Что такое TidalScale?
TidalScale — это, если говорить упрощённо, гипервизор «наоборот». Вместо привычного разделения одной физической машины на несколько виртуализированных систем, TidalScale, напротив, позволяет объединить несколько физических узлов в единый, программно определяемый сервер. Ну или в несколько серверов. Иными словами, он позволяет прозрачно подменить вертикальное масштабирование горизонтальным так, чтобы гостевые системы и приложения ничего не заметили.
Это не единственная система такого рода, но TidalScale делает упор на масштабирование с точки зрения объёмов оперативной памяти, а не вычислительных ресурсов. Во всяком случае, сейчас. Разработчик, конечно, рассказывает о прелестях консолидации имеющихся у пользователя ресурсов для повышения эффективности использования оборудования: объединив все машины под крылом одного гипервизора и «нарезая» их на виртуальные серверы, можно лучше нагрузить «железо». Правда, при этом выход единственного узла из строя порушит всю систему разом.
На практике же пока есть некоторые ограничения. В один пул можно объединить до 8 четырёхсокетных узлов, каждый из которых может содержать до 128 физических ядер и до 3 Тбайт RAM. Для виртуальной машины (ВМ/инстанс или SDS в данном случае) можно выделить до 254 vCPU и до 16 Тбайт RAM. В будущих релизах обещана поддержка ВМ с 1024 vCPU и 64 Тбайт RAM. Пока сам вендор рекомендует не больше 64 vCPU на инстанс и по умолчанию даёт ему не более 70 % от общего объёма памяти пула, но при желании этот лимит можно поднять до 90 %.
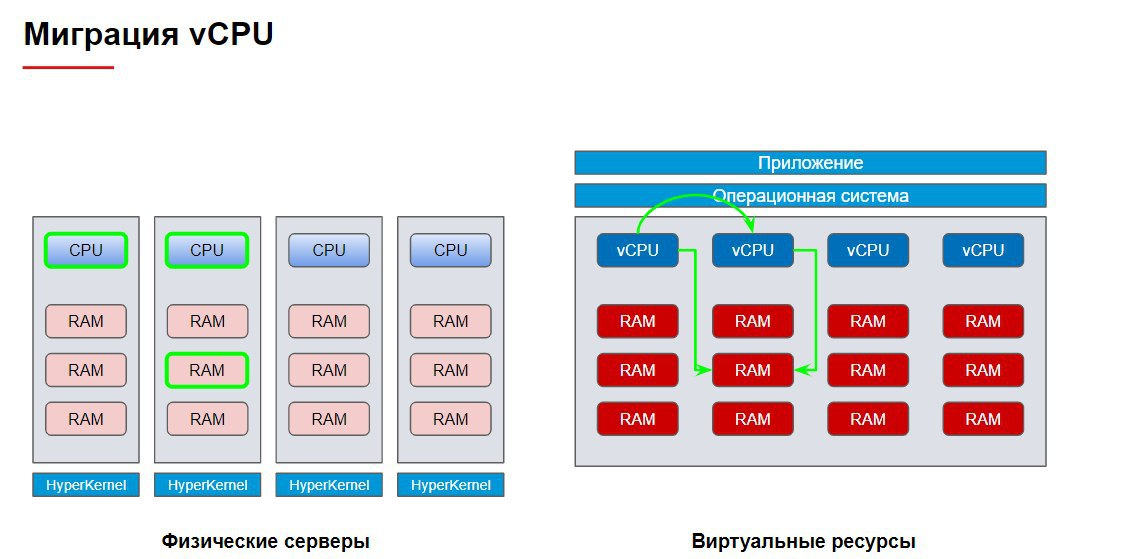
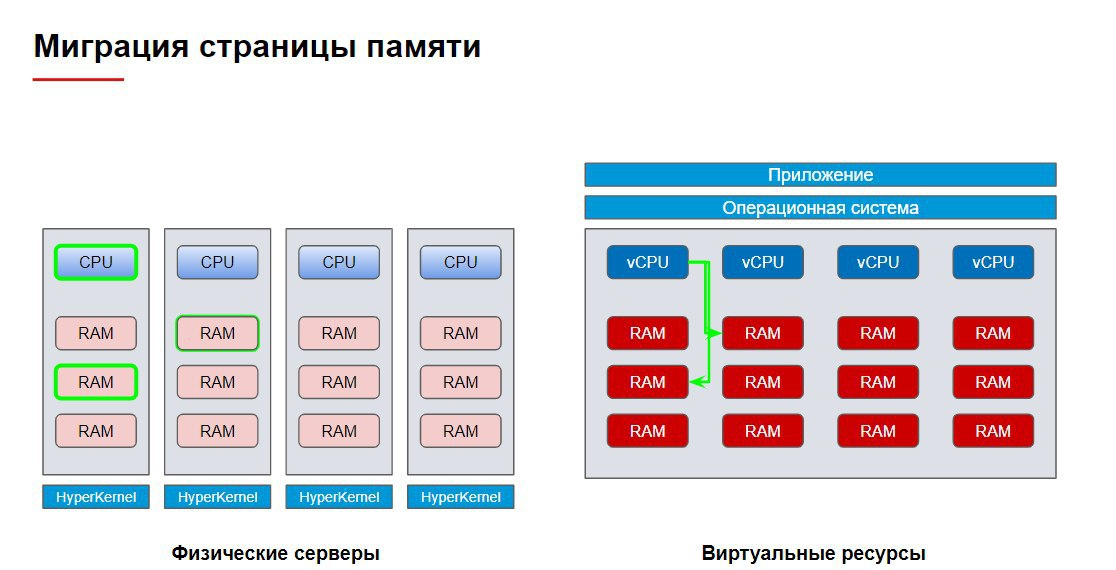
Прозрачность в целом есть, но есть и некоторые нюансы. Да, ВМ «видит» все выделенные ей ресурсы, а гипервизор «умным» образом распределяет всю работу между нижележащими физическими узлами, стараясь избегать ненужных «перескоков» между ними — очередь команд исполняется на одном CPU, система избегает лишних обращений к памяти соседнего узла, а данные по-хорошему должны складироваться в ближайшее хранилище. При этом гипервизор использует машинное обучение, чтобы с течением времени лучше подстраиваться под текущую нагрузку.
