Консорциум MLCommons объявил новые результаты бенчмарка MLPerf Training v5.0, отметив быстрый рост и эволюцию в области ИИ, а также рекордное количество общих заявок и увеличение заявок для большинства тестов по сравнению с бенчмарком v4.1.
MLPerf Training v5.0 предложил новый бенчмарк предварительной подготовки большой языковой модели на основе Llama 3.1 405B, которая является самой большой ИИ-моделью в текущем наборе тестов обучения. Он заменил бенчмарк на основе gpt3 (gpt-3-175B), входивший в предыдущие версии MLPerf Training. Целевая группа MLPerf Training выбрала его, поскольку Llama 3.1 405B является конкурентоспособной моделью, представляющей современные LLM, включая последние обновления алгоритмов и обучение на большем количестве токенов. Llama 3.1 405B более чем в два раза больше gpt3 и использует в четыре раза большее контекстное окно.
Несмотря на то, что бенчмарк на основе Llama 3.1 405B был представлен только недавно, на него уже подано больше заявок, чем на предшественника на основе gpt3 в предыдущих раундах, отметил консорциум.

Источник изображения: NVIDIA
MLCommons сообщил, что рабочая группа MLPerf Training регулярно добавляет новые рабочие нагрузки в набор тестов, чтобы гарантировать, что он отражает тенденции отрасли. Результаты бенчмарка Training 5.0 показывают заметный рост производительности для новых бенчмарков, что указывает на то, что отрасль отдаёт приоритет новым рабочим нагрузкам обучения, а не старым.
Тест Stable Diffusion показал увеличение скорости в 2,28 раза для восьмичиповых систем по сравнению с версией 4.1, вышедшей шесть месяцев назад, а тест Llama 2.0 70B LoRA увеличил скорость в 2,10 раза по сравнению с версией 4.1; оба превзошли исторические ожидания роста производительности вычислений с течением времени в соответствии с законом Мура. Более старые тесты в наборе показали более скромные улучшения производительности.
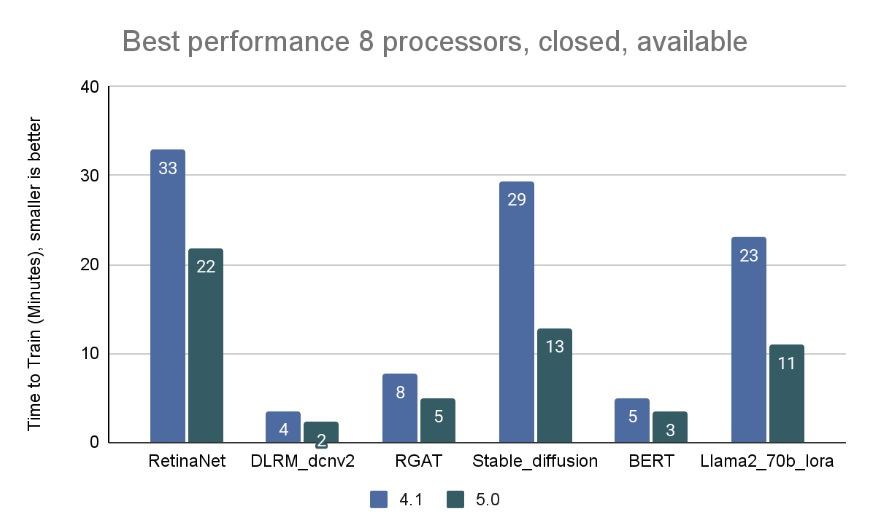
Источник изображений: MLCommons
На многоузловых 64-чиповых системах тест RetinaNet показал ускорение в 1,43 раза по сравнению с предыдущим раундом тестирования v3.1 (самым последним, включающим сопоставимые масштабные системы), в то время как тест Stable Diffusion показал резкое увеличение в 3,68 раза.
«Это признак надёжного цикла инноваций в технологиях и совместного проектирования: ИИ использует преимущества новых систем, но системы также развиваются для поддержки высокоприоритетных сценариев», — говорит Шрия Ришаб (Shriya Rishab), сопредседатель рабочей группы MLPerf Training.
