Материалы по тегу: instinct
|
13.05.2024 [11:12], Сергей Карасёв
Supermicro представила ИИ-серверы на базе Intel Gaudi3 и AMD Instinct MI300XКомпания Supermicro анонсировала новые серверы для задач ИИ и НРС. Дебютировали системы высокой плотности с жидкостным охлаждением, а также устройства, оборудованные высокопроизводительными ускорителями AMD, Intel и NVIDIA. 
Источник изображений: Supermicro В частности, представлены серверы SYS-421GE-TNHR2-LCC и AS-4125GS-TNHR2-LCC в форм-факторе 4U, оснащённые СЖО. Первая из этих моделей рассчитана на установку двух процессоров Intel Xeon Emerald Rapids или Xeon Sapphire Rapids (до 385 Вт), а также 32 модулей DDR5-5600. Второй сервер поддерживает два чипа AMD EPYC 9004 Genoa с показателем TDP до 400 Вт и 24 модуля DDR5-4800.  Обе новинки могут быть оборудованы восемью ускорителями NVIDIA H100 (SXM). В одной стойке могут размещаться до восьми серверов, что в сумме даст 64 ускорителя. При этом общая заявленная производительность такого кластера на операциях FP16 превышает 126 Пфлопс. Серверы оборудованы восемью фронтальными отсеками для SFF-накопителей NVMe. Питание обеспечивают четыре блока мощностью 5250 Вт с сертификатом Titanium. Слоты расширения выполнены по схеме 8 × PCIe 5.0 x16 LP и 2 × PCIe 5.0 x16 FHHL.  На ISC 2024 компания Supermicro также демонстрирует сервер типоразмера 8U, оборудованный ускорителями Intel Gaudi3. Это одна из первых систем такого рода. Кроме того, представлена система AS-8125GS-TNMR2 формата 8U, рассчитанная на восемь ускорителей AMD Instinct MI300X. Этот сервер может комплектоваться двумя процессорами EPYC 9004 с TDP до 400 Вт, 24 модулями оперативной памяти DDR5-4800, фронтальными накопителями SFF (16 × NVMe и 2 × SATA), двумя модулями M.2 NVMe. Установлены шесть блоков питания на 3000 Вт с сертификатом Titanium. Наконец, Supermicro готовит серверы формата 4U с жидкостным охлаждением, которые могут оснащаться восемью ускорителями NVIDIA H100 и H200. Компания демонстрирует на конференции ISC 2024 и другие системы для приложений ИИ, а также задач НРС.
10.05.2024 [11:32], Сергей Карасёв
Суперкомпьютер в стойке GigaIO SuperNODE обзавёлся поддержкой AMD Instinct MI300XКомпания GigaIO анонсировала новую модификацию системы SuperNODE для рабочих нагрузок генеративного ИИ и приложений НРС. Суперкомпьютер в стойке теперь может комплектоваться ускорителями AMD Instinct MI300X, благодаря чему значительно повышается производительность при работе с большими языковыми моделями (LLM). Решение SuperNODE, напомним, использует фирменную архитектуру FabreX на базе PCI Express, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE даёт возможность более эффективно использовать ресурсы. Изначально для SuperNODE предлагались конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100. Новая версия допускает использование 32 изделий Instinct MI300X. Утверждается, что архитектура FabreX в сочетании с технологией интерконнекта AMD Infinity Fabric наделяет систему SuperNODE «лучшими в отрасли» возможностями в плане задержек при передаче данных, пропускной способности и управления перегрузками. Это позволяет эффективно справляться с обучением LLM с большим количеством параметров. 
Источник изображения: GigaIO Отмечается, что SuperNODE значительно упрощает процесс развёртывания и управления инфраструктурой ИИ. Традиционные конфигурации обычно включают в себя сложную сеть и необходимость синхронизации нескольких серверов, что создаёт определённые технических сложности и приводит к дополнительным временным затратам. Конструкция SuperNODE с 32 мощными ускорителями в рамках одной системы позволяет решить указанные проблемы.
