Команда разработчиков «Яндекса» опубликовала исходный код масштабируемой платформы распределённого хранения и обработки больших данных YTsaurus.
YTsaurus разрабатывается компанией с 2010 года и является одним из ключевых элементов внутренней IT-инфраструктуры «Яндекса». В основу платформы положен набор связных подсистем: MapReduce, движок SQL-запросов, планировщик, KV-хранилище данных для OLTP. YTsaurus поддерживает работу с десятками тысяч серверов, обработку эксабайтов данных на разных носителях, а также интеграцию с ClickHouse и Apache Spark. Благодаря широкой функциональности платформа может быть использована для широкого круга задач — от аналитики и построения хранилищ данных до обучения сложных ИИ-моделей с миллиардами параметров.
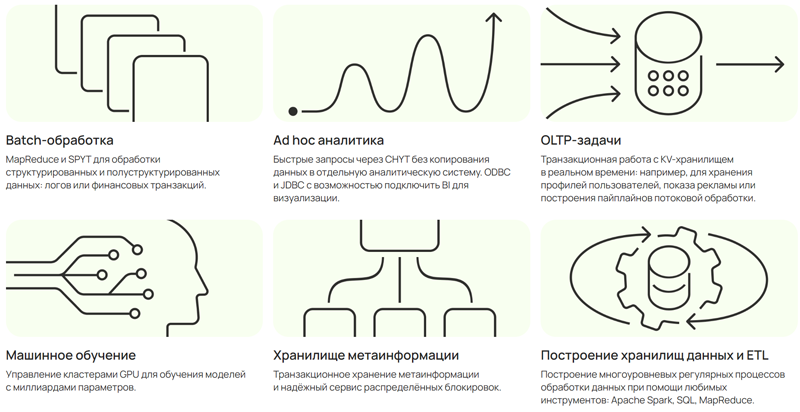
Сценарии использования YTsaurus
«Платформа YTsaurus отлично зарекомендовала себя в «Яндексе». Теперь мы сделали её доступной и за его пределами. Наибольшую пользу YTsaurus может принести крупным компаниям, которые обрабатывают гигантские объёмы данных на тысячах серверов в условиях постоянно возрастающей нагрузки. Мы уверены, что публикация кода выведет платформу на новый виток развития, как это уже было с другими нашими продуктами», — отмечает «Яндекс».
Исходный код и документация YTsaurus доступны на площадке GitHub. Код распространяется под лицензией Apache 2.0. Использовать платформу или доработать её под себя может любой желающий.
Источник:

