Материалы по тегу: nvidia
|
15.05.2024 [14:18], Руслан Авдеев
PUE у вас неправильный: NVIDIA призывает пересмотреть методы оценки энергоэффективности ЦОД и суперкомпьютеровОператорам дата-центров и суперкомпьютеров не хватает инструментов для корректного измерения энергоэффективности их оборудования и оценки прогресса на пути к экоустойчивым вычислениям. Как утверждает NVIDIA, нужна нова система оценки показателей при использовании оборудования в реальных задачах. Для оценки эффективности ЦОД существует как минимум около трёх десятков стандартов, некоторые уделяют внимание весьма специфическим критериям вроде расхода воды или уровню безопасности. Сегодня чаще всего используется показатель PUE (power usage effectiveness), т.е. отношение энергопотребления всего объекта к потреблению собственно IT-инфраструктуры. В последние годы многие операторы достигли практически идеальных значений PUE, поскольку, например, на преобразование энергии и охлаждение нужно совсем мало энергии. В эпоху роста облачных сервисов оценка PUE показала довольно высокую эффективность, но в эру ИИ-вычислений этот индекс уже не вполне соответствует запросам отрасли ЦОД — оборудование заметно изменилось. NVIDIA справедливо отмечает, что PUE не учитывает эффективность инфраструктуры в реальных нагрузках. С таким же успехом можно измерять расход автомобилем бензина без учёта того, как далеко он может проехать без дозаправки. При этом среднемировой показатель PUE дата-центров остаётся неизменным уже несколько лет, а улучшать его всё дороже. 
Источник изображений: NVIDIA Что касается энергопотребления, разное оборудование при одинаковых затратах может давать самые разные результаты. Другими словами, если современные ускорители потребляют больше энергии, это не значит, что они менее эффективны, поскольку они дают несопоставимо лучший результат в сравнении со старыми решениями. NVIDIA неоднократно приводила подобные сравнения и между своими GPU с обычными CPU, а теперь предлагает распространить этот подход на ЦОД целиком, что справедливо, учитывая стремление NVIDIA сделать минимальной единицей развёртывания целую стойку. 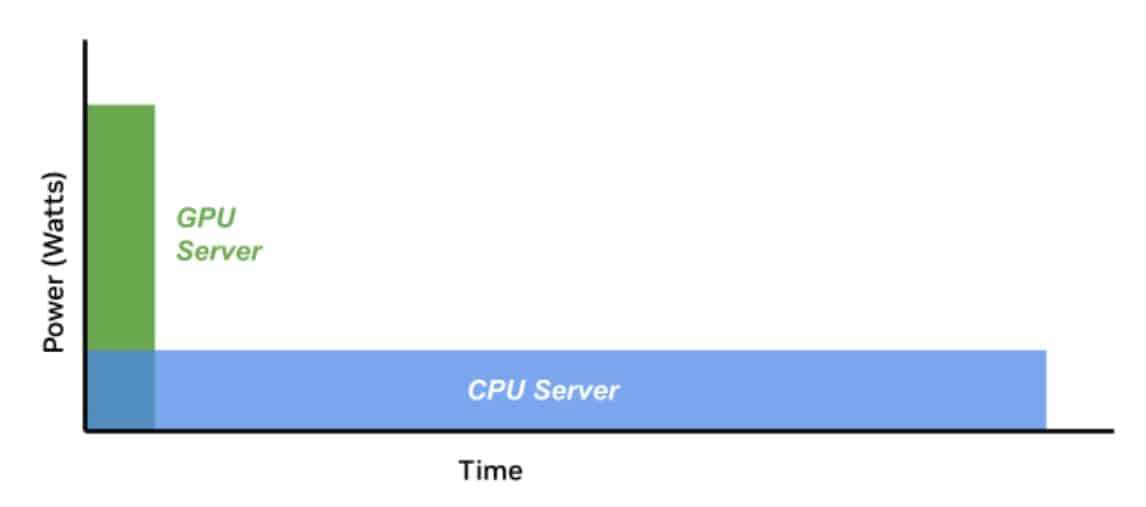 Как считают в NVIDIA, оценивать качество ЦОД можно только с учётом того, сколько энергии тратится для получения результата. Так, ЦОД для ИИ могут полагаться на MLPerf-бенчмарки, суперкомпьютеры для научных исследований могут требовать измерения других показателей, а коммерческие дата-центры для стриминговых сервисов — третьих. В идеале бенчмарки должны измерять прогресс в ускоренных вычислениях с использованием специализированных сопроцессоров, ПО и методик. Например, в параллельных вычислениях GPU намного энергоэффективнее обычных процессоров Не так давно эксперты Стэнфордского университета отметии, что с 2003 года производительность ускорителей