Материалы по тегу: сбой
|
08.11.2023 [17:16], Руслан Авдеев
Перегрев ЦОД Equinix в Сингапуре привёл к срыву 2,5 млн банковских транзакцийТехнические проблемы, возникшие в сингапурском дата-центре Equinix в середине минувшего октября из-за перегрева, привели к серьёзным проблемам в банковской сфере. Как сообщает The Register со ссылкой на Валютное управление Сингапура (MAS), проблемы с системой охлаждения ЦОД привели к остановке 2,5 млн банковских операций. Проблема затронула DBS и Citibank, неприятности у которых начались днём 14 октября 2023 года — в результате клиенты частично утратили доступ к банковским услугам приблизительно на два дня, лишившись возможности осуществлять платежи. По данным властей в результате роста температуры в ЦОД выше допустимого уровня из-за нарушения работы системы охлаждения зарегистрировано 810 тыс. неудачных попыток доступа к двум банковским платформам, понадеявшихся на Equinix, а 2,5 млн онлайн-платежей и операций в банкоматах так и не были завершены. Сам оператор ЦОД винит подрядчика, поскольку его сотрудник якобы «неправильно» отправил сигнал на закрытие клапанов буферных резервуаров с холодной водой в ходе обновления инфраструктуры.  Хотя банки немедленно приняли меры для возвращения работоспособности после инцидента, полностью восстановить системы с использованием резервных ЦОД сразу не удалось. DBS — из-за неправильной конфигурации сети, а Citibank из-за проблем с сетевым подключением. В результате оба банка не сумели уложиться в нормативы MAS, требующие, чтобы отключение критически важных систем, влияющих на банковские операции, не превышало 4 часов в год. Управление ввело ряд довольно жёстких наказаний для провинившихся банков сроком на полгода. По мнению экспертов, удивительно не только то, что система охлаждения не сработала, но и то, что банки не смогли своевременно отреагировать на сбой, введя в действие резервные мощности. Считается, что, как часто бывает, инцидент произошёл благодаря стечению неблагоприятных обстоятельств, поскольку на активацию резервной системы в норме уходят секунды или минуты. При этом MAS не контролирует деятельность провайдеров вроде Equinix.
08.11.2023 [16:35], Руслан Авдеев
Австралийский оператор Optus оставил без связи почти полстраныПринадлежащий сингапурской компании Singtel австралийский телеком-оператор Optus с 04:00 среды (12:00 по московскому времени) страдает от масштабного сбоя, затронувшего информационную инфраструктуру по всей стране. По данным The Register, без телефонной связи и интернета остались миллионы австралийцев — компания является там вторым по величине национальным оператором. Граждане и организации понесли ущерб не только от отсутствия связи — временно перестали работать некоторые поезда, а также другие виды транспорта, включая такси или каршеринг. Также перестали функционировать платёжные терминалы. При этом наличность сегодня имеют не так много людей — после пандемии COVID-19 переход на безналичные расчёты привёл к тому, что уже в 2022 году в Австралии на наличность приходилось немногим более 10 % платежей. 