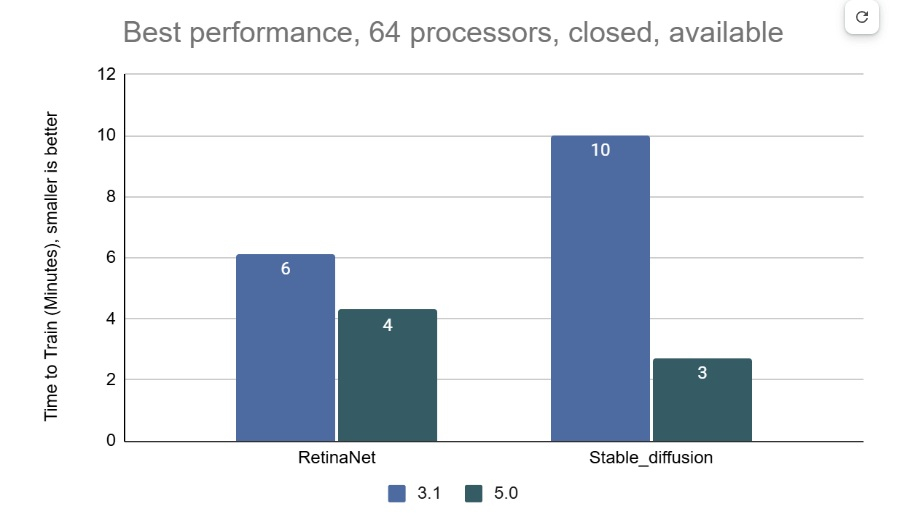
В заявках на MLPerf Training 5.0 использовалось 12 уникальных чиповых, все в категории коммерчески доступных. Пять из них стали общедоступными с момента выхода последней версии набора тестов MLPerf Training:
- AMD Instinct MI300X (192 Гбайт HBM3);
- AMD Instinct MI325X (256 Гбайт HBM3e);
- NVIDIA Blackwell GPU (GB200);
- NVIDIA Blackwell GPU (B200-SXM, 180 Гбайт HBM3e);
- TPU v6 Trillium.
Заявки также включали три новых семейства процессоров:
- Процессор AMD EPYC 9005 (Turin);
- Процессор Intel Xeon 6P (Granite Rapids);
- Arm Neoverse V2 (в составе NVIDIA GB200)
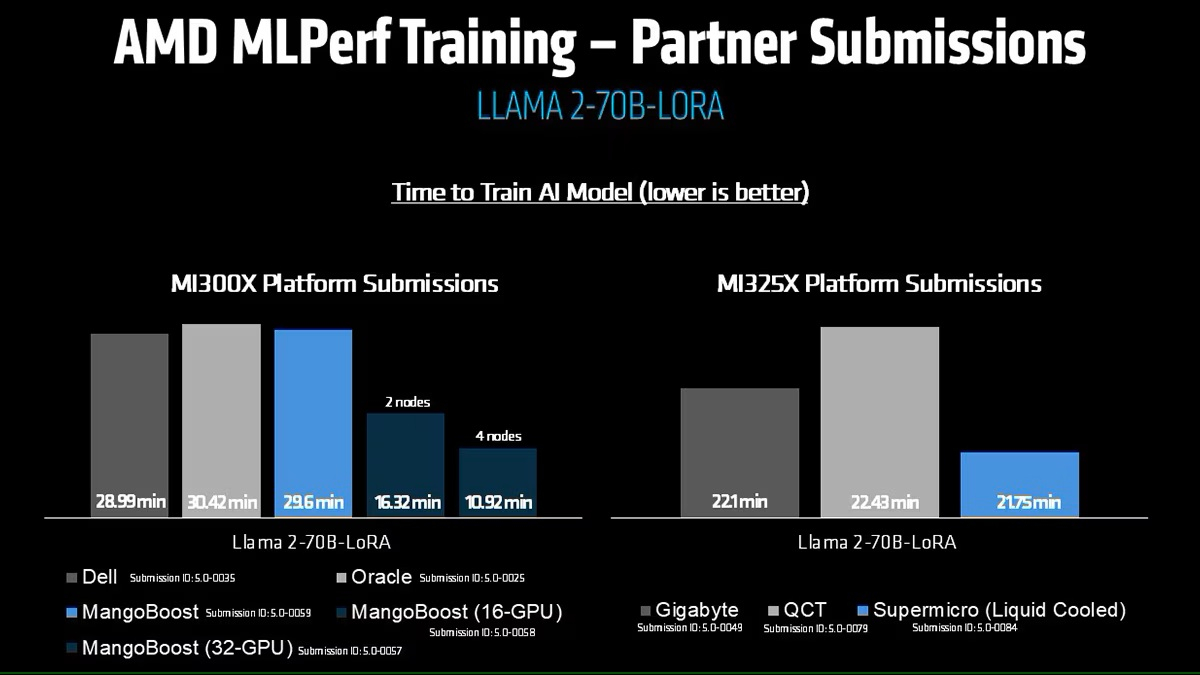
Кроме того, количество представленных многоузловых систем увеличилось более чем в 1,8 раза по сравнению с версией бенчмарка 4.1. Хиуот Касса (Hiwot Kassa), сопредседатель рабочей группы MLPerf Training, отметил растущее число провайдеров облачных услуг, предлагающих доступ к крупномасштабным системам, что делает доступ к обучению LLM более демократичным.