выросла приблизительно в 7 тыс. раз, а соотношение цены и производительности стало в 5,6 тыс. раз лучше. А с учётом того, что современные ЦОД достигли PUE на уровне приблизительно 1,2, подобная метрика практически исчерпала себя, теперь стоит ориентироваться на другие показатели, релевантные актуальным проблемам. Хотя напрямую сравнить некоторые аспекты невозможно, сегментировав деятельность ЦОД на типы рабочих нагрузок, возможно, удалось бы получить некоторые результаты. В частности, операторам ЦОД нужен пакет бенчмарков, измеряющих показатели при самых распространённых рабочих ИИ-нагрузках. Например, неплохой метрикой может стать Дж/токен. Впрочем, NVIDIA грех жаловаться на недостойные оценки — в последнем рейтинге Green500 именно её системы заняли лидерские позиции.
13.05.2024 [11:12], Сергей Карасёв
Supermicro представила ИИ-серверы на базе Intel Gaudi3 и AMD Instinct MI300XКомпания Supermicro анонсировала новые серверы для задач ИИ и НРС. Дебютировали системы высокой плотности с жидкостным охлаждением, а также устройства, оборудованные высокопроизводительными ускорителями AMD, Intel и NVIDIA. 
Источник изображений: Supermicro В частности, представлены серверы SYS-421GE-TNHR2-LCC и AS-4125GS-TNHR2-LCC в форм-факторе 4U, оснащённые СЖО. Первая из этих моделей рассчитана на установку двух процессоров Intel Xeon Emerald Rapids или Xeon Sapphire Rapids (до 385 Вт), а также 32 модулей DDR5-5600. Второй сервер поддерживает два чипа AMD EPYC 9004 Genoa с показателем TDP до 400 Вт и 24 модуля DDR5-4800.  Обе новинки могут быть оборудованы восемью ускорителями NVIDIA H100 (SXM). В одной стойке могут размещаться до восьми серверов, что в сумме даст 64 ускорителя. При этом общая заявленная производительность такого кластера на операциях FP16 превышает 126 Пфлопс. Серверы оборудованы восемью фронтальными отсеками для SFF-накопителей NVMe. Питание обеспечивают четыре блока мощностью 5250 Вт с сертификатом Titanium. Слоты расширения выполнены по схеме 8 × PCIe 5.0 x16 LP и 2 × PCIe 5.0 x16 FHHL.  На ISC 2024 компания Supermicro также демонстрирует сервер типоразмера 8U, оборудованный ускорителями Intel Gaudi3. Это одна из первых систем такого рода. Кроме того, представлена система AS-8125GS-TNMR2 формата 8U, рассчитанная на восемь ускорителей AMD Instinct MI300X. Этот сервер может комплектоваться двумя процессорами EPYC 9004 с TDP до 400 Вт, 24 модулями оперативной памяти DDR5-4800, фронтальными накопителями SFF (16 × NVMe и 2 × SATA), двумя модулями M.2 NVMe. Установлены шесть блоков питания на 3000 Вт с сертификатом Titanium. Наконец, Supermicro готовит серверы формата 4U с жидкостным охлаждением, которые могут оснащаться восемью ускорителями NVIDIA H100 и H200. Компания демонстрирует на конференции ISC 2024 и другие системы для приложений ИИ, а также задач НРС.