Источник изображения: Joey Csunyo/unsplash.com На этом неприятности австралийцев не закончились. Пострадали наземные линии связи и информационная инфраструктура критически важных объектов вроде больниц, пожарных служб и др. В Optus сообщили, что для вызова экстренных служб необходимо пользоваться мобильной связью, поскольку других операторов страны сбой не коснулся. По данным сервиса Netblocks, интернет-сервисы Optus частично восстановились на восьмой час с момента сбоя, но мобильная сеть оставалась нефункциональной. После этого сообщалось о начале постепенного восстановления всех сервисов, но на полное возобновление работы, вероятно, уйдут часы. Представитель Optus заявил журналистам, что главная причина всё ещё выясняется, но данных о возможной кибератаке пока нет. По некоторым сведениям, сбой могло вызвать некорректное обновление ПО, но точные данные отсутствуют. 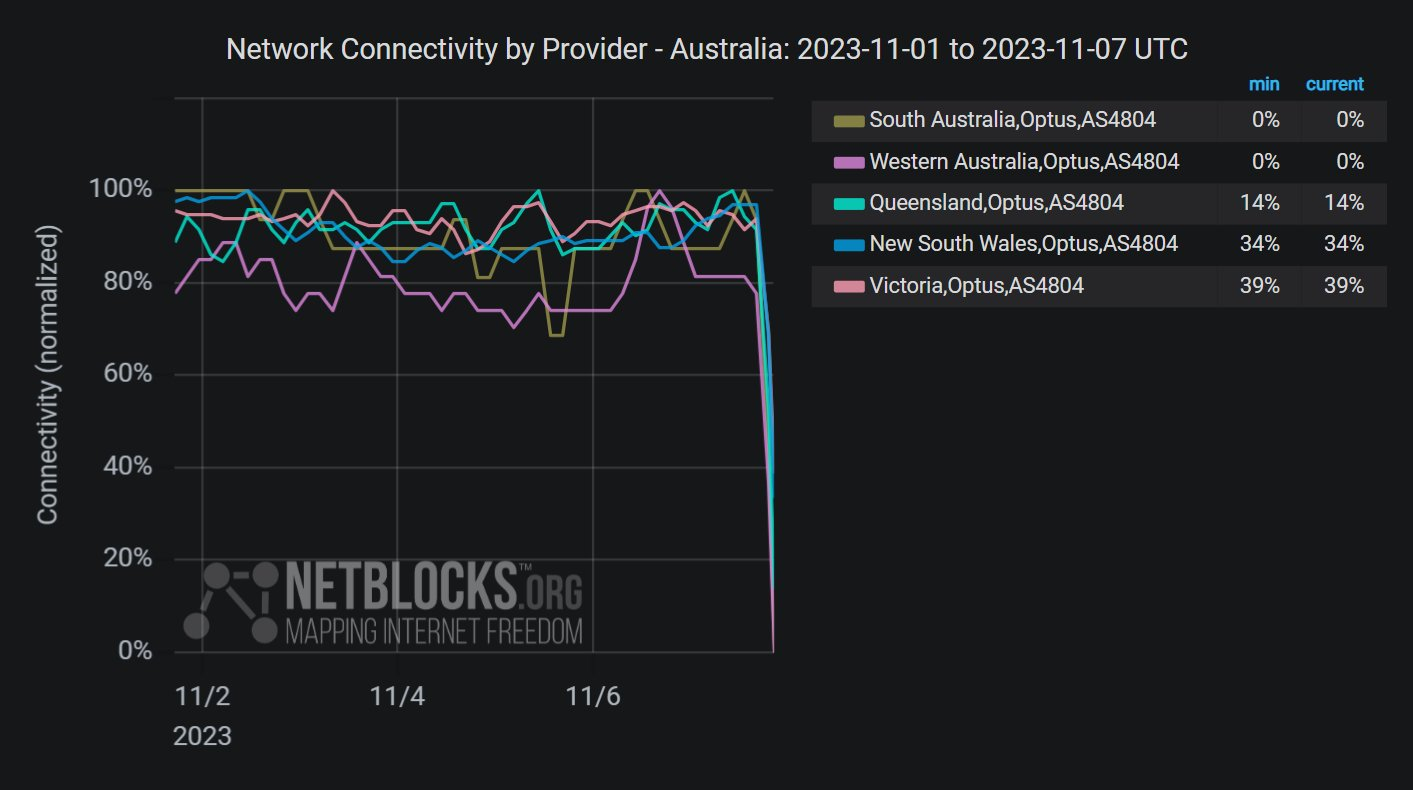
Источник: Twitter/@netblocks Всего Optus насчитывает 10,2 млн клиентов, т.е. около 40 % населения Австралии. В прошлом году Optus тоже «отличилась» — после кибератаки в Сеть утекли данные её пользователей, сведений оказалось достаточно для злоумышленников, чтобы открывать даже банковские аккаунты от их имени. Местные чиновники раскритиковали работу Optus, в частности заявив, что правительство Южной Австралии уже рассматривает переключение критически важных сервисов на других провайдеров. В этом месяце пострадали от отключения интернета и клиенты крупных банков в Сингапуре — перегрев оборудования и отказ резервных систем привёл к срыву 2,5 млн банковских транзакций, а власти призвали население и бизнесы позаботиться об альтернативных средствах платежей на случай подобных происшествий.