20.04.2024 [20:50], Сергей Карасёв
ИИ-облако TensorWave получит 20 тыс. ускорителей AMD Instinct MI300XВ то время как многие операторы облачных платформ и дата-центров закупают ускорители NVIDIA H100 для задач ИИ и НРС, стартап TensorWave, по сообщению ресурса The Register, сделал выбор в пользу решений AMD. Ожидается, что такой подход позволит ускорить развёртывание сервисов и снизить стоимость услуг для заказчиков. Системы класса bare metal будут предлагаться для аренды на определённый период времени по цене от $1/ч/GPU. TensorWave приступила к созданию облачной ИИ-системы на базе ускорителей Instinct MI300X. К концу 2024 года TensorWave планирует установить около 20 тыс. ускорителей MI300X на двух объектах, объединённых RoCE-фабрикой. В 2025-м, как ожидается, будут введены в эксплуатацию дополнительные мощности с СЖО. В дальнейшем планируется внедрение технологии GigaIO FabreX на базе PCIe 5.0, позволяющей объединить до 5750 ускорителей в одном домене с более чем 1 Пбайт памяти НВМ. 
Источник изображения: AMD TensorWave использует системы с восемью ускорителями MI300X в одном узле. В одной стойке будут располагаться четыре таких узла. Упомянуто применение системы охлаждения с теплообменниками на задней двери. Судя по фотографиям, стартап использует 8U-серверы Supermicro AS-8125GS-TNMR2. Расчётная мощность составляет приблизительно 40 кВт на стойку. В долгосрочной перспективе TensorWave нацелена на внедрение технологии прямого жидкостного охлаждения чипов, что позволит повысить мощность и плотность размещения оборудования. 
Источник изображения: TensorWave Соучредитель TensorWave Джефф Татарчук (Jeff Tatarchuk) отмечает, что применение MI300X обеспечивает ряд преимуществ перед изделиями NVIDIA. Это отсутствие столь серьёзного дефицита, более высокая производительность и меньшая стоимость аренды для потребителей облачных ИИ-услуг. Однако, по словам Татарчука, препятствием при коммерциализации сервисов на базе ускорителей AMD может стать то, что потенциальные клиенты выражают неуверенность по поводу возможностей MI300X в сравнении с H100.
30.03.2024 [15:06], Сергей Карасёв
AMD готовит ускоритель Instinct MI388XКомпания AMD, по сообщению ресурса VideoCardz, направила в Комиссию по ценным бумагам и биржам США (SEC) документацию, в которой говорится о подготовке нового продукта семейства Instinct — изделия с обозначением MI388X. Судя по имеющейся информации, это производительное решение, не предназначенное для поставок на китайский рынок. Технические характеристики новинки не раскрываются. Известно лишь, что в основу Instinct MI388X положена архитектура CDNA3. Предусмотрено использование 5-нм и 6-нм техпроцессов TSMC. 
Источник изображения: AMD Судя по наличию индекса «Х» в обозначении, новое изделие представляет собой самостоятельный ИИ-ускоритель (как и Instinct MI300X), а не гибридное решение, как в случае MI300A, которое наделено x86-ядрами Zen4. Высказываются предположения, что новинка могла проектироваться под нужды какого-либо конкретного заказчика или для определённого рыночного сегмента. Более того, есть вероятность, что изначально ускоритель Instinct MI388X создавался именно для КНР, но AMD не получила экспортное разрешение на его поставки на китайский рынок. Нужно отметить, что ранее AMD была вынуждена отказаться от поставок в Китай ускорителей Instinct MI309: они оказались слишком мощными, а поэтому попали под американские санкции. Решения MI300X и MI300A также запрещены для отгрузок китайским заказчикам. Между тем в феврале был продемонстрирован вариант Instinct MI300X, оснащённый 12-слойной памятью HBM3E. Суммарный объём такой памяти у модифицированного ускорителя может достигать 288 Гбайт против 192 Гбайт у стандартной версии MI300X.