13.05.2024 [09:00], Сергей Карасёв
Более 200 Эфлопс для ИИ: NVIDIA представила новые НРС-системы на суперчипах Grace HopperКомпания NVIDIA рассказала о новых высокопроизводительных комплексах на основе суперчипов Grace Hopper для задач ИИ и НРС. Отмечается, что суммарная производительность этих систем превышает 200 Эфлопс. Суперкомпьютеры предназначены для решения самых разных задач — от исследований в области изменений климата до сложных научных проектов. Одним из таких НРС-комплексов является EXA1 — HE, который является совместным проектом Eviden (дочерняя структура Atos) и Комиссариата по атомной и альтернативным видам энергии Франции (СЕА). Система использует 477 вычислительных узлов на базе Grace Hopper, а пиковое быстродействие достигает 104 Пфлопс. Ещё одной системой стал суперкомпьютер Alps в Швейцарском национальном компьютерном центре (CSCS). Он использует в общей сложности 10 тыс. суперчипов Grace Hopper. Заявленная производительность на операциях ИИ достигает 10 Эфлопс, и это самый быстрый ИИ-суперкомпьбтер в Европе. Утверждается, что по энергоэффективности Alps в 10 раз превосходит систему предыдущего поколения Piz Daint. 
Источник изображений: NVIDIA В свою очередь, комплекс Helios, созданный компанией НРЕ для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша), содержит 440 суперчипов NVIDIA GH200 Grace Hopper. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс.  В список систем на платформе Grace Hopper также входит Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Комплекс расположится в Юлихском исследовательском центре (FZJ) в Германии. Кроме того, в список вошёл комплекс DeltaAI на основе GH200 Grace Hopper, созданием которого занимается Национальный центр суперкомпьютерных приложений (NCSA) при Университете Иллинойса в Урбане-Шампейне (США).  В числе прочих систем названы суперкомпьютер Miyabi в Объединённом центре передовых высокопроизводительных вычислений в Японии (JCAHPC), Isambard-AI в Бристольском университете в Великобритании (5280 × GH200), а также суперкомпьютер в Техасском центре передовых вычислений при Техасском университете в Остине (США), комплекс Venado в Лос-Аламосской национальной лаборатории США (LANL) и суперкомпьютер Recursion BioHive-2 (504 × H100).
13.05.2024 [09:00], Сергей Карасёв
NVIDIA представила гибридные квантовые системы на платформе CUDA-QКомпания NVIDIA сообщила о том, что её платформа CUDA-Q будет использоваться в суперкомпьютерных центрах по всему миру. Она поможет ускорить исследования в области квантовых вычислений, что в перспективе позволит решать наиболее сложные научные задачи. Технология CUDA-Q предназначена для интеграции CPU, GPU и квантовых процессоров (QPU) и разработки приложений для них. Она даёт возможность выполнять сложные симуляции квантовых схем. О намерении использовать CUDA-Q в составе своих НРС-систем объявили организации в Германии, Японии и Польше. В частности, Юлихский суперкомпьютерный центр в Германии (JSC) намерен использовать квантовое решение производства IQM Quantum Computers в качестве дополнения к Jupiter — первому европейскому суперкомпьютеру экзафлопсного класса. Этот комплекс будет смонтирован в Юлихском исследовательском центре (FZJ). Суперкомпьютер Jupiter получит приблизительно 24 тыс. гибридных суперчипов NVIDIA GH200 Grace Hopper. 
Источник изображений: NVIDIA Ещё одной гибридной системой, объединяющей классические и квантовые технологии, станет комплексе ABCI-Q, который расположится в суперкомпьютерном центре ABCI (AI Bridging Cloud Infrastructure) Национального института передовых промышленных наук и технологий Японии (AIST). В состав суперкомпьютера войдут QPU разработки QuEra, а также более 2000 ускорителей NVIDIA H100. Ввод ABCI-Q в эксплуатацию состоится в начале 2025 года. Применять систему планируется при проведении исследований в области ИИ, энергетики, биологии и пр.  Вместе с тем Познаньский центр суперкомпьютерных и сетевых технологий (PSNC) в Польше приобрёл две квантовые вычислительные системы британской компании ORCA Computing. Они интегрированы в существующую HPC-инфраструктуру PSNC, которая в числе прочего использует изделия NVIDIA Hopper. Узлы на базе QPU помогут в решении задач в области химии, биологии и машинного обучения.