27.10.2023 [17:50], Руслан Авдеев
Пожар в IT-хабе столицы Бангладеша оставил десятки миллионов жителей без СетиВ результате начавшегося в четверг вечером пожара в 14-этажной башне Khawaja Tower в Дакке (Бангладеш) погибло минимум три человека. В здании располагались международные интернет-шлюзы (IIG), дата-центры и точки обмена трафиком (ICX), которые пострадали от пожара. Как сообщает Dhaka Tribune, из-за этого без стабильной связи остались 5 млн пользователей кабельного интернета, а у 23 млн абонентов сотовой связи наблюдаются проблемы с передачей данных и звонками. В результате возгорания проблемы со стационарным интернет-доступом возникли у 5 из 12,5 млн пользователей. Многие полностью потеряли доступ в Сеть, а у тех, у кого он остался, заметно упала скорость соединения. Проблема коснулась и пользователей мобильного интернета: из 119,79 млн пользователей около 24 млн не могут выйти в Сеть, а некоторые лишились и обычных телефонных звонков. Если в норме страна использует полосу порядка 5 Тбит/с, то с отключением многих IIG пропускная способность упала до 1,2 Тбит/с. 
Источник изображения: Bangladesh Fire Service and Civil Defence Комментируя ситуацию, представитель организации ISPAB, представляющей интернет-провайдеров страны, заявил, что ситуация под контролем (пожар полностью потушили сегодня к утру), но доступ операторов в помещения пока ограничен. Уже известно, что из двух расположенных в здании ЦОД один (NRB) пострадал от пожара, а состояние второго (Dhaka Cola) неизвестно. Власти подтверждают, что 9–10 из имевшихся в Khawaja Tower шлюзов не функционируют, при этом каждый обеспечивает транзит данных 50–70 интернет-провайдеров. Всего потеряли возможность предоставлять услуги около 500–700 провайдеров. По данным представителя IIG Forum, многие провайдеры, включая Level Three, Max Hub, Amra Networks, Earthnet, Vargo и Windstream пострадали от пожара и сейчас переключаются на резервные IIG. При этом часть из них обеспечивают подключения мобильным операторам — если некоторые полностью прекратили работу, то другие почти или совсем не пострадали. Впрочем, проблему связности это не решает, поскольку не все абоненты могут полноценно осуществлять даже голосовые звонки. 
Источник: Twitter/NetBlocks Мобильные операторы совместно с операторами ICX-узлов сейчас формируют новую инфраструктуру в другом, безопасном месте. По мнению экспертов, работоспособность быстро восстановить не получится, поскольку имевшееся оборудование пострадало, а новое оперативно не купить из-за дефицита на рынке. Впрочем, по степени влияния инцидент в Дакке пока «проигрывает» самому масштабному на текущий момент сбою ЦОД в Южной Корее, который тоже возник из-за пожара. Как сообщает Datacenter Dynamics, руководство пожарных доложило об отсутствии в здании плана противопожарной безопасности. Точная причина возгорания пока не называется. С огнём, помимо пожарной службы, помогали бороться и другие государственные ведомства — от военных до полиции. Впрочем, это не единичный случай. Только весной зарегистрированы крупные возгорания ЦОД в США, Франции, Нигерии, а о более мелких инцидентах информация иногда не поступает вовсе.