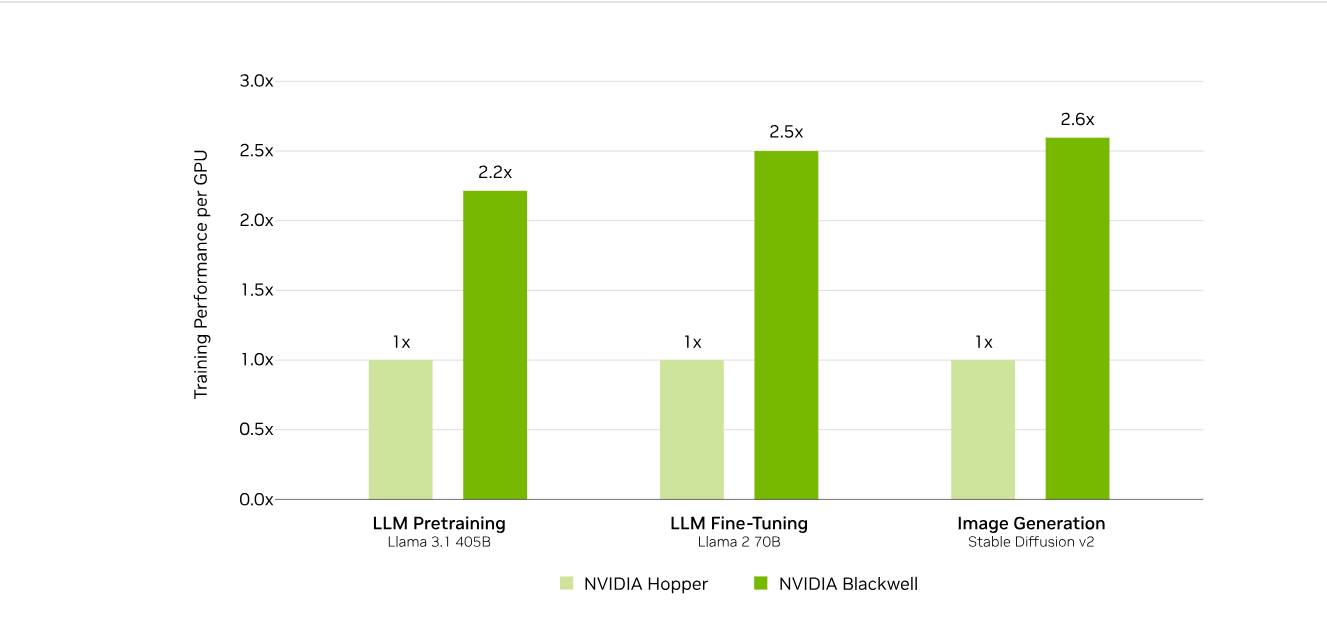
Источник изображений: NVIDIA
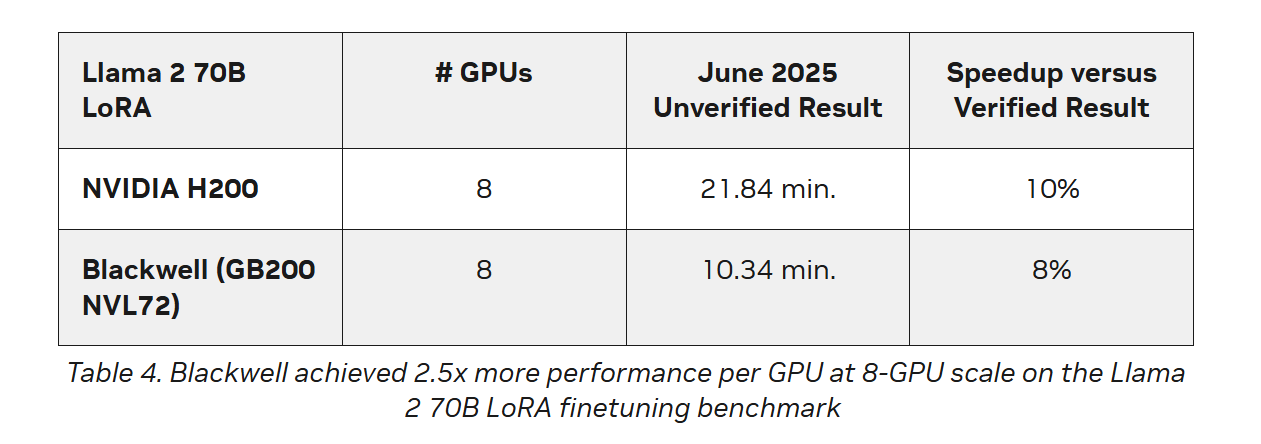
Последние результаты MLPerf Training 5.0 от NVIDIA показывают, что её ускорители Blackwell GB200 демонстрируют рекордные результаты по времени обучения, демонстрируя, как стоечная конструкция «ИИ-фабрики» компании может быстрее, чем раньше, превращать «сырые» вычислительные мощности в развёртываемые модели, пишет ресурс HPCwire.