12.05.2024 [21:57], Сергей Карасёв
ИИ федерального значения: правительственные учреждения США получат 17-Пфлопс суперкомпьютер на базе NVIDIA DGX SuperPOD H100Компания NVIDIA сообщила о том, что её система DGX SuperPOD ляжет в основу нового вычислительного комплекса для задач ИИ, который будет использоваться различными правительственными учреждениями США для проведения исследований в области климатологии, здравоохранения и кибербезопасности. Внедрением суперкомпьютера занимается MITRE — американская некоммерческая организация, специализирующаяся в области системной инженерии. Она ведёт разработки и исследования в интересах госорганов США, включая Министерство обороны (DoD), Федеральное управление гражданской авиации (FAA) и пр. Система DGX SuperPOD станет основой вычислительной платформы MITRE Federal AI Sandbox, доступ к ресурсам которой будет предоставляться различным организациям на федеральном уровне. Государственные учреждения смогут сообща использовать суперкомпьютер для обучения больших языковых моделей (LLM), развёртывания генеративных приложений и других современных ИИ-решений. 
Источник изображения: NVIDIA В состав MITRE Federal AI Sandbox войдут 32 системы NVIDIA DGX H100, а общее количество ускорителей NVIDIA H100 составит 256 штук. Производительность на операциях ИИ будет достигать примерно 1 Эфлопс. Быстродействие FP64 — приблизительно 17 Пфлопс. Ввод суперкомпьютера в эксплуатацию состоится позднее в текущем году. «Развёртывание MITRE DGX SuperPOD поможет ускорить реализацию инициатив федерального правительства США в области ИИ. Технологии ИИ обладают огромным потенциалом для улучшения государственных услуг в гражданской области и решения серьёзных проблем, в том числе в сфере кибербезопасности», — сказал Энтони Роббинс (Anthony Robbins), вице-президент NVIDIA.
10.05.2024 [23:47], Сергей Карасёв
Eviden представила семейство ИИ-серверов BullSequana AIКомпания Eviden (дочерняя структура Atos) анонсировала серверы серии BullSequana AI, предназначенные для решения ИИ-задач. В зависимости от модификации и уровня производительности устройства подходят для различных сценариев использования — от НРС-платформ до периферийных вычислений. Наиболее производительными серверами семейства являются решения BullSequana AI 1200H. Они могут применяться в составе облачных и гибридных инфраструктур, а также в дата-центрах заказчиков. По сути, это суперкомпьютер корпоративного уровня, специально разработанный для ресурсоёмких задач, таких как точная настройка ИИ-систем или обучение больших языковых моделей (LLM). Конфигурация BullSequana AI 1200H включает суперчипы NVIDIA Grace Hopper, а также интерконнект NVIDIA Quantum-2 InfiniBand. Задействовано программное обеспечение Eviden Jarvice XE, Eviden Smart Energy Management Suite, Eviden Smart Management Center и NVIDIA AI Enterprise. 
Источник изображения: Eviden Серверы BullSequana AI 1200H, насчитывающие в общей сложности 1456 ускорителей NVIDIA H100, выбраны для модернизации французского суперкомпьютера Jean Zay. Производительность этого НРС-комплекса увеличится более чем в три раза — с 36,85 до 125,9 Пфлопс. Кроме того, в новое семейство серверов вошли производительные устройства BullSequana AI 800, системы BullSequana AI 600 с воздушным и гибридным охлаждением, модели BullSequana AI 200 для частных и гибридных облачных сред, а также BullSequana AI 100 для периферийных вычислений. 
Источник изображения: Eviden В целом, как отмечается, каждая модель BullSequana AI предлагает различные уровни производительности, масштабируемости и гибкости. Таким образом, заказчики могут подобрать наиболее подходящий для себя вариант в зависимости от конкретного варианта использования, бюджета и размера бизнеса.