15.10.2023 [23:05], Владимир Мироненко
Сбой в сингапурском ЦОД Equinix повлёк за собой остановку банковских сервисов в стране и проблемы с доступом к сервисам Meta✴ за её пределами [Обновлено]В минувшую субботу в дата-центре Equinix в Сингапуре произошёл сбой, повлекший за собой остановку банковских сервисов по всей стране, сообщил ресурс Data Center Dynamics. В настоящее время ведётся расследование «технической проблемы», вызвавшей повышение температуры в ЦОД, сообщили в Equinix. Сообщается, что из-за сбоя в ЦОД компании были отключены сервисы банков DBS и Citibank в Сингапуре. Также проблемы наблюдались в работе других сервисов на Филиппинах, в Гонконге, Индии, Южной Африке, Камбодже, Индонезии, Шри-Ланке, ОАЭ и на Мальдивах, где многие пользователи не смогли получить доступ к своим аккаунтам в Facebook✴, Instagram✴ и Whatsapp. 
Источник изображения: Equinix/Data Center Dynamics В валютном управлении Сингапура (MAS) сообщили о том, что им известно о сбое, в связи с чем проводится расследование, а к Equinix применены ограничительные меры. Ранее подобные ограничения были применены к Equinix в феврале 2022 года в связи с происшедшим тогда сбоем. «Отключения, подобные инциденту 14 октября, показывают, насколько важны ЦОД для нашей повседневной жизни, и поэтому организациям необходимо постоянно анализировать отдельные точки сбоев и принимать соответствующие меры для снижения этих рисков», — сообщил Эдвард ван Леент (Edward van Leent) председатель сингапурской компании Enterprise Products Integration (EPI). Количество сбоев ЦОД с годами не уменьшается. По данным Uptime Institute, основанным на анализе сбоев ЦОД в 2023 году, более двух третей всех сбоев обходятся более чем в $100 тыс., в том числе почти 25 % сбоев наносят убытки более чем в $1 млн. Патрик Чан (Patrick Chan), вице-президент Uptime Institute по азиатскому региону указал на важность проведения сертификации ЦОД с целью соблюдения стандартов и снижения рисков сбоев. UPD 24.10.2023: Equinix обвинила в сбое стороннего подрядчика, который подал сигнал на закрытие вентилей ёмкостей с теплоносителем во время запланированного обновления инфраструктуры, в результате чего температура в некоторых машинных залах поднялась, что и привело к проблемам у клиентов компании. Кроме того, валютное управление Сингапура предписало банкам DBS и Citibank провести тщательное расследование, почему их резервные ЦОД не смогли вовремя принять нагрузку на себя.
04.09.2023 [19:24], Руслан Авдеев
Нехватка рук и плохая автоматизация: Microsoft отчиталась о сбое в сиднейском ЦОДПроизошедший 30 августа сбой в работе австралийского дата-центра привёл к проблемам в работе с сервисами Azure, API, базами данных, а также облачным ПО. Пользователи более суток не имели доступа к Azure, сервисам Microsoft 365 и Power Platform. Как сообщает Network World, в Microsoft обвиняют в произошедшем недостаток персонала в ЦОД и неисправную систему автоматики. По данным экспертов компании, после падения напряжения в сети на юго-востоке страны отключилась часть охлаждающих систем в одном из ЦОД. Поскольку охлаждение не работало должным образом, рост температуры в машинных залах привёл к автоматическому отключению некоторого оборудования для сохранения инфраструктуры и данных. При этом в компании подчеркнули, что системы охлаждения можно было бы заново включить вручную, окажись для этого достаточно персонала в ЦОД. С учётом размеров кампуса и небольшого числа сотрудников ночной смены людей оказалось недостаточно для своевременного восстановления работоспособности. В компании подчеркнули, что временно увеличили команду с трёх до семи человек, пока не выяснили причины проблем и не приняли необходимые меры для их устранения. 
Источник изображения: Microsoft В Microsoft добавили, что компания работает над масштабными реформами, включая совершенствование системы автоматизации ЦОД для восстановления работоспособности в случае повторения инцидентов, в частности, связанных с перепадами напряжения. Поэтому ведётся оценка загруженности серверов, чтобы выяснить, какие именно системы охлаждения нужно «оживить» в первую очередь. В последние месяцы сбои в работе сервисов Microsoft уже случались, в первую очередь связанные с нарушением доступа к Microsoft 365. Например, в июле пострадали OneDrive для бизнеса и SharePoint Online, а месяцем ранее с проблемами на восемь часов столкнулись пользователи Outlook Web, Teams, OneDrive для бизнеса и SharePoint. А в начале года наблюдались глобальные сбои в работе сервисов компании.