05.03.2024 [21:32], Руслан Авдеев
Ускорители AMD Instinct MI309 оказались недостаточно слабы, чтобы США позволили продавать их КитаюПо неподтверждённым пока данным, компания AMD провалила попытку снизить производительность своих ИИ-ускорителей таким образом, чтобы те соответствовали экспортным ограничениям США. Bloomberg сообщает, что по этой причине Вашингтон пока запретил поставлять их в Китай. Это довольно распространённая тактика среди производителей чипов — Китай является одним из крупнейших рынков полупроводников в мире и отказываться от него по политическим соображениям компании не хотели бы, поскольку должны учитывать интересы акционеров, рассчитывающих на максимальную прибыль. Возможно, рынок заметно вырастет в ближайшее время, поскольку Пекин огласил планы сделать ИИ сердцем экономического развития. Другими словами, выпуск продуктов для Китая — очень выгодный бизнес. В Bloomberg предполагают, что в AMD посчитали новые ускорители, известные как MI309, пригодными для продажи в Поднебесную, но Министерство торговли США, ответственное за выдачу экспортных лицензий, посчитало чипы чересчур производительными. Речь идёт об урезанной версии MI300, при этом ускорители MI210 в Китай поставляются. Упрощённые ускорители A800 и H800 уже выпускала NVIDIA, но после ужесточения запретов в октябре 2023 года она разработала новые варианты (H20, L20 и L2) с ещё более скромной производительностью. Пока же её продажи в КНР упали. 
Источник изображения: Maxence Pira/unsplash.com Тем временем китайские IT-гиганты накопили огромные запасы ускорителей впрок и компании вроде Baidu и Tencent сообщают, что складских остатков хватит на год-два бесперебойного обеспечения ИИ-проектов. Примечательно, что Baidu говорит о своих разработках в контексте их сравнения с мировыми, а не местными конкурентами. При этом Baidu закупила и местные ИИ-ускорители Huawei Ascend 910B. Хотя китайские лидеры полупроводниковой отрасли хотя и отстают от AMD, Intel и NVIDIA, сбрасывать со счетов их не стоит. При этом некоторые китайские производители чипов занимаются созданием совместимых с CUDA решений. Это косвенно свидетельствует о том, что просто качественного «железо» для успеха мало — необходима совершенная программная среда для его эксплуатации. Это пока является слабым местом китайских разработок, отмечает The Register.
28.02.2024 [15:31], Сергей Карасёв
На MWC 2024 замечен первый образец ускорителя AMD Instinct MI300X с 12-слойной памятью HBM3EКомпания AMD готовит новые модификации ускорителей семейства Instinct MI300, которые ориентированы на обработку ресурсоёмких ИИ-приложений. Изделия будут оснащены высокопроизводительной памятью HBM3E. Работу над ними подтвердил технический директор AMD Марк Пейпермастер (Mark Papermaster), а уже на этой неделе на стенде компании на выставке MWC 2024 был замечен образец обновлённого ускорителя. На сегодняшний день в семейство Instinct MI300 входят модификации MI300A и MI300X. Первая располагает 228 вычислительными блоками CDNA3 и 24 ядрами Zen4 на архитектуре x86. В оснащение входят 128 Гбайт памяти HBM3. На более интенсивные вычисления ориентирован ускоритель MI300X, оборудованный 304 блоками CDNA3 и 192 Гбайт HBM3. Но у этого решения нет ядер Zen4.  Недавно компания Micron сообщила о начале массового производства 8-слойной памяти HBM3E ёмкостью 24 Гбайт с пропускной способностью более 1200 Гбайт/с. Эти чипы будут применяться в ИИ-ускорителях NVIDIA H200, которые выйдут на коммерческий рынок во II квартале нынешнего года. А Samsung готовится к поставкам 12-слойных чипов HBM3E на 36 Гбайт со скоростью передачи данных до 1280 Гбайт/с.  AMD подтвердила намерение применять память HBM3E в обновлённых ускорителях Instinct MI300, но в подробности вдаваться не стала. В случае использования 12-слойных чипов HBM3E ёмкостью 36 Гбайт связка из восьми модулей обеспечит до 288 Гбайт памяти с высокой пропускной способностью. Наклейка на демо-образце недвусмысленно указывает на использование именно 12-слойной памяти. Впрочем, это может быть действительно всего лишь стикер, поскольку представитель AMD уклонился от прямого ответа на вопрос о спецификациях представленного изделия.  Ожидается также, что в 2025 году AMD выпустит ИИ-ускорители следующего поколения серии Instinct MI400. Между тем NVIDIA готовит ускорители семейства Blackwell для ИИ-задач: эти изделия, по заявлениям самой компании, сразу после выхода на рынок окажутся в дефиците.