Вместе с тем гостевым ВМ не показываются инструкции AVX512, они не догадываются об SMT, у них должны быть отключены Transparent Huge Pages (THP), они должны использовать дополнительный источник энтропии для ГПСЧ, virtio-драйверы несколько медленнее стандартных, а некоторые параметры и значения /proc и /sys недоступны или могут отображать неверные сведения. Есть и другие тонкости, в том числе с самим гипервизором. Например, в нашей тестовой системе CPU работали на постоянной частоте, причем ниже базовой.
Зачем это нужно?
Очевидный ответ — для вертикально масштабируемых нагрузок, которые в принципе неспособны распараллеливаться на несколько узлов. К типовым «вертикальным» задачам относятся различные виды аналитики, моделирования и визуализации. Они вообще критичны именно к объёму оперативной памяти, где и хранится весь необходимый для работы набор данных. Вот только итоговая стоимость RAM в системе растёт нелинейно и зависит от нескольких факторов. Так что правильный ответ: для экономии денег! Увы, самого главного — стоимости лицензий и принципа её формирования — TidalScale не раскрывает.

В целом уже очень давно есть дисбаланс между ростом числа ядер и числа каналов памяти — первый происходит намного быстрее. При этом и объём поддерживаемых модулей на канал тоже растёт относительно медленно, а вот стоимость модулей с увеличением их ёмкости — наоборот, быстро. Всё, что выходит за пределы типовой двухсокетной платформы, тут же начинает стоить немалых денег. И речь не только про шасси.