31.08.2023 [12:37], Сергей Карасёв
Затраты Rackspace на устранение последствий кибератаки превысят $10 млнКомпания Rackspace Technology, провайдер облачных услуг, по сообщению ресурса Dark Reading, столкнулась со значительными затратами в связи со сбоем, который произошёл в конце 2022 года в результате атаки программы-вымогателя. Напомним, из-за хакерского вторжения компании Rackspace пришлось навсегда отключить свою службу Microsoft Exchange. Причиной масштабного сбоя послужил эксплойт для уязвимости «нулевого дня». С последствиями атаки Rackspace не могла справиться в течение нескольких недель. Впоследствии калифорнийская Cole & Van Note подала коллективный иск против Rackspace в связи с недоступностью облачных сервисов. Для расследования инцидента компании пришлось привлечь сторонних специалистов. 
Источник изображения: Rackspace Как теперь стало известно, расходы Rackspace на устранение последствий кибератаки составят приблизительно $10,8 млн. Говорится, что деньги пойдут в основном на оплату работы экспертов в области информационной безопасности, занимающихся расследованием инцидента, юридические и другие профессиональные услуги, а также на «дополнительные кадровые ресурсы», которые были задействованы для оказания поддержки клиентам. Кроме того, компенсацию от Rackspace требуют недовольные пользователи, которые не могли получить доступ к сервисам провайдера облачных услуг. Rackspace ожидает, что значительная часть затрат будет возмещена компаниями по киберстрахованию.
21.06.2023 [15:09], Руслан Авдеев
Проблемы с поставками комплектующих привели к всплеску сбоев в работе ЦОД во всём миреХотя проблемы с поставками электронных компонентов в последнее время постепенно отходят на второй план, в некоторых секторах IT-индустрии они так и не решены до конца. Как сообщает Network World со ссылкой на ассоциацию профессионалов рынка ЦОД (AFCOM), 44 % опрошенных операторов дата-центров сталкиваются с перебоями или отключениями, вызванными дефицитом самых необходимых запасных частей и компонентов. Примечательно, что в 2021 году о подобных проблемах говорили только 25 % опрошенных, причём ситуация усугубляется стремлением многих операторов ЦОД расширять свой бизнес ускоренными темпами. Как сообщает AFCOM в докладе State of the Data Center 2023, 94 % опрошенных столкнулись с теми или иными проблемами при организации поставок для своих ЦОД, 59 % — с дефицитом основного оборудования вроде серверов и коммутаторов, 51 % — систем энергоснабжения, включая генераторы и ИБП, 34 % жалуются на нехватку систем безопасности, в том числе защищённых дверей и камер, а 35 % — на дефицит строительных материалов вроде бетона. Некоторые операторы сталкиваются с несколькими проблемами сразу. 
Источник изображения: dendoktoor/pixabay.com По мнению экспертов, в последнее время многие инвестиционные компании приобрели дата-центры и теперь пытаются нарастить их мощности настолько быстро, насколько возможно, что тоже усугубляет дефицит. Иногда доходит до того, что почти готовые ЦОД не могут ввести в эксплуатацию из-за одного компонента. Например, в некоторых случаях ИБП и генераторы доставляют 50 недель вместо привычных ранее 8-10, а на поставку чиллеров может уйти и 70 недель — почти полтора года. При этом сами операторы превращают ситуацию на рынке из плохой в катастрофическую, скупая комплектующие на всякий случай и скапливая запасы фактически ненужного оборудования на складах. Дефицит больше затронул гиперскейлеров и колокейшн-сервисы, чем корпоративных заказчиков с локальными ЦОД. Последние настроены эксплуатировать оборудование как можно дольше и чаще готовы неспешно ожидать поставок. Впрочем, действительно рекомендуется иметь некоторый запас необходимых запчастей на случай экстренных ситуаций. Эксперты рекомендуют искать поставщиков-партнёров, которые имеют чёткий план на случай перебоев с поставками по воздуху или железным дорогам. Не стоит отказываться и от рынка б/у оборудования — даже устаревшее на несколько поколений и несущее другие проблемы «железо» во многих случаях лучше, чем полное отсутствие оборудования. Этот рынок тем более стоит рассматривать потому, что гиперскейлеры довольно часто поставляют на него оборудование. Наконец, одним из важнейших советов является приобретение схожего оборудования у разных вендоров. Известно, что многие предпочитают приобретать железо одного производителя, но в ситуации, когда выбирать не из чего, особо разборчивым быть не приходится.