Раунд MLPerf Training v5.0 включает 201 результат от 20 организаций-участников: AMD, ASUS, Cisco, CoreWeave, Dell, GigaComputing, Google Cloud, HPE, IBM, Krai, Lambda, Lenovo, MangoBoost, Nebius, NVIDIA, Oracle, QCT, SCITIX, Supermicro и TinyCorp. «Мы бы особенно хотели поприветствовать впервые подавших заявку на участие в MLPerf Training AMD, IBM, MangoBoost, Nebius и SCITIX, — сказал Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons. — Я также хотел бы выделить первый набор заявок Lenovo на результаты тестов энергопотребления в этом раунде — энергоэффективность в системе обучения ИИ-систем становится всё более важной проблемой, требующей точного измерения».
NVIDIA представила результаты кластера на основе систем GB200 NVL72, объединивших 2496 ускорителей. Работая с облачными партнерами CoreWeave и IBM, компания сообщила о 90-% эффективности масштабирования при расширении с 512 до 2496 ускорителей. Это отличный результат, поскольку линейное масштабирование редко достигается при увеличении количества ускорителей за пределами нескольких сотен. Эффективность масштабирования в диапазоне от 70 до 80 % уже считается солидным результатом, особенно при увеличении количества ускорителей в пять раз, пишет HPCwire.
В семи рабочих нагрузках в MLPerf Training 5.0 ускорители Blackwell улучшили время сходимости «до 2,6x» при постоянном количестве ускорителей по сравнению с поколением Hopper (H100). Самый большой рост наблюдался при генерации изображений и предварительном обучении LLM, где количество параметров и нагрузка на память самые большие.

Хотя в бенчмарке проверялась скорость выполнения операций, NVIDIA подчеркнула, что более быстрое выполнение задач означает меньшее время аренды облачных инстансов и более скромные счета за электроэнергию для локальных развёртываний. Хотя компания не публиковала данные об энергоэффективности в этом бенчмарке, она позиционировала Blackwell как «более экономичное» решение на основе достигнутых показателей, предполагая, что усовершенствования дизайна тензорных ядер обеспечивают лучшую производительность на Ватт, чем у поколения Hopper.
Также HPCwire отметил, что NVIDIA была единственным поставщиком, представившим результаты бенчмарка предварительной подготовки LLM на основе Llama 3.1 405B, установив начальную точку отсчёта для обучения с 405 млрд параметров. Это важно, поскольку некоторые компании уже выходят за рамки 70–80 млрд параметров для передовых ИИ-моделей. Демонстрация проверенного рецепта работы с 405 млрд параметров даёт компаниям более чёткое представление о том, что потребуется для создания ИИ-моделей следующего поколения.
В ходе пресс-конференции Дэйв Сальватор (Dave Salvator), директор по ускоренным вычислительным продуктам в NVIDIA, ответил на распространенный вопрос: «Зачем фокусироваться на обучении, когда в отрасли в настоящее время все внимание сосредоточено на инференсе?». Он сообщил, что тонкая настройка (после предварительного обучения) остается ключевым условием для реальных LLM, особенно для предприятий, использующих собственные данные. Он обозначил обучение как «фазу инвестиций», которая приносит отдачу позже в развёртываниях с большим объёмом инференса.