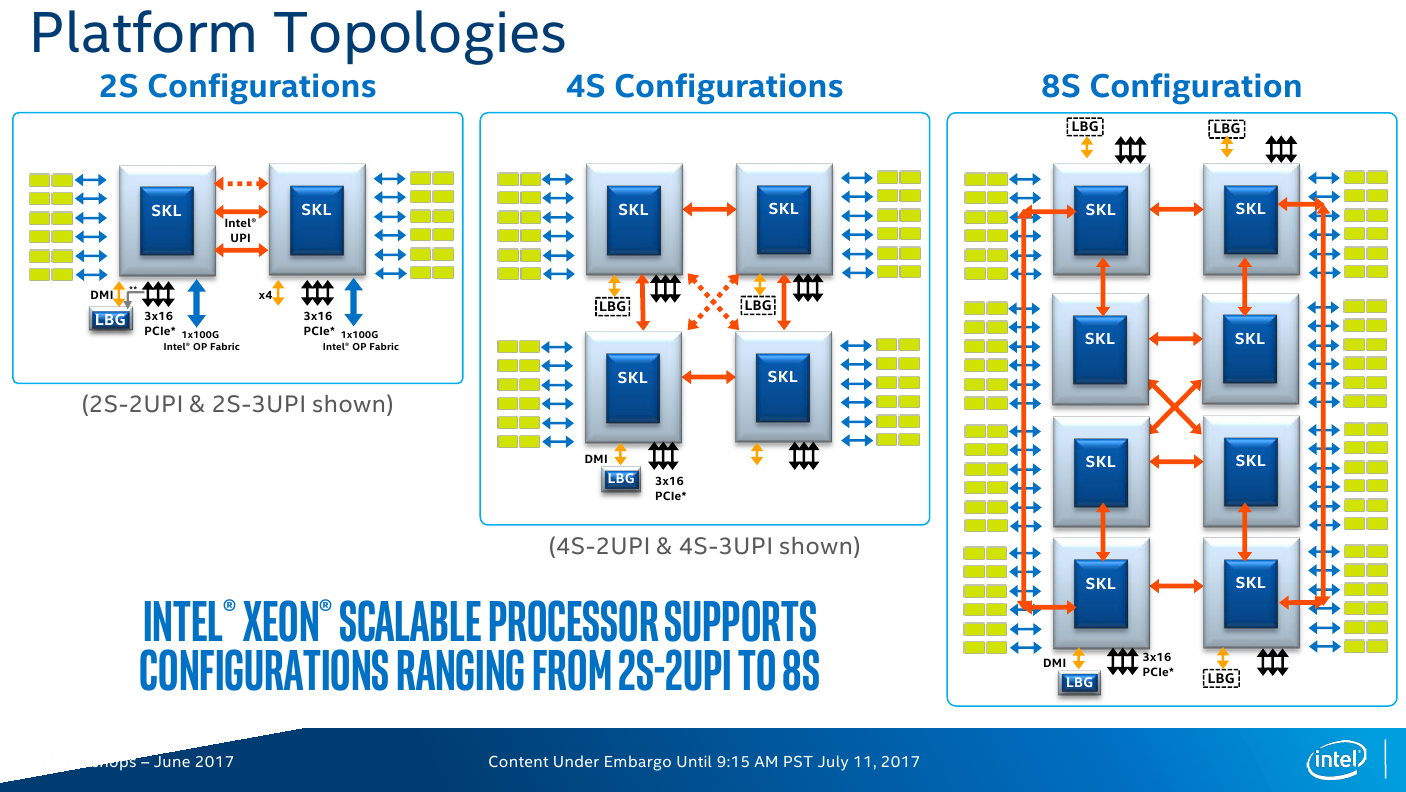
Единственно возможным вариантом для физических 4s/8s-серверов являются решения Intel. Причём для 8s-платформ требуются дорогие старшие модели CPU, которые поддерживают большой объём памяти и имеют по 3 линии UPI. А в предельном случае скорость доступа будет ограничена одной линией, то есть 20,8 Гбайт/с, что, впрочем, всё равно примерно на три порядка быстрее текущего интерконнекта TidalScale. Масштабирование выше 8s становится нетривиальным и зачастую включает фактически многоузловые системы, тогда как TidalScale предлагает набирать ёмкость RAM хоть дешёвыми двухсокетными машинами.
Альтернативный путь уменьшения затрат на RAM — использование Storage Class Memory, а в общем случае уже и пересмотр иерархии памяти. С появлением IMDT, а затем и Intel Optane DCPMM, стала доступной возможность расширения объёма RAM узла с помощью более дешёвой твердотельной памяти. Бонусом получаем сохранность данных, например при перезагрузке из-за сбоя. Типовым примером использования режима App Direct для DCPMM как раз является «вертикальная» SAP HANA.
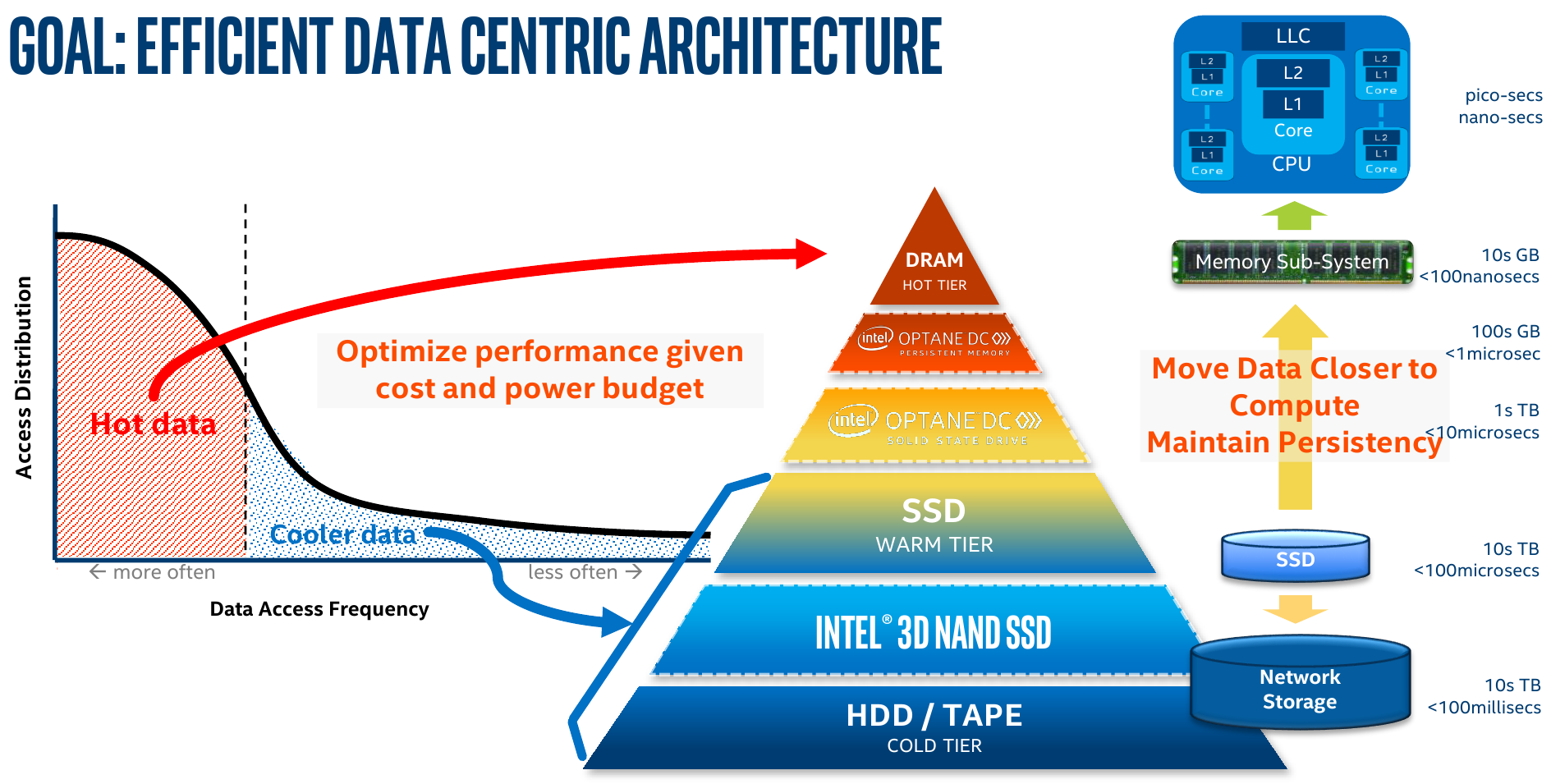
Такие решения есть даже в облаке — Azure предлагает инстансы с 9 Тбайт общей памяти. Но не стоит забывать, что режим App Direct требует модификации ПО, а производительность Memory Mode, то есть прозрачного расширения объёма RAM, зависит от типа нагрузки. Впрочем, про Optane мы ещё вспомним чуть ниже.