27.02.2024 [21:44], Сергей Карасёв
Gigabyte представила новые серверы для ИИ, 5G и периферийных вычисленийКомпания Gigabyte Technology на MWC 2024 анонсировала новые серверы для ИИ-задач, 5G-сетей, облачных и периферийных вычислений. Дебютировали модели на процессорах AMD и Intel, оснащённые мощными ускорителями.  В частности, представлены серверы G593-ZX1/ZX2, оборудованные восемью картами AMD Instinct MI300X для ресурсоёмких вычислений. Кроме того, демонстрируются сервер высокой плотности H223-V10 с поддержкой суперчипа NVIDIA Grace Hopper, модель G383-R80 с четырьмя APU AMD Instinct MI300A и сервер серии G593, оснащённый восемью ускорителями NVIDIA HGX H100.  Ещё одна новинка — сервер хранения S183-SH0. Он допускает использование 32 SSD формата E1.S (NVMe), благодаря чему подходит для обработки сложных рабочих нагрузок, таких как большие языковые модели (LLM). Эти серверы также могут быть интегрированы в суперкомпьютерные кластеры и инфраструктуру 5G.  На edge-сегмент рассчитан сервер E263-S30 с модульной архитектурой: он может быть адаптирован под различные сценарии использования путём установки необходимых аппаратных компонентов. А модель R163-P32 комплектуется процессором AmpereOne с архитектурой Arm (до 192 ядер Arm с частотой до 3,0 ГГц), что обеспечивает высокую энергетическую эффективность.
На ИИ-приложения и облачные периферийные вычисления ориентированы серверы R243-EG0 и R143-EG0, которые оснащены чипами AMD EPYC 8004 Siena. Для сегмента малого и среднего бизнеса Gigabyte предлагает серверы R113-C10 и R123-X00, наделённые процессорами AMD Ryzen 7000 и Intel Xeon E-2400: эти модели подходят для веб-хостинга, создания гибридных облаков и хранилищ данных.
24.01.2024 [13:55], Сергей Карасёв
Итальянская нефтегазовая компания Eni получит 600-Пфлопс суперкомпьютер HPC6 на базе AMD Instinct MI250XИтальянская нефтегазовая компания Eni, по сообщению ресурса Inside HPC, заказала суперкомпьютер HPE Cray EX4000 на аппаратной платформе AMD. Быстродействие этой машины, как ожидается, составит около 600 Пфлопс. Известно, что в состав системы, получившей название HPC6, войдут 3472 узла, каждый из которых получит 64-ядерный процессор AMD EPYC и четыре ускорителя AMD Instinct MI250X. Таким образом, общее количество ускорителей составит 13 888. Судя по всему, компания смогла достаточно полно адаптировать своё ПО для работы на современных ускорителях AMD, эксперименты с которыми она начала ещё несколько лет назад. Комплекс будет использовать хранилище HPE Cray ClusterStor E1000 с интерконнектом HPE Slingshot. Узлы суперкомпьютера будут организованы в 28 стоек. Предусмотрено применение технологии прямого жидкостного охлаждения, которая, по заявлениям Eni, рассеивает 96 % вырабатываемого тепла. Максимальная потребляемая мощность — 10,17 МВт. 
Источник изображения: AMD Новый суперкомпьютер разместится в ЦОД Eni Green Data Center в Феррера-Эрбоньоне, который, как утверждается, является одним из самых энергоэффективных и экологически чистых вычислительных центров в Европе. По производительности HPC6 значительно превзойдёт комплексы HPC4 и HPC5, совокупная вычислительная мощность которых составляет 70 Пфлопс. При производительности 600 Пфлопс система HPC6 займёт второе место в текущем списке TOP500 самых мощных суперкомпьютеров мира.