15.06.2023 [23:20], Руслан Авдеев
Арктический лёд порвал подводный кабель, вызвав проблем с интернет-доступом на АляскеНаселение Аляски пострадало от масштабных отключений широкополосного интернет-доступа. Как сообщает DataCenter Dynamics, и без того почти отрезанный от остального мира регион лишился стабильного доступа в Сеть из-за обрыва подводного оптоволоконного кабеля, предположительно пострадавшего от арктических льдов. Местным жителям пришлось временно переключиться на спутниковый интернет и радиодоступ. По данным местного провайдера Quintillion, обрыв произошёл примерно в 55 км от мыса Оликток из-за «движения льдов» — на ликвидацию последствий аварии может уйти несколько недель. Дрейфующие льдины занесло на мелководье, где они буквально вспахали дно, что разрушило местную экосистему и, похоже, кабельную инфраструктуру. Специальная команда экспертов занята диагностикой и решением проблемы. К месту обрыва направлено специализированное ремонтное судно. В Quintillion подчеркнули, что продолжают следить за местом обрыва, используя рефлектометр. Местные СМИ сообщают о проблемах с телефонной связью и платежами с помощью банковских карт. В Quintillion рассчитывают, что ВОЛС будет восстановлена настолько быстро, насколько это возможно, хотя о точных сроках говорить не приходится. Вряд ли связь будет налажена ранее, чем через 6–8 недель. 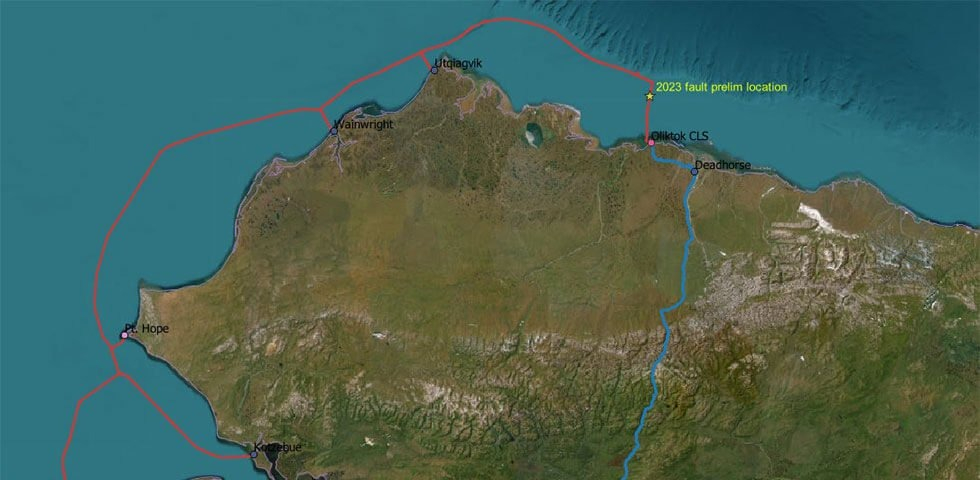
Источник изображения: Quintillion Ранее сообщалось, что только за последние пять лет обрывы подводных ВОЛС случались порядка 20 раз, один из последних — в конце февраля вблизи Тайваня, когда кабели были перерезаны (предполагается, что случайно) китайскими рыболовными судами. Великобритания уже приобрела корабль для защиты подводных кабелей, причём в его функции входит не только контроль и ремонт коммуникаций, но и, вероятно, силовая защита в случае необходимости.