Этот подход соответствует более общей концепции «ИИ-фабрики» компании, в рамках которой ускорителям даются данные и питание для обучения моделей. А затем производятся токены для использования в реальных приложениях. К ним относятся новые «токены рассуждений» (reasoning tokens), используемые в агентских ИИ-системах.


NVIDIA также повторно представила результаты по Hopper, чтобы подчеркнуть, что H100 остаётся «единственной архитектурой, кроме Blackwell», которая показала лидерские показатели по всему набору MLPerf Training, хотя и уступила Blackwell. Поскольку инстансы на H100 широко доступны у провайдеров облачных сервисов, компания, похоже, стремится заверить клиентов, что существующие развёртывания по-прежнему имеют смысл.
Источник изображений: AMD
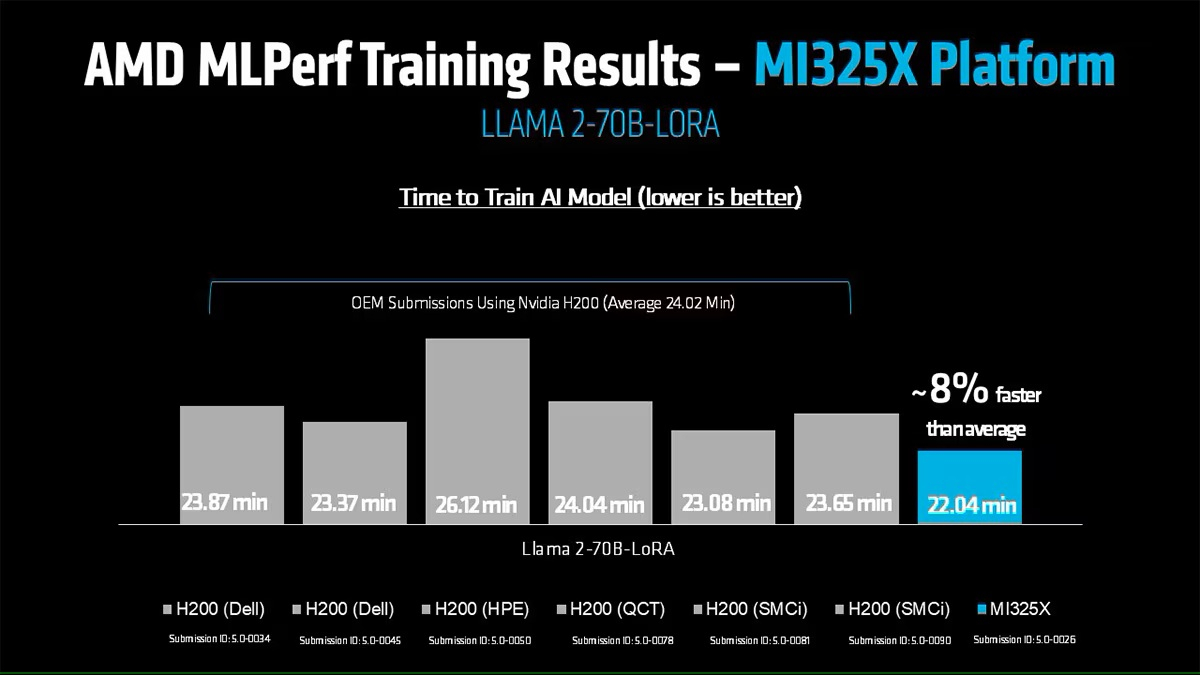
AMD, со своей стороны, продемонстрировала прирост производительности поколения чипов. В тесте Llama2 70B LoRA она показала 30-% прирост производительности AMD Instinct MI325X по сравнению с предшественником MI300X. Основное различие между ними заключается в том, что MI325X оснащён почти на треть более быстрой памятью.

В самом популярном тесте, тонкой настройке LLM, AMD продемонстрировала, что её новейший ускоритель Instinct MI325X показывает результаты наравне с NVIDIA H200. Это говорит о том, что AMD отстает от NVIDIA на одно поколение, отметил ресурс IEEE Spectrum.
AMD впервые представила результаты MLPerf Training, хотя в предыдущие годы другие компании представляли результаты в этом тесте, используя ускорители AMD. В свою очередь, Google представила результаты лишь одного теста, задачи генерации изображений, с использованием Trillium TPU.
Тест MLPerf также включает тест на энергопотребление, измеряющий, сколько энергии уходит на выполнение каждой задачи обучения