14.01.2024 [21:18], Владимир Мироненко
Учёные ORNL сумели обучить LLM с 1 трлн параметров, задействовав всего 3072 ускорителя AMD Instinct MI250XКоманда специалистов Национальной лаборатории Ок-Ридж обучила большую языковую модель (LLM) с 1 трлн параметров на суперкомпьютере Frontier, используя лишь 3072 из имеющихся 37 888 ускорителей. LLM такого масштаба сравнима по возможностям с OpenAI GPT4. Кроме того, учёные смогли обучить LLM со 175 млрд параметров, задействовав всего лишь 1024 ускорителя. При обучении LLM с миллиардами параметров требуются значительные вычислительные ресурсы и большой объём памяти. Учёные ORNL занялись исследованием вопроса оптимизации этого процесса и изучили различные фреймворки, методы работы с данными и параллелизацией обучение, оценив их влияние на память, задержку коммуникаций и уровень эффективности использования ускорителей. 
Источник изображения: ORNL Прорыва удалось достичь благодаря точной настройке гиперпараметров и оптимизации всего процесса обучения. Команда Frontier провела исчерпывающие тесты с различными параметрами, и в итоге стал возможен процесс обучения LLM с 1 трлн параметров с использованием всего 3 тыс. ускорителей AMD Instinct MI250X. Задача осложнялась тем, что для работы с ними используется ROCm, тогда как для подавляющего большинства ИИ-инструментов требуется поддержка NVIDIA CUDA. Результаты показали, что фактическая пропускная способность ускорителей составила 31,96 % для модели с 1 трлн параметров и 36,14 % для модели с 17 млрд параметров. Кроме того, для обеих моделей исследователи достигли 100-процентной эффективности слабого масштабирования и высокой эффективности сильного масштабирования: 89 % для модели со 175 млрд параметров и 87 % для модели с 1 трлн параметров. Впрочем, в исследовании не уточняется, сколько времени ушло на обучение этих моделей.
21.12.2023 [14:51], Сергей Карасёв
Германия построит суперкомпьютер Herder экзафлопсного уровняЦентр высокопроизводительных вычислений HLRS в Штутгарте (Германия) объявил о заключении соглашения с компанией HPE по созданию двух новых суперкомпьютеров — систем Hunter и Herder. Они, как утверждается, предоставят «инфраструктуру мирового класса» для моделирования, ИИ, анализа данных и других ресурсоёмких задач в различных областях. Hunter заменит нынешний флагманский суперкомпьютер HLRS под названием Hawk. В основу Hunter ляжет платформа HPE Cray EX4000: в общей сложности планируется задействовать 136 таких узлов, каждый из которых будет оснащён четырьмя адаптерами HPE Slingshot. Архитектура Hunter предусматривает применение СХД нового поколения Cray ClusterStor, специально разработанной с учётом жёстких требований к вводу/выводу. Кроме того, будет задействована среда HPE Cray Programming Environment, которая предоставляет полный набор инструментов для разработки, портирования, отладки и настройки приложений. 