08.05.2024 [13:24], Сергей Карасёв
ИИ-суперкомпьютер в чемодане — GigaIO представила платформу GryfКомпания GigaIO совместно с SourceCode анонсировала вычислительную систему Gryf. Это, как утверждается, первый в мире суперкомпьютер для ИИ-нагрузок, выполненный в виде чемодана на колёсиках. Изделие имеет габариты 228,6 × 355,6 × 622,3 мм и весит около 25 кг. Применяется фирменная система интерконнекта FabreX на базе PCI Express. Конфигурация Gryf предусматривает использование модулей (Sled) четырёх типов: это вычислительный узел (Compute Sled), блок ускорителя (Accelerator Sled), узел хранения (Storage Sled) и сетевой блок (Network Sled). Они могут компоноваться в различных сочетаниях, но общее количество модулей в рамках одного экземпляра Gryf не превышает шести. В состав Compute Sled входят процессор AMD EPYC 7313 Milan (16C/32T; 3,0–3,7 ГГц; 155 Вт), 256 Гбайт DDR4-3200, системный накопитель NVMe M.2 SSD вместимостью 256 Гбайт и два 100GbE-порта QSFP56/QSFP28. Может применяться ОС Linux Rocky 8/9 или Ubuntu 20/24. В свою очередь, Accelerator Sled содержит ускоритель NVIDIA L40S (48 Гбайт). Модуль Storage Sled объединяет восемь накопителей NVMe E1.L SSD суммарной вместимостью 246 Гбайт. 
Источник изображения: GigaIO Наконец, Network Sled предоставляет два разъёма QSFP56 100GbE и шесть 25GbE-портов SFP28. Вся система получает питание от двух блоков мощностью 2500 Вт каждый. Применены шесть вентиляторов охлаждения диаметром 60 мм. Диапазон рабочих температур — от 10 до +32 °C. Одно устройство Gryf обеспечивает производительность до 91,6 Тфлопс FP32, до 733 Тфлопс FP16 и до 1466 Тфлопс FP8. При этом в единый комплекс могут быть связаны до пяти экземпляров Gryf, что позволяет масштабировать быстродействие для выполнения тех или иных задач.
26.04.2024 [11:46], Сергей Карасёв
HPE построила самый мощный в Польше суперкомпьютер Helios производительностью 35 ПфлопсКомпания HPE сообщила о создании нового суперкомпьютера под названием Helios для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша). Вычислительный комплекс будет использоваться для решения ресурсоёмких задач, связанных с ИИ. На сегодняшний день Helios — самая высокопроизводительная система в Польше. Она обеспечивает теоретическую пиковую производительность на уровне 35 Пфлопс, что более чем в четыре раза превосходит показатель предыдущего флагманского суперкомпьютера Cyfronet. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс. В основу Helios положены узлы HPE Cray EX. Комплекс состоит из трёх сегментов. Один из них предназначен для традиционных вычислений, еще один — для рабочих нагрузок, связанных с обработкой больших данных. Третий сегмент оптимизирован для ИИ-задач: он использует суперчипы NVIDIA. Суперкомпьютер планируется применять при реализации проектов в области химии, медицины, создания передовых материалов, астрономии и защиты окружающей среды. Раздел общего назначения использует процессоры AMD EPYC поколения Genoa. Общее количество вычислительных ядер Zen 4 составляет 75 264, объём оперативной памяти DDR5 — 200 Тбайт. Сегмент для работы с большими данными основан на платформе HPE Cray Supercomputing XD665 с чипами EPYC Genoa, памятью DDR5-4800, быстрыми накопителями NVMe и ускорителями NVIDIA H100, суммарное количество которых равно 24. 
Источник изображения: HPE Наконец, ИИ-раздел объединяет 440 суперчипов NVIDIA GH200 Grace Hopper для компьютерного моделирования с интенсивным использованием графики, поддержки приложений на основе генеративного ИИ и пр. Все компоненты вычислительного комплекса связаны друг с другом посредством 200G-интерконнекта HPE Slingshot. Комплекс Helios оснащён Lustre-хранилищем общей вместимостью 17,5 Пбайт на базе HPE Cray ClusterStor E1000.
24.04.2024 [23:45], Владимир Мироненко
NVIDIA приобрела за $700 млн платформу оркестрации ИИ-нагрузок Run:aiКомпания NVIDIA объявила о приобретении стартапа Run:ai из Тель-Авива (Израиль), занимающегося разработкой ПО для управления рабочими нагрузками и оркестрации на базе Kubernetes, которое позволяет более эффективно использовать вычислительные ресурсы при работе с ИИ-приложениями. Стоимость сделки не раскрывается. По данным TechCrunch, покупка обошлась NVIDIA в $700 млн. Это одно из крупнейших приобретений Nvidia с момента покупки Mellanox за $6,9 млрд в марте 2019 года. Два года назад NVIDIA купила Bright Computing, разработчика решений для управления НРС-кластерами. NVIDIA отметила, что развёртывание ИИ-приложениЙ становится всё более сложным. Оркестрация генеративного ИИ, рекомендательных и поисковых систем, а также других рабочих нагрузок требует сложного планирования для оптимизации производительности. ПО Run:ai позволяет управлять и оптимизировать вычислительную инфраструктуру как локально, так и в облаке или в гибридных средах. 
