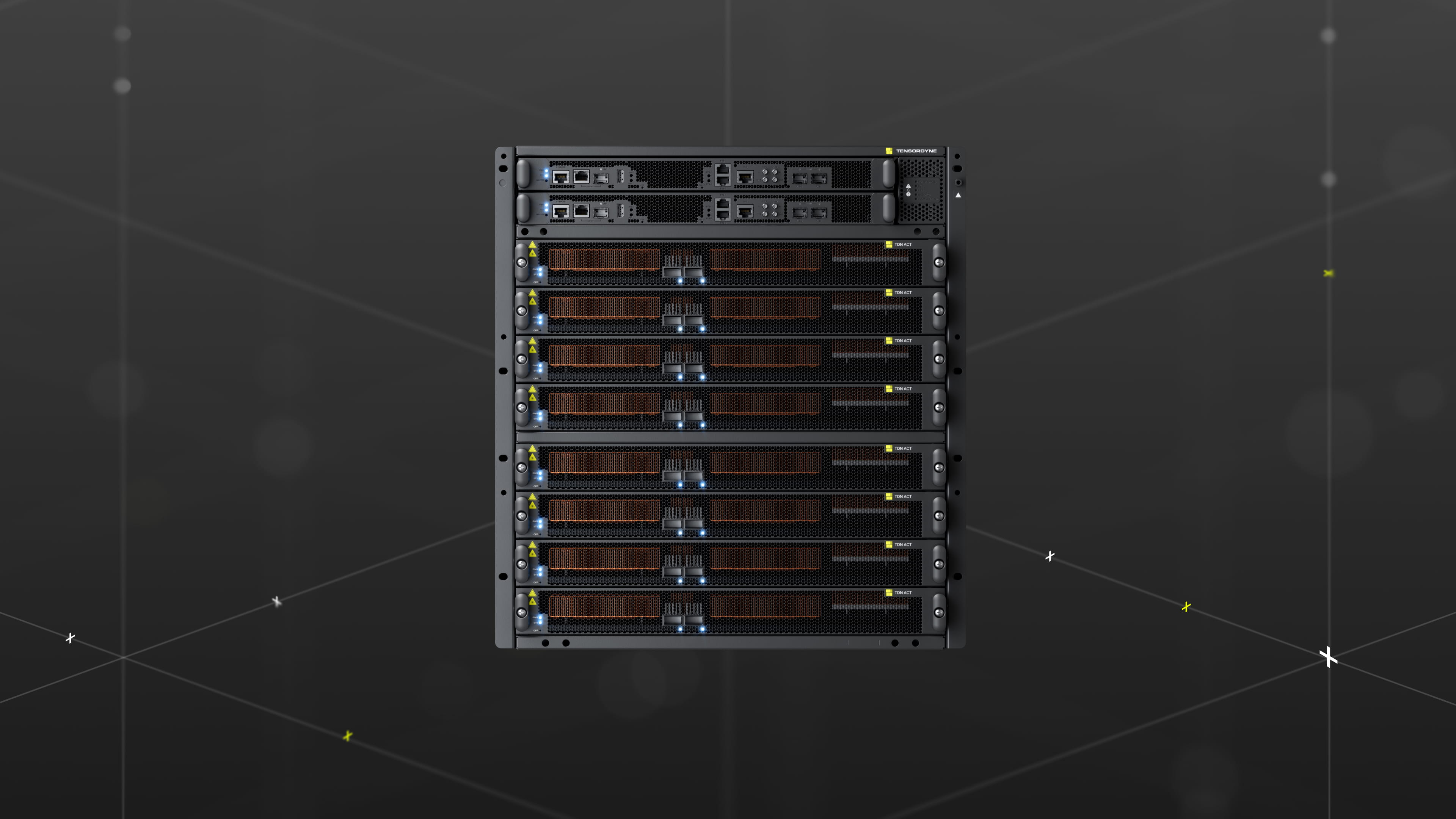 Девять чипов TDN могут размещаться в 1U-узле, в котором установлен 40-ядерный процессор Xeon для управления хостом и выполнения некоторых задач декодирования, а также 8-Тбайт NVMe SSD. Узел имеет два 200GbE-порта QSFP, а на задней панели расположены шесть портов для фирменного интерконнекта TDNLink, используемого для соединения 72 чипов TDN. Узел обеспечивает 19 Пфлопс в режиме FP8, 1,3 Тбайт HBM и 2,25 Гбайт SRAM с агрегированной пропускной способностью 42 Тбайт/с и 360 Тбайт/с соответственно. Узлы Napier, подобно NVIDIA NVLink, соединены через объединительную плату посредством проприетарного интерконнекта TDNLink. Суперускоритель TDN72 объединяет 72 чипа TDN (восемь узлов), причём TDNLink способен обеспечить задержку менее микросекунды между чипами при пропускной способности 1 Тбайт/с.  TDN72 ориентирован на модели с количеством параметров от 10 до 20 трлн, для работы с которыми важны объём памяти и MoE-маршрутизация. «В каждом TDN72 у нас 320 ядер Xeon и 4608 ядер RISC-V», — отметил сооснователь и вице-президент Tensordyne Жиль Бакхус (Gilles Backhus). «Мы применяем двухуровневый подход к решению проблемы с CPU. Вся работа, выполняемая непосредственно вблизи вычислительных процессов ИИ в рамках цикла обработки токенов и авторегрессионного цикла LLM, в основном проводится на ядрах RISC-V. Здесь же осуществляется маршрутизация MoE, проверка по словарю для отбрасывания определённых токенов и т.д. Прочая обработка данных для инференса происходит на процессорах Intel Xeon».  Четыре TDN72 помещаются в стандартную 52U-стойку Tensordyne Napier, что даёт 608 Пфлопс (FP8), 42 Тбайт HBM, 74 Гбайт SRAM, 256 Тбайт NVMe SSD, 275-Тбайт/с соединение TDNLink и 64 порта 200GbE. При этом такая стойка потребляет всего 120 кВт и может обходиться воздушным охлаждением. Как сообщила компания, стойка Tensordyne Napier обеспечивает по сравнению с полноразмерной стойкой NVIDIA NVL72:
Система поддерживает дезагрегированное обслуживание и выполнение моделей с многотриллионными параметрами со скоростью более 1000 токенов в секунду на пользователя. Для достижения той же пропускной способности потребовалось бы как минимум девять стоек NVIDIA Rubin + Groq LPX, отметила Tensordyne.
Самой сложной составляющей запуска платформы может стать ПО. Tensordyne сообщила о выпуске на платформе Hugging Face центра моделей со своим SDK, прямой компиляцией моделей для PyTorch/Triton и кастомным eDSL для Python. Следует отметить, что одним из важных преимуществ ускорителей NVIDIA является экосистема CUDA — огромная база фреймворков, ядер, инструментов профилирования, шаблонов развёртывания и моделей поведения разработчиков. Любой новый ИИ-ускоритель должен сопровождаться достаточно простым ПО, чтобы клиенты захотели его внедрять в своих системах. |
|