Источник изображения: HLRS Суперкомпьютер Hunter получит ускорители AMD Instinct MI300A. Утверждается, что это позволит сократить энергопотребление по сравнению с Hawk примерно на 80 % при пиковой производительности. Быстродействие Hunter составит около 39 Пфлопс против 26 Пфлопс у Hawk. Систему планируется ввести в эксплуатацию в 2025 году. Суперкомпьютер экзафлопсного класса Herder заработает не ранее 2027 года. Архитектура предусматривает применение ускорителей, но окончательная конфигурация комплекса будет определена только к концу 2025-го. 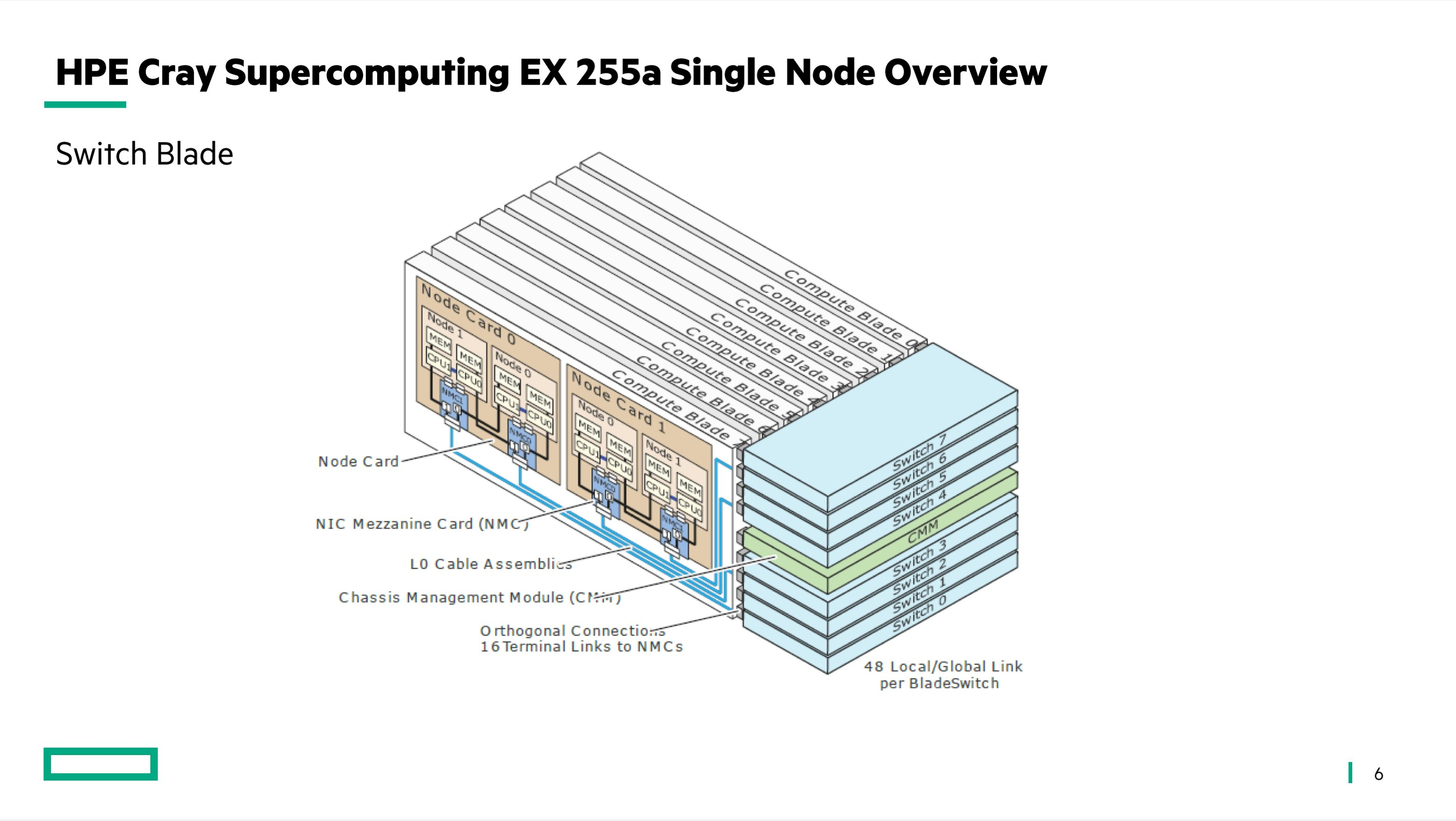
Источник изображения: HPE Общая стоимость Hunter и Herder оценивается в €115 млн. Финансирование будет осуществляться через Центр суперкомпьютеров Гаусса (GCS), альянс трёх национальных суперкомпьютерных центров Германии. Половину средств предоставит Федеральное министерство образования и исследований Германии (BMBF), оставшуюся часть — Министерство науки, исследований и искусств земли Баден-Вюртемберг. Нужно отметить, что в 2024 году в Юлихском исследовательском центре (FZJ) в Германии заработает вычислительный комплекс Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Кроме того, систему такого уровня намерена создать Великобритания. |
|