Как устроен TidalScale?
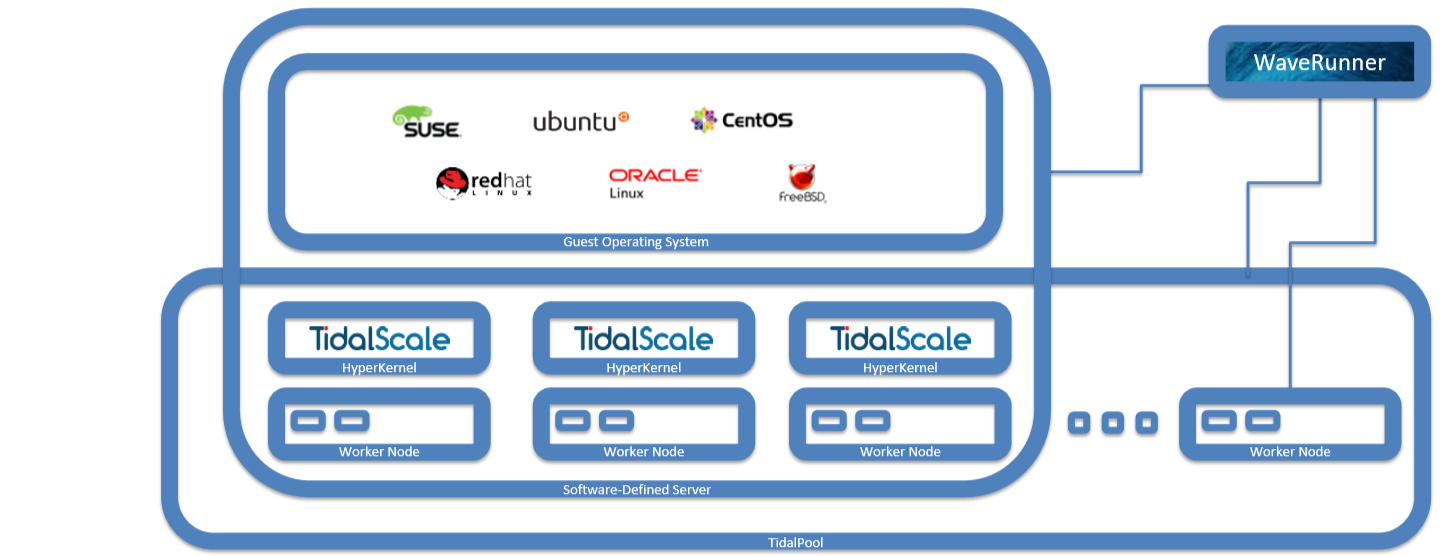
Вся система управляется сервером WaveRunner, запущенным на физической или виртуальной машине. Он предоставляет пользователю веб-интерфейс, а также RESTful API. WaveRunner позволяет объединять несколько физических хостов (Worker Nodes), где и будет работать слой виртуализации HyperKernel, в пул TidalPool, где запускаются виртуальные машины (SDS).

Хосты должны быть примерно одинаковыми по CPU и RAM. Минимальные требования к ним невелики: Intel Xeon E5 v3 или более новые CPU, 32 Гбайт RAM, несколько сетевых интерфейсов и BMC с поддержкой IPMI 2.0. Часть ядер потребуется для гипервизора и обслуживания ввода/вывода.
