Для того чтобы разобраться в причинах, побудивших компанию Oracle сделать крен в сторону СУБД класса In-Memory, достаточно принять во внимание возрастающие с каждым годом объемы неструктурированной информации, которые в профессиональной IT-среде получили название Big Data, — они требуют инновационных подходов к обработке и аналитике данных. Согласно прогнозам International Data Corporation (IDC) и EMC, к 2020 году количество серверов в мире вырастет в десять раз, объем обрабатываемой дата-центрами информации — в 14 раз, при этом масштабным изменениям подвергнутся типы хранящихся в облачных инфраструктурах данных.
Ожидается, что в течение ближайших шести лет цифровая вселенная достигнет объема в 40 зеттабайт (то есть 40·1021 байт), а рост общего объема информации будет происходить в основном за счет данных, автоматически генерируемых различными промышленными системами и комплексами. В результате стремительного роста объемов неструктурированной информации IT-компании столкнутся с рядом трудностей, наиболее значимыми из которых станут вопросы оперативной обработки больших объемов полезных данных — их значительная часть будет просто-напросто теряться. Сегодня, к примеру, используется менее 3% из 23% потенциально полезных данных, которые могли бы найти применение с технологиями Big Data. Всё это обуславливает важность понимания и интерпретации «больших данных», расходы на обработку которых, согласно исследованиям IDC, к 2016 году увеличатся до 20 млрд долларов. Это очень серьезный рынок, и нет ничего удивительного, что Oracle уделяет ему серьезное внимание, совершенствуя свои решения для хранения и обработки данных, в том числе технологии In-Memory.

Oracle Database In-Memory прозрачно расширяет возможности СУБД Oracle Database 12c
На первый взгляд, в идее размещения и исполнения базы данных в оперативной памяти нет ничего инновационного, однако в Oracle при создании механизма Database In-Memory пошли чуть дальше и сумели добиться ускорения как аналитических, так и транзакционных (OLTP) приложений без изменения их кода. В этом, собственно, и кроется ключевое преимущество новой опции Oracle Database 12c перед прочими доступными на рынке системами управления базами данных, в которых ускорение аналитических запросов обычно влечет замедление операций OLTP-обработки. Обойти это «узкое место» современных СУБД специалистам Oracle удалось благодаря хранению обрабатываемых в оперативной памяти таблиц не только в построчном, но и в поколоночном представлении. Такой подход расширил возможности встроенного в систему оптимизатора и позволил наиболее эффективно использовать строчный и поколоночный форматы хранения данных в зависимости от типа и сложности обрабатываемых запросов. Как результат — повышение на несколько порядков производительности информационно-аналитических баз данных и систем подготовки отчетов, а также ускорение оперативной обработки транзакций в два-три раза. Именно такие количественные показатели приводятся в официальном пресс-релизе компании Oracle.
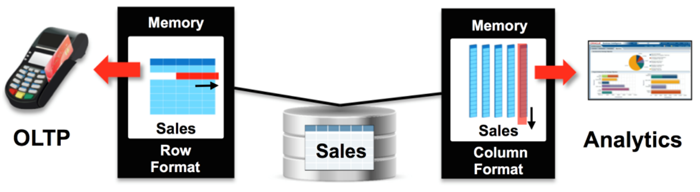
С включенной опцией In-Memory СУБД Oracle Database 12c хранит данные в обоих форматах сразу — они одновременно активны и транзакционно согласованы
Хранение данных в обоих форматах одновременно предъявляет повышенные требования к объему оперативной памяти. В Oracle учли этот момент и реализовали алгоритмы сжатия, позволяющие достигать уровня компрессии данных в 2-20 раз и помещать в память как можно больше данных. Кроме того, система Database In-Memory позволяет администраторам баз данных кешировать в памяти не все таблицы, а только выборочные, работа с которыми происходит наиболее часто. При желании можно поместить в оперативную память не всю таблицу, а ее отдельные колонки, ускорив тем самым выполнение сложных аналитических запросов. Для удобства администраторов Oracle планирует в будущем включить в состав СУБД специальный инструментарий, который на основе анализа выполняемых запросов будет подсказывать, какие таблицы стоит хранить в двойном формате, а какие — оставить в традиционном.