14.06.2023 [18:45], Руслан Авдеев
Облако AWS пережило кратковременный, но крупный сбой, затронувший тысячи клиентов и сервисы самой AmazonОблачный провайдер Amazon Web Services (AWS) допустил крупный сбой своих сервисов, результатом которого стали отказы в обслуживании многочисленных компаний 13 июня. Как сообщает Network World, в самой Amazon причиной сбоя, коснувшегося тысяч клиентов, называют неполадки в ключевом облачном регионе us-east-1 в Северной Вирджинии, в результате были затронуты как минимум 104 сервиса компании. По данным самой Amazon, проблемы сохранялись около четырёх часов и коснулись, в частности, AWS Management Console, Amazon SageMaker, AWS Glue, Amazon Connect, AWS Fargate и Amazon GuardDuty. Далее по цепочке пострадали зависимые сервисы, что привело к крупномасштабному сбою систем и самой AWS, и её клиентов. Основной причиной названа проблема с подсистемой, отвечающей за управление мощностями AWS Lambda. Как сообщает Reuters, этим и подобными решениями, согласно данным Datadog, пользуются более половины организаций, использующих облачные площадки. 
Изображение: Mohamed Hassan / Pixabay Как сообщили в AWS, клиенты пострадали как напрямую, например, из-за проблем с API Gateway, так и из-за сбоев в работе других сервисов AWS. В результате пострадали ресурсы и сервисы многих крупнейших компаний, включая The Verge, авиакомпанию Southwest Airlines и Транспортное управление Нью-Йорка. Некоторое время не работали даже сайт самой AWS, Amazon Music и Alexa. Примечательно, что в конце апреля начался второй раунд массовых увольнений в облачном подразделении компании, а в начале июня неожиданно ушёл в отставку глава отдела проектирования, строительства и эксплуатации дата-центров AWS. Сейчас, как утверждают в компании, работа всех сервисов AWS вернулась к норме, но на пике портал Downdetector регистрировал до 12 тыс. жалоб. В целом, проблема оказалась не такой острой, как, например, в 2017 году во время сбоя Amazon S3. Последний крупный сбой в облачной инфраструктуре Amazon произошёл в декабре 2021 года, когда из-за нарушения работы сервисов временно перестали работать стриминговые платформы Netflix и Disney+, а также другие крупные порталы, включая сам маркетплейс Amazon — и всё это незадолго до Рождества.
30.05.2023 [20:49], Владимир Мироненко
Rackspace ведёт работы по восстановлению систем после масштабного сбоя SANПровайдер облачных услуг Rackspace Technology столкнулся со сбоем на объектах в Европе и Азиатско-Тихоокеанском регионе. «Rackspace известно о проблемах с подключением в наших центрах обработки данных SYD2, LON5, LON3 и HKG5. Инженеры привлечены и работают над решением проблемы», — сообщила компания на странице состояния системы 29 мая в 22:24 CDT (6:24 мск). Как пишет The Register, поначалу компания свзязала проблемы с DWDM-подключением в Лондоне, поскольку находящийся там объект относится к транспортной сети Rackspace. На затем она заявила, что сбой был связан с IO-лимитами в многопользовательской среде SAN, которые были некорректно настроены. 
Источник изображения: Rackspace Technology «Инженеры успешно выполнили сценарий для восстановления значений по умолчанию для IO-лимитов. Пока идёт проверка, несколько клиентов подтвердили, что среды снова подключены к сети», — сообщила компания 30-го мая в 4:37 CDT (29-го мая в 23:37 мск). На момент подготовки материала на странице мониторинга показывалось, что у четырёх объектов компании всё ещё наблюдались проблемы. «У некоторых клиентов в центрах обработки данных LON3 и LO5 в это время могут возникнуть проблемы с резервным копированием», — предупредила компания своих клиентов. В декабре 2022 года Rackspace столкнулась с крупной кибератакой, из-за которой пришлось отключить сервис Hosted Exchange. Компания заявила, что инцидент был вызван эксплойтом «нулевого дня» и что она не будет возобновлять работу сервиса. |
|