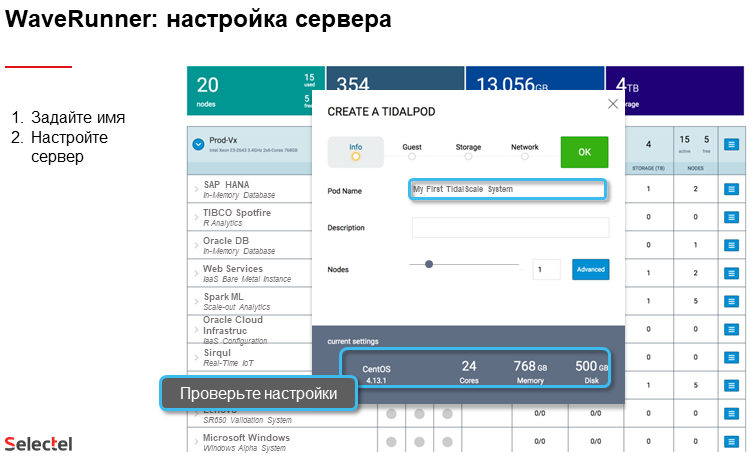
Для WaveRunner требования те же, но памяти достаточно будет 16 Гбайт. А вот с дисками чуть сложнее. Загрузочный том ёмкостью от 50 Гбайт (рекомендуют 300) должен быть отзеркалирован. Если используются HDD, то для кеширования нужен SSD такого же рекомендуемого объёма. Для логов понадобится ещё один диск на 100 Гбайт.
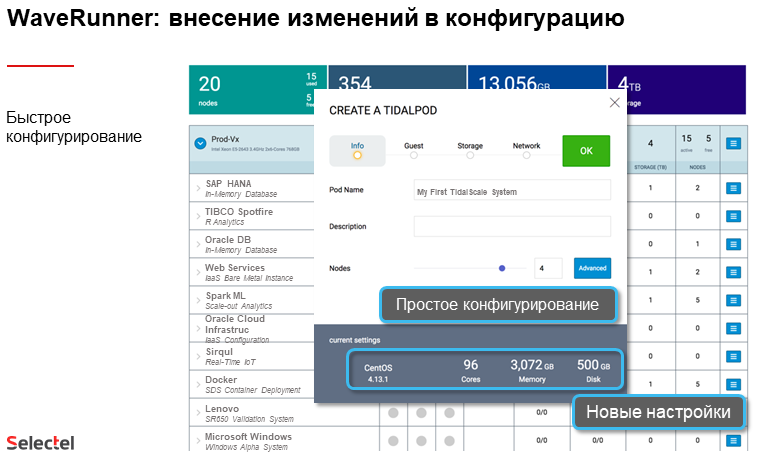
WaveRunner управляет состоянием хостов именно по IPMI, включая/выключая их и загружая посредством PXE HyperKernel на каждом из них. Поэтому предполагается наличие сразу нескольких отдельных сетей. По одной надо для BMC и PXE. Для доступа к остальной корпоративной сети и для SAN тоже требуется хотя бы по одному интерфейсу. Наконец, для интерконнекта между узлами нужно быстрое изолированное подключение. Поддерживаются скорости до 25GbE, и рекомендуется использовать Jumbo-кадры. «Гостям» также доступны интерфейсы до 25 GbE, а всего им можно выделить до 32 virtio-устройств.
Что касается подсистемы хранения данных, то есть несколько вариантов реализации. В требованиях к хостам накопители не упомянуты, так как предполагается, что тома будут подключаться по сети. Однако на самих хостах доступен проброс локальных устройств, так что можно организовать хранилище и на них. Хотя сами разработчики рекомендуют использовать DAS для хостов, а лучше всего — вообще отдельную iSCSI/FC SAN или NAS хотя бы с 10GbE-подключением. Альтернативный вариант — функция СХД самого WaveRunner. Для этого рекомендуется иметь зерекальный массив из хотя бы пары терабатайтных накопителей, на которых будут развёрнуты ZFS-пулы. Можно подключить и внешние JBOD-полки.

Список официально поддерживаемых гостевых систем выглядит так:
- CentOS 7.1, 7.2, 7.3, 7.4;
- Red Hat Enterprise Linux 7.1, 7.2, 7.3, 7.4;
- Ubuntu 16.04;
- SUSE Linux Enterprise Server 12 SP3, 15;
- Oracle Linux 6.5, 6.6, 6.7, 7.6;
- FreeBSD 11.1, 11.2, 12.0.
Проблем с запуском «гостей» с UEFI быть не должно. Фактически же на тестовой системе была развёрнута Ubuntu 19.10. Нам досталась виртуальная машина с 64 vCPU и 8 Тбайт RAM. Никаких особенных настроек, кроме принудительного отключения THP, не делалось. На запуск такой ВМ уходит 15-20 минут. Других SDS на этом же кластере запущено не было.

Конфигурация Selectel HyperServer
Selectel предлагает услугу HyperServer, которая как раз и базируется на TidalScale. В нашем случае кластер состоял из четырёх шасси Supermicro 218UTS-R1K62P с четырёхсокетными платами X11QPH+. Каждая из них несла процессоры Intel Xeon Gold 6240 (18/36, 2,6/3,9 ГГц, L3 24,75 Мбайт) и 3 Тбайт памяти: 48 модулей по 64 Гбайт DDR4 ECC Reg. Для 10GbE-интерконнекта использовались адаптеры Intel X520-DA2, подключённые с помощью DAC к коммутатору Huawei CloudEngine 6850. На одном из узлов работал и WaveRunner. Основное хранилище было реализовано его же силами: программный массив на базе HBA с четырьмя Intel S4510 по 2 Тбайт.

Узлы HyperServer
Тестирование
Polymem — это утилита, которая считает полиномы n-го порядка, складывая их в массив заданного размера в оперативной памяти. Подобные расчёты являются частью многих научных задач. Polymem по сути является STREAM-подобным бенчмарком, но с регулируемой интенсивностью вычислений, что позволяет определить баланс между скоростью расчётов и скоростью работы памяти. Он, в частности, использовался в работе по оценке эффективности Intel Optane DCPMM и IMDT. Полная версия работы доступна публично.
IMDT для расширения видимого объёма RAM и TidalScale до некоторой степени роднит то, что при росте объёма данных в памяти рано или поздно наступит момент, когда собственно локальной RAM станет не хватать — и гипервизору придётся обращаться к чужой памяти на соседнем узле в случае TidalScale или к Optane в случае IMDT. Для теста Polymem был собран GCC c параметрами из комплектного Makefile. В рамках каждого этапа он запускался трижды, с привязкой потоков к ядрам (vCPU) посредством OpenMP.
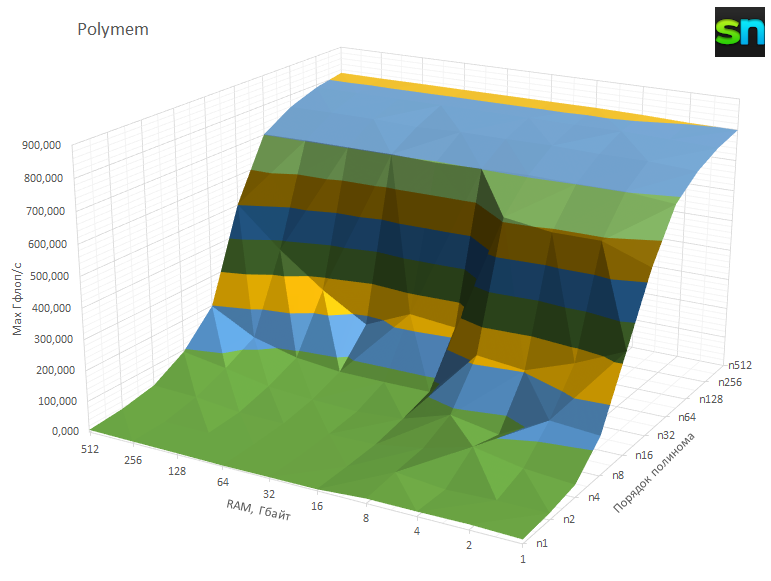
Первый прогон сделан с малым объёмом RAM и вариативным порядком для примерной оценки необходимого уровня интенсивности вычислений. В целом вблизи n=512 максимальная скорость расчётов устаканивается в районе 800 Гфлоп/с и более стремительно не растёт при увеличении порядка полинома. Теоретический максимум для наших 64 ядер с доступом только к AVX2/FMA (2 × 16 Флоп/такт) и с устоявшейся тактовой частотой около 2,15 ГГц составляет примерно 2,2 Тфлоп/с. Впрочем, и безо всякой виртуализации на обычном «железе» Polymem обычно выдаёт около половины от возможного максимума.
Фактически же даже в рамках такого небольшого теста реальные показатели производительности иногда имели сильные провалы: где-то в два-три раза от максимальной, а где-то и на порядок. Удивлять это никого не должно. Во-первых, нагрузка всё равно динамически распределяется между нижележащими физическими хостами. Во-вторых, даже в пределах хоста вся его RAM не может быть отдана исключительно на нужды ВМ — часть всегда используется для кеширования страниц памяти с соседних хостов.
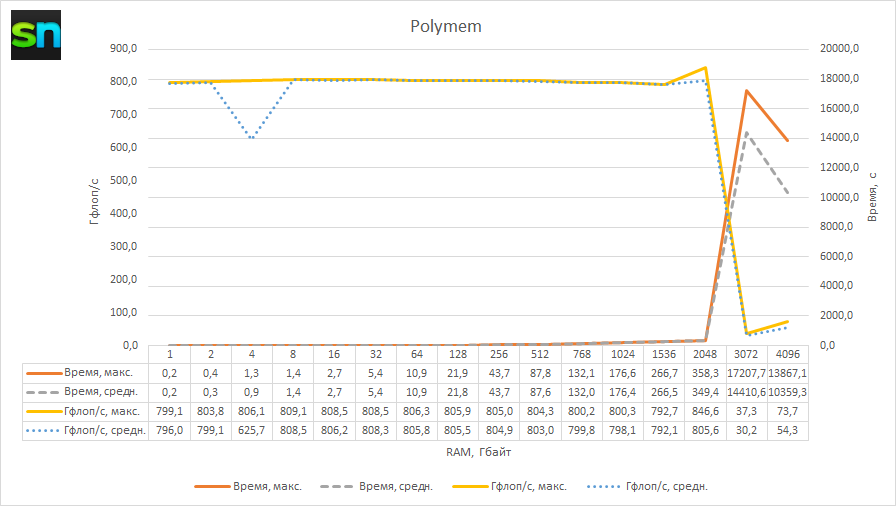
Второй прогон был сделан для объёмов RAM вплоть до 4 Тбайт, чтобы даже в предельном случае точно знать, что память ВМ «размазана» на несколько хостов и ограничивающим фактором будет служить интерконнект. На графике виден перелом, начинающийся с 3 Тбайт, что ожидаемо. И вот тут, конечно, хотелось бы подобрать уже порядок полинома для полноты картины, но… работа с такими объёмами становится просто мучительно долгой, а время, отведённое на знакомство с системой, разумно ограничено.

И дело касается не только наполнения RAM, но и её освобождения. Например, в Tachyon на очистку 7 Тбайт RAM ушло больше часа, а ведь это время тоже учитывается в итоговом результате. С другой стороны, давно у вас была возможность получить такой объём памяти для такой большой визуализации? Как вам, например, чайник Ньюэлла на 640 Гпикс? Шутки шутками, но не всегда есть возможность эффективно разнести даже рендеринг хотя бы на несколько узлов.
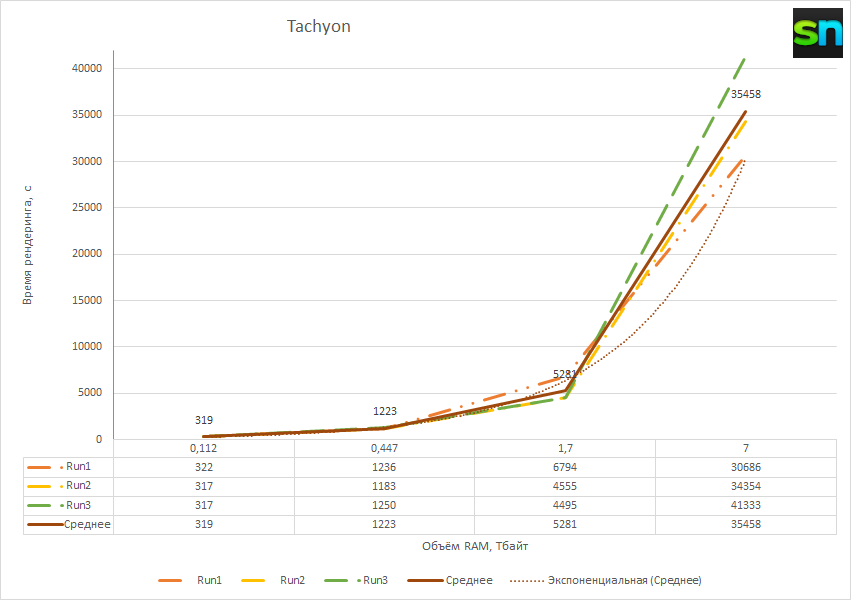
Собственно, Tachyon — это классический движок для рендеринга с использованием трассировки лучей, который весьма популярен в качестве инструмента для визуализации различных моделей в научной среде. Для теста была взята актуальная версия 0.99b6, собранная в варианте linux-64-thr из комплектного Makefile. Она использовалась для простейшего рендеринга демомодели teapot.dat в разрешении n00000 × n00000 пикселей, где n было равно 1, 2, 4 и 8. Результат на диск не сохранялся, так что основная нагрузка была именно на оперативную память.
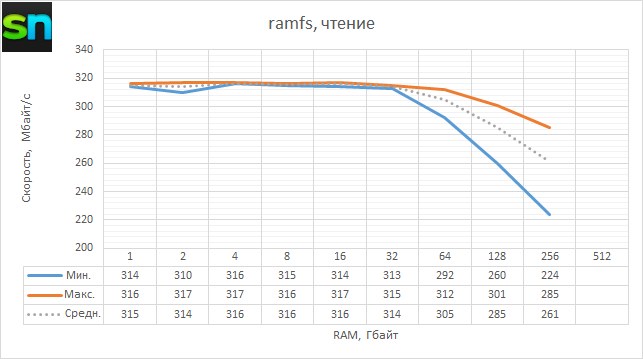
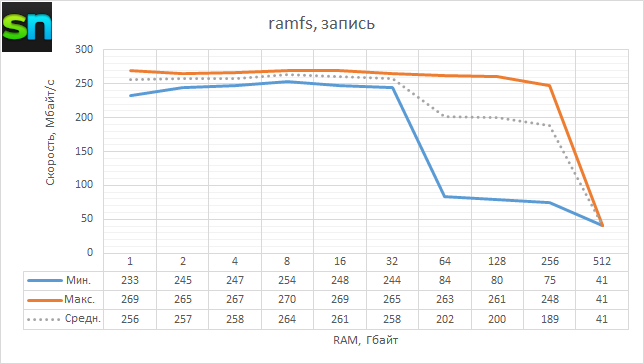
А какова вообще скорость работы с RAM? Простой тест с копированием блоками по 4 Кбайт из /dev/zero в ramfs и из ramfs в /dev/null, выполненный три раза для каждого направления, показал следующее. Во-первых, до объёма 32 Гбайт скорость чтения и записи остаётся примерно одинаковой: около 315 Мбайт/с и 260 Мбайт/с соответственно, что довольно скромно. После 32 Гбайт скорость не просто постепенно падает — первый проход оказывается намного медленнее последующих, что как раз похоже на обещанную «обучаемость» гипервизора на лету. Увы, на 512 Гбайт удалось лишь один раз записать данные, после чего ВМ по неизвестной причине упала. И на этом наше время доступа к HyperServer истекло.