Источник изображения: NVIDIA Созданная стартапом открытая платформа поддерживает все популярные варианты Kubernetes и интегрируется со сторонними инструментами и платформами ИИ. Компании из различных отраслей используют платформу Run:ai для управления кластерами ускорителей в масштабе ЦОД. Как сообщается, на относительно раннем этапе деятельности Run:ai удалось создать большую клиентскую базу из компаний из списка Fortune 500, что позволило привлечь венчурные инвестиции. Перед сделкой Run:ai привлекла капитал в размере $118 млн от ряда инвесторов, включая Insight Partners, Tiger Global, S Capital и TLV Partners. NVIDIA заявила, что в ближайшем будущем продолжит предлагать продукты Run:ai в рамках той же бизнес-модели, а также продолжит инвестировать в развитие Run:ai в рамках платформы NVIDIA DGX Cloud, предоставляющей корпоративным клиентам доступ к вычислительной инфраструктуре и ПО для обучения моделей генеративного и других форм ИИ. Решения Run:ai уже интегрированы с NVIDIA DGX, NVIDIA DGX SuperPOD, NVIDIA Base Command, контейнерами NGC, ПО NVIDIA AI Enterprise и другими продуктами. По словам NVIDIA, пользователи серверов и рабочих станций NVIDIA DGX, а также DGX Cloud также получат доступ к возможностям Run:ai, что особенно полезно при развёртывании генеративного ИИ в нескольких ЦОД.
22.04.2024 [21:30], Сергей Карасёв
Microsoft к концу 2024 года планирует использовать до 1,8 млн ИИ-ускорителей на базе GPUКорпорация Microsoft, по сообщению ресурса Business Insider, в течение 2024 года намерена утроить количество ускорителей на базе GPU в составе своей вычислительной ИИ-инфраструктуры. В результате, как ожидается, к декабрю общее количество таких изделий, находящихся в распоряжении редмондского гиганта, может достичь 1,8 млн. Два года назад у Microsoft было несколько сотен тысяч ускорителей, в том числе FPGA и ASIC. Microsoft в партнёрстве с OpenAI реализует комплексную программу по развитию ИИ-систем. В частности, планируется строительство масштабного кампуса ЦОД под названием Stargate стоимостью $100 млрд. Средства, как уточняет Business Insider, пойдут в том числе на закупку GPU-ускорителей. Аналитики DA Davidson подсчитали, что в прошлом году Microsoft потратила приблизительно $4,5 млрд на приобретение ИИ-ускорителей NVIDIA. Один из руководителей Microsoft подтвердил, что эта цифра близка к фактическим расходам корпорации в рассматриваемом сегменте. 
Источник изображения: Microsoft Microsoft также проектирует собственные ИИ-чипы, которые помогут снизить зависимость от сторонних поставщиков. Так, она уже представила свой первый ИИ-ускоритель Maia 100, который спроектирован под задачи облачного обучения и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Однако некоторые специалисты относятся скептически к этим усилиям Microsoft, поскольку корпорация на годы отстаёт от NVIDIA в плане создания мощных ИИ-решений. Business Insider со ссылкой на документацию Microsoft сообщает, что во II половине 2023-го корпорация развернула «рекордные мощности GPU». Однако конкретные цифры и тип ускорителей не раскрываются. Другие крупные IT-компании и облачные провайдеры также продолжают наращивать ИИ-ресурсы. Например, Meta✴, как ожидается, к концу 2024 года будет иметь в своём распоряжении около 350 тыс. NVIDIA H100 и неназванное количество ускорителей собственной разработки MTIA v1 и MTIA v2. Некоторые игроки рынка присматриваются к конкурирующим решениям. Так, Dell намерена использовать ИИ-ускорители Intel Gaudi3, а стартап TensorWave разворачивает ИИ-облако из 20 тыс. ускорителей AMD Instinct MI300X. |
|