Второй отличительной особенностью Database In-Memory является возможность использования векторных инструкций SIMD (Single Instruction Multiple Data), поддерживаемых современными процессорами и позволяющих за один такт исполнять одну команду над множеством (вектором) операндов. Векторная операция позволяет набор (вектор) всех значений колонки таблицы подать на один вход процессора, значение, которое нужно найти, — на другой и за один такт процессора получить результат. Если требуется выполнить несколько таких операций, то они будут выполняться системой на разных процессорах, и в многопроцессорных (многоядерных) вычислительных комплексах такие задачи будут обсчитываться в сотни раз быстрее. Использование SIMD-инструкций позволяет существенно ускорить операции соединения («тяжелые» с точки зрения реляционной алгебры) и фильтрации.
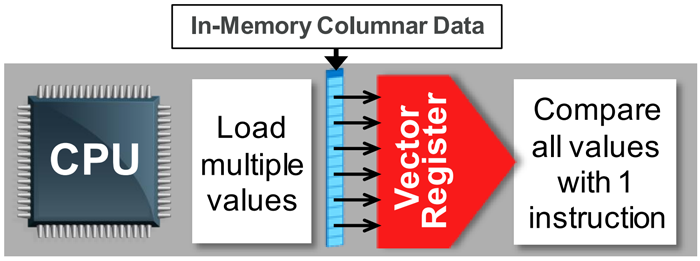
Ускорение обработки аналитических запросов также обеспечивается за счет использования векторных инструкций процессоров
Другими важными преимуществами механизма Database In-Memory являются возможность его взаимодействия с базами данных любого размера вне зависимости от объема оперативной памяти и простота использования опции на любых аппаратных и программных платформах с установленной Oracle Database 12c. Администратору достаточно задать размер буфера, указать, какие таблицы или секции должны храниться в памяти, после чего произвести удаление аналитических индексов для ускорения OLTP-запросов. При этом система управления базами данных автоматически задействует все доступные слои хранения (жесткие диски с «холодными» данными, оперативную память с «горячими» данными и твердотельные флеш-накопители с «активными» данными) и будет прозрачно для приложений и пользователя перемещать между ними обрабатываемую СУБД информацию.
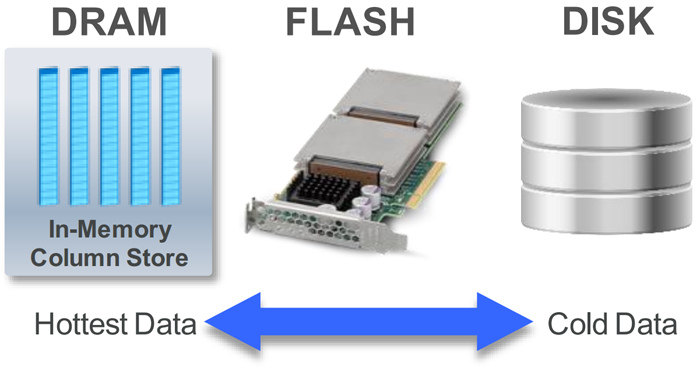
Oracle Database In-Memory позволяет прозрачно для приложений использовать все слои хранения данных
Поддержка работы Database In-Memory с базами данных любого размера обеспечивается благодаря реализованным в Oracle Database 12c механизмам масштабирования как посредством наращивания вычислительных мощностей отдельных машин, так и путем объединения нескольких серверов в кластер. В последнем случае с целью обеспечения надежности хранения обрабатываемых данных СУБД будет автоматически «размазывать» запросы по всем узлам кластера и создавать дубликаты хранимых в их оперативной памяти таблиц — опять-таки абсолютно прозрачно для приложений и оператора баз данных. Дублирование информации позволяет исключить простои вычислительного комплекса при сбое входящих в состав кластера узлов и гарантирует высокую доступность данных, что особенно важно при развертывании больших хранилищ данных и бизнес-критических систем.
Database In-Memory является оптимальным решением для предприятий, стремящихся повысить производительность своих бизнес-систем с минимальными организационными, квалификационными и финансовыми усилиями. Решение позволяет получать практически мгновенный отклик на аналитические запросы из BI-приложений, независимо от того, какие показатели и размерности в них используются. Также оно не требует переписывания программного кода продуктов и переобучения IT-специалистов или приобретения дорогостоящего вычислительного оборудования. Все эти особенности новой технологии вкупе с поддержкой баз данных любого размера и масштаба, по мнению Oracle, и станут составляющими успеха Database In-Memory на российском и мировом IT-рынках. В компании возлагают большие надежды на свой новый продукт и убеждены, что его включение в состав флагманской СУБД Oracle Database 12c сыграет важную роль в мире Big Data и развитии новых технологий обработки данных в режиме реального времени.

