⇡#Графические процессоры NVIDIA – в десятке лидеров Green500
Рассказать действительно есть о чём, и начнём мы с наиболее впечатляющего события: впервые в истории публикации мирового списка самых энергоэффективных суперкомпьютеров мира Green500 вся первая десятка лидирующих систем без исключения построена на графических процессорах NVIDIA Tesla. Ранее такого бескомпромиссного успеха удавалось добиться только легендарной архитектуре IBM BlueGene.
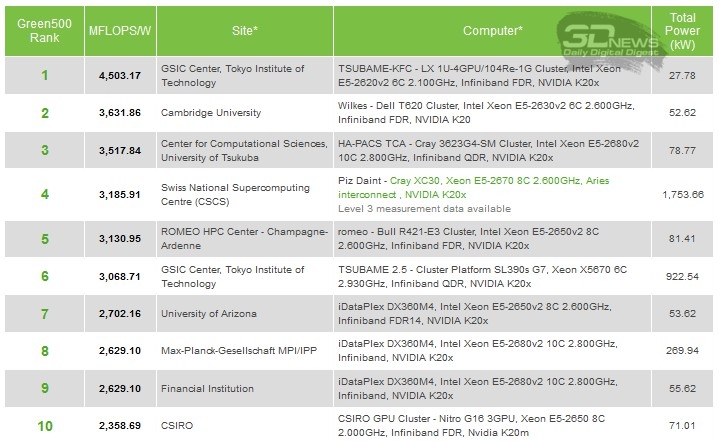
Рассмотрим внимательно самый последний рейтинг Green500: самым «зелёным» суперкомпьютером планеты отныне названа система Tsubame-KFC с рекордным показателем 4,5 Гфлопс/Вт, созданная в Токийском технологическом институте. Система Wilkes из Кембриджского университета, занимающая в рейтинге вторую строчку, отстаёт от лидера со своими 3,6 Гфлопс/Вт почти на четверть! Замыкает тройку лидеров система японского Центра вычислительных наук при университете Цукуба с близким ко второму показателем 3,5 Гфлопс/Вт.

Важно отметить, что в предыдущем летнем рейтинге Green500 в десятку лучших входили лишь две системы с графическими ускорителями NVIDIA. Таким образом, факт налицо: основной причиной роста популярности решений NVIDIA можно считать начало широкого внедрения ускорителей на чипах NVIDIA Tesla с микроархитектурой Kepler, которые значительно превосходят по производительности и втрое экономичнее предшественников на базе архитектуры Fermi.
В десятку самых производительных суперкомпьютеров мира последней версии TOP500 на сегодняшний день входит две системы с ускорителями Tesla K20X, при этом вторую строчку самого престижного рейтинга суперкомпьютеров планеты занимает модель Titan на базе систем Cray XK7 с ускорителями NVIDIA K20x.
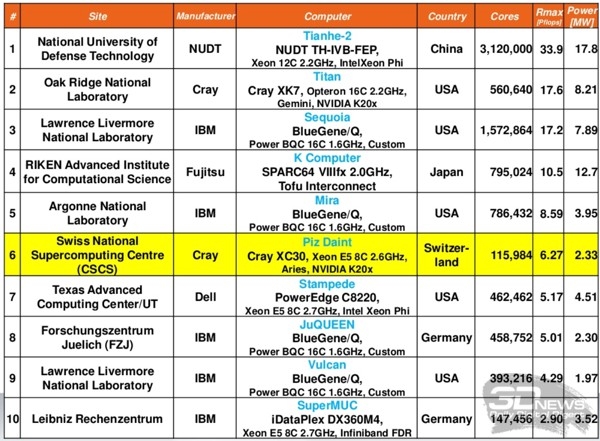
Однако наиболее удивительным и впечатляющим стоит назвать появление на шестой строчке TOP500 и одновременно на четвёртой строчке Green500 совершенно новой системы Piz Daint, названной так в честь одного из пиков Швейцарских Альп и установленной в Швейцарском национальном супервычислительном центре (CSCS).
Впервые о создании этой системы с GPU-ускорением было объявлено в марте 2013 года на конференции по графическим технологиям NVIDIA GTC 2013, и уже в ноябре швейцарский суперкомпьютер достиг пиковой производительности в 6,2 Пфлопс в бенчмарке LINPACK, став, таким образом, самым быстрым суперкомпьютером в Европе.