Заключение
Пожалуй, окончательных и безапелляционных выводов прямо сейчас делать не будем. Во-первых, и технология далеко не массовая, и тестирование далеко не полное в силу временных ограничений. Это же привело и к отсутствию возможных оптимизаций, тогда как сами разработчики рекомендуют тюнинговать настройки и ПО, и «железа» под конкретную задачу и набор/объём данных. Во-вторых, сам HyperServer отнесен Selectel к категории индивидуальных решений.
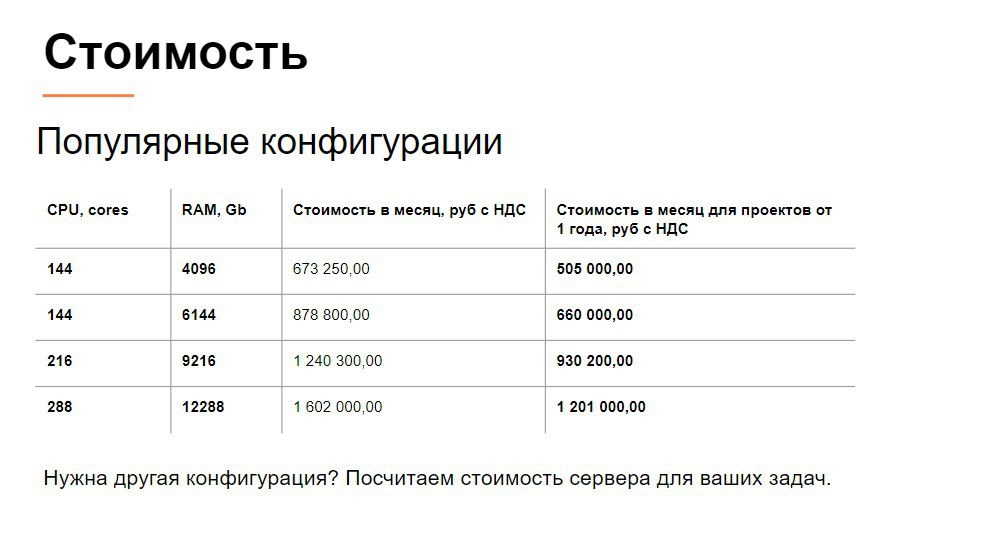
Цены на HyperServer…
Так что наиболее общий вывод может прозвучать на первый взгляд странно: оно действительно существует и работает! Собственно HyperServer, являясь уникальной для российского рынка услугой, тесно связан с другой, такой же нечастой возможностью аренды четырёхсокетных серверов. На данный момент заявлена возможность масштабирования вплоть до 512 ядер и 48 Тбайт RAM с объединением от 4 до 16 физических узлов.
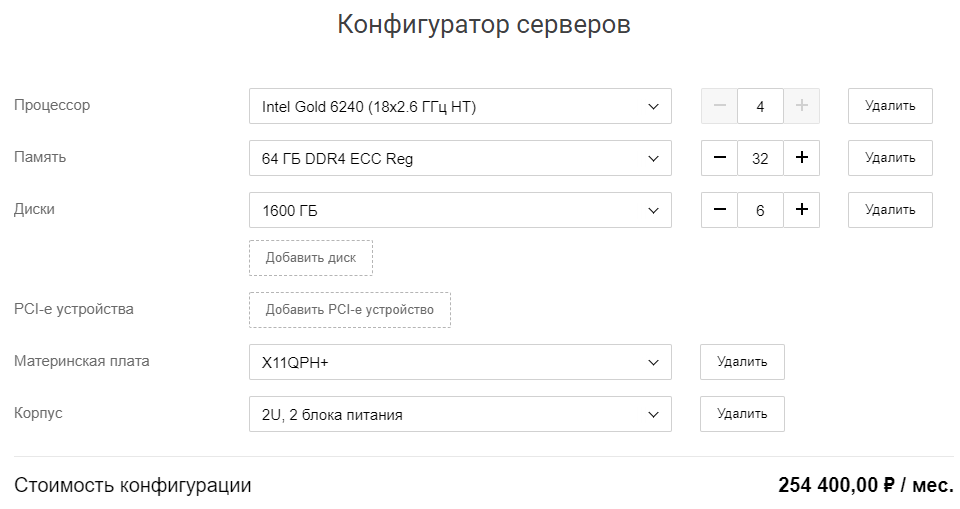
… и примерная стоимость аренды одного узла младшей конфигурации
Сама возможность аренды делает такие технологии доступней. Если верить словам представителя SAP, когда в рамках одного из проектов потребовалась тестовая система с «всего-то» 6 Тбайт RAM, оказалось, что в России в принципе нет таких систем даже для временного использования — все подобные машины собираются под конкретных заказчиков в индивидуальном порядке.