В плане энергоэффективности эта система также поставила рекорд, став первой системой петафлопсного уровня, преодолевшей барьер 3 Гфлопс/Вт.

Одно из основных приложений, для работы с которыми была построена система Piz Daint, создано консорциумом COSMO (Consortium for Small-scale Modeling) — оно представляет собой метеорологическую модель, которую используют немецкая метеослужба German Meteorological Service, швейцарская MeteoSwiss и другие службы для ежедневных прогнозов погоды. В COSMO, кстати, входят национальные метеослужбы таких стран, как Германия, Швейцария, Италия, Польша, Греция, Румыния и Россия (Росгидромет), а также исследовательские группы из почти 50 университетов мира. Впрочем, не факт, что Росгидромет использует ресурсы COSMO, — для расчётов у него достаточно своих мощностей, а вот алгоритмы предсказания погоды, вполне возможно, совершенствуются на взаимной основе.

Возвращаясь к рейтингу TOP500, необходимо упомянуть, что в новую версию также впервые вошли ещё три европейские системы с GPU-ускорением, ориентированные на научные исследования. Одна из них находится в вычислительном центре Rechenzentrum Garching, принадлежащем обществу имени Макса Планка и Институту физики плазмы имени Макса Планка, и обладает производительностью 709 Тфлопс. Другие новички рейтинга – это система Romeo из французского университета Реймса и система Wilkes из Кембриджского университета.
⇡#NVIDIA Tesla K40 – новый флагманский ускоритель для HPC
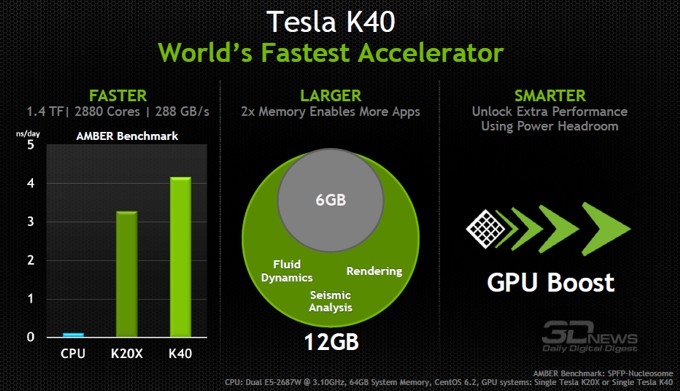
В рамках конференции SC’13 компания NVIDIA не ограничилась почиванием на лаврах новых рейтингов — был представлен действительно новый прогрессивный продукт для современных суперкомпьютерных решений. Графический процессор NVIDIA Tesla K40 – отныне самый мощный в мире, обладает вдвое большим объемом памяти и на 40% быстрее предшественника, Tesla K20X.


Благодаря технологии NVIDIA GPU Boost, которая преобразует не используемую в данный момент энергию в контролируемую пользователем дополнительную производительность, процессор Tesla K40 позволяет раскрыть потенциал широкого спектра приложений.
Графический процессор Tesla K40 основан на архитектуре NVIDIA Kepler и обладает следующими ключевыми возможностями:
- Поддержка 12 Гбайт памяти GDDR5;
- Наличие 2880 параллельных ядер CUDA;
- Поддержка динамического параллелизма с целью динамического создания GPU-потоками новых потоков для быстрой работы с адаптивными и динамическими структурами данных;
- Поддержка интерфейса PCIe 3.0.
На выставке был представлен демонстрационный стенд для испытаний ускорителя Tesla K40 на удаленном кластере.


Кроме того, уже в дни проведения SC’13 о планах по развертыванию интерактивной дистанционной системы визуализации и анализа данных Maverick на базе ускорителей NVIDIA Tesla K40 объявил вычислительный центр Техаса (TACC) при Техасском университете в Остине. Ожидается, что система Maverick заработает в полном объеме в январе 2014 года.
О доступности для заказа серверных решений с ускорителями NVIDIA Tesla K40 в дни конференции объявили такие компании, как Appro, ASUS, Bull, Cray, Dell, Eurotech, HP, IBM, Inspur, SGI, Sugon, Supermicro, Tyan и огромный список партнеров-реселлеров NVIDIA. Впрочем, по нашим собственным впечатлениям, на выставке SC’13 было огромное число стендов с партнёрской табличкой NVIDIA и образцом новёхонького Tesla K40.
⇡#На стенде NVIDIA: анонс CUDA 6 и другие интересные события
На выставочном стенде компании NVIDIA в дни выставки было просто не протолкнуться, особенно в часы лекций, коих ежедневно проводилось изрядное количество.


Что интересно отметить, большинство презентаций проводилось отнюдь не сотрудниками самой NVIDIA, а её стратегическими партнёрами, главным образом – представителями научных учреждений, где используются системы на базе ускорителей NVIDIA Tesla.


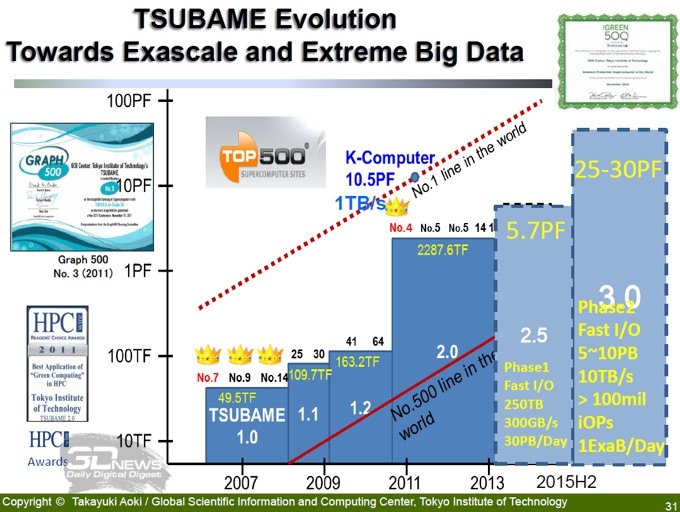
Несмотря на жуткий дефицит времени, типичный, впрочем, для скоротечных часов конференций, мне удалось не без удовольствия задержаться и выслушать несколько докладов, действительно интересных в силу их эксклюзивности. Так, представители Токийского технологического института с удовольствием рассказали о своём рекордсмене рейтинга Green500, суперкомпьютере Tsubame-KFC, и поделились планами на ближайшее будущее.



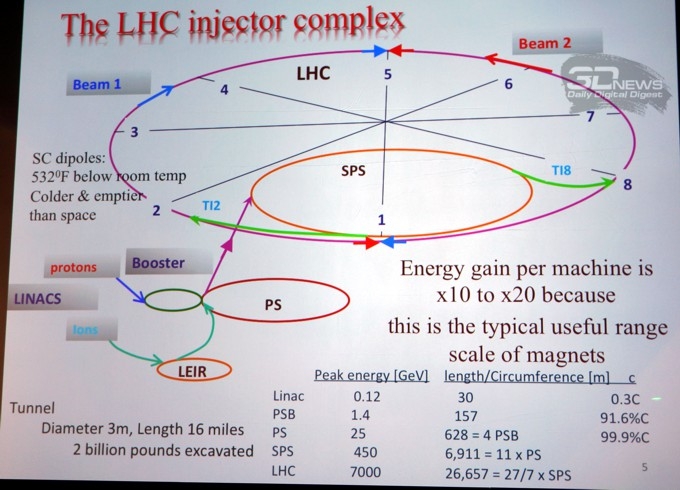
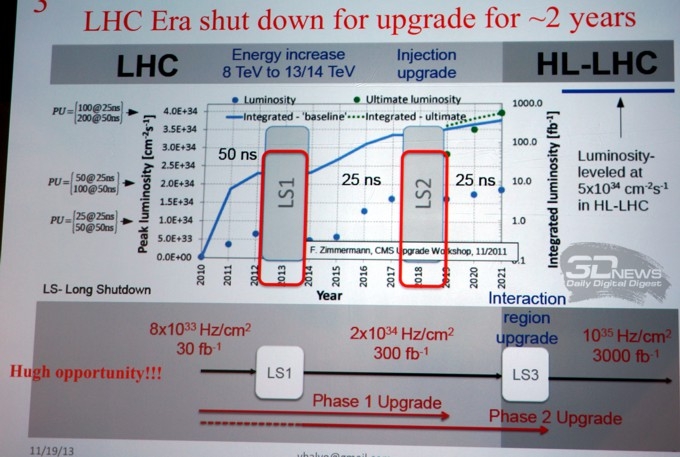
В свою очередь представительница научного коллектива Большого адронного коллайдера со вкусом рассказала о вопросах, стоящих перед сотрудниками самого крупного ускорителя планеты, и о методах решения этих задач.




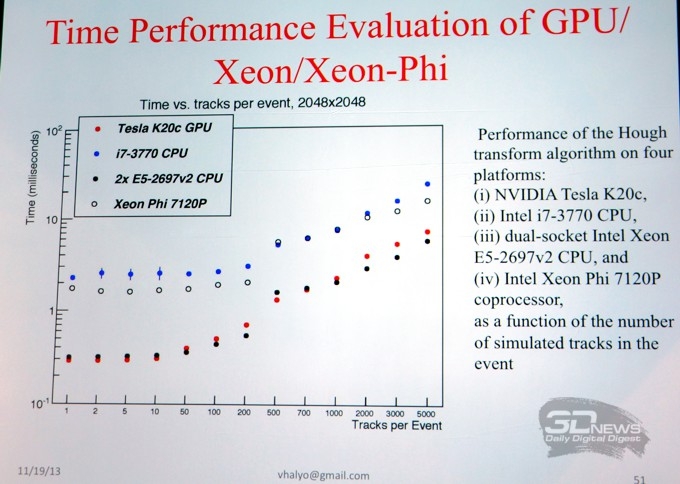
Из лекций, озвученных непосредственно представителями NVIDIA, мне удалось прослушать ту, что была посвящена официально представленной лишь днём ранее новой, 6-й версии платформы параллельных вычислений и модели программирования NVIDIA CUDA.




Марк Харрис (Mark Harris) в подробностях рассказал о преимуществах параллельного программирования с применением CUDA 6, о её новых возможностях, включающих:
- Поддержку унифицированной памяти, упрощающей программирование и обеспечивающей приложениям доступ к памяти CPU и GPU без необходимости ручного копирования данных из одной памяти в другую;
- Интегрируемые библиотеки, автоматически ускоряющие вычисления BLAS и FFTW в приложениях до 8 раз путем простой замены существующих CPU-библиотек GPU-ускоряемыми эквивалентами;
- Многопроцессорное масштабирование с изменёнными GPU-библиотеками BLAS и FFT, автоматически масштабирующее производительность системы при добавлении до 8 GPU и обеспечивающее скорость вычислений двойной точности более 9 терафлопс, а также поддерживающее большие нагрузки (до 512 Гбайт).
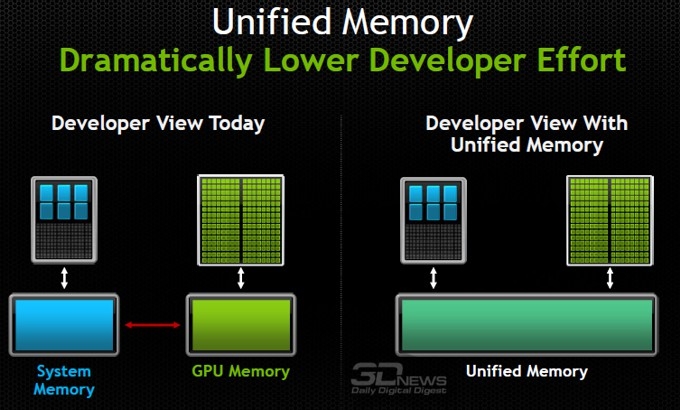
Помимо вышеперечисленных возможностей, платформа CUDA 6 включает полный набор инструментов программирования, GPU-ускоренные математические библиотеки, документы и инструкции по программированию. Шестая версия Toolkit CUDA будет представлена в начале 2014 года.
Интересно отметить, что новые технологии, заложенные в CUDA 6, не только помогут ускорить суперкомпьютерные вычисления, но и будут востребованы крупными студиями, разработчиками игр и дизайнерами в создании визуально привлекательных 3D-анимаций и эффектов. Так, например, унифицированная память автоматизирует процесс, направляя компилятор Fabric на графические процессоры NVIDIA, и ускоряет работу отдельных приложений до 10 раз.
⇡#IBM: новый стратегический партнёр NVIDIA
Список стратегических партнёров компании NVIDIA в сфере использования технологий GPU-ускорения для суперкомпьютерных и корпоративных вычислений давно включает множество крупнейших лидеров индустрии, таких как Cray, SGI, HP, Dell, Bull, Eurotech и другие. Тем интереснее было услышать о впервые объявленном официально именно в рамках конференции SC’13 сотрудничестве NVIDIA и IBM. Отныне ускорители NVIDIA будут применяться в самом широком спектре корпоративных приложений на системах IBM Power.

Напомним, что впервые о партнёрстве между NVIDIA и IBM было рассказано в конце лета 2013-го в дни консорциума OpenPOWER — тогда IBM, NVIDIA, Google, Mellanox и Tyan сообщили о совместных планах по созданию открытой экосистемы на базе архитектуры IBM Power. Теперь к этому добавляется сотрудничество NVIDIA и IBM с целью объединения вычислительных возможностей графических процессоров NVIDIA Tesla и процессоров IBM Power 8, что, как ожидается, найдёт применение в исследовании космоса, расшифровке генома человека и ускорении вывода различных продуктов на рынок.

Системы на базе IBM Power будут полностью поддерживать существующие научные и инженерные приложения, а также программы визуализации, разработанные с помощью архитектуры NVIDIA CUDA для HPC-систем. IBM также планирует предоставить свои инструменты разработки корпоративных приложений Rational разработчикам суперкомпьютерных приложений для более быстрой адаптации наиболее передовых программ.
Выставка SC’13: решения NVIDIA на стендах партнёров
А сейчас – самое время совершить виртуальную прогулку по стендам упомянутых выше или ещё вовсе не упомянутых компаний. Очень трудно перечислить всех представителей партнёрских программ NVIDIA с учебными и научными коллективами мира — их на выставке было огромное количество.


Стенд компании Supermicro: самые разные конфигурации систем и модулей с поддержкой ускорителей NVIDIA Tesla под любой каприз заказчика.



На выставке было на удивление много китайских и тайваньских компаний, представляющих тем не менее серьёзные решения для рынка устройств класса HPC.


Стенд компании Cray, поставщика тех самых лидерских решений для топовых рейтингов.


Небольшой фрагмент стенда компании SGI.

Компания Fujitsu также является близким стратегическим партнёром NVIDIA.

Стенд компании HP с восьмым поколением масштабируемых систем ProLiant SL6500 с ускорителями NVIDIA Tesla.



Стенд компании Dell. На нижнем фото – та самая система, на которой собран демонстрационный стенд для испытаний ускорителя NVIDIA Tesla K40 на удаленном кластере.



Стенд компании Eurotech и её универсальные платы для ускорителей NVIDIA и сопроцессоров Intel.


Французская компания Bull, поставщик многих оригинальных разработок на графических ускорителях NVIDIA.

В завершение нашего сегодняшнего репортажа позвольте мне поделиться ещё одним, смею надеяться, немаловажным впечатлением, вынесенным по итогам SC’13 за скобки. В рамках конференции SC’13 на выставочных стендах разных компаний – где по отдельности, где парами — красовались партнёрские логотипы графических ускорителей NVIDIA Tesla и сопроцессоров Intel Xeon Phi. В этот раз, скажу точно, стендов с такими логотипами было подавляющее большинство, причём преимущественно – именно с обоими логотипами
Сейчас мне хотелось бы предостеречь любителей «войнушек» в стиле «AMD vs INTEL», «ATI vs NVIDIA» и прочих страстей в стиле «Кит vs Слон», а также любителей причудливых скороспелых «аналитических гипотез» в попытке противопоставления этих двух решений. На самом деле всё гораздо проще и в то же время сложнее. Прежде всего, не стоит забывать, что ускорители NVIDIA и сопроцессоры Intel имеют совершенно разную архитектуру, со своей уникальной обвязкой, интерфейсами, системами команд и так далее. Более того: несмотря на общую главную цель – а именно качественное ускорение параллельных вычислений, для этого самого распараллеливания и создания качественного программного кода в каждом случае используются различные методики, библиотеки, компиляторы. В результате мы имеем для каждого решения огромный прирост вычислительной мощности, плотности вычислительной мощности, эффективности вычислительной мощности при решении одних задач и совершенно скромный результат в другом случае.
Так вот, в этой связи интересно и немаловажно отметить, что каждый мой собеседник в дни конференции, каждый докладчик на презентации не просто декларировал поддержку ускорителей NVIDIA или сопроцессоров Intel Xeon Phi, но в каждом отдельном случае чётко аргументировал свой выбор подробными графиками, цифрами, статистикой, практическими результатами сравнения производительности различных вариантов, потенциально подходящих для решения определённого типа задач.
Иными словами, конфигурации на базе ускорителей NVIDIA Tesla и сопроцессоров Intel Xeon Phi отныне будут предлагать все или почти все игроки рынка HPC, но ни в коем случае нельзя сравнивать эти совершенно разные решения по числу ядер, процессоров, конвейеров, тактовым частотам или чему бы то ни было напрямую, в лоб. На мой взгляд, гораздо практичнее и умнее говорить сегодня о расширении списка доступных инструментов и блоков для конструирования суперкомпьютерных систем, нежели о какой-либо конкуренции. Скорее мы увидим решения, включающие одновременно и NVIDIA Tesla, и Intel Xeon Phi. Тем более что в такой серьёзной области, как суперкомпьютерные вычисления, ни «горлом», ни авторитетом, ни рекламой вопросы не решаются: до принятия окончательного решения всё многократно подсчитывается и перепроверяется на практике.
Что касается дальнейших перспектив решений на базе графических ускорителей NVIDIA, то здесь ещё, как говорится, поле непаханое. Так, вслед за интеграцией с процессорами IBM Power 8, ускорители NVIDIA Tesla вполне могут рассчитывать на место в серверах с процессорами ARM или даже (почему бы и нет?) с процессорами Fujitsu Sparc. Поживём – увидим!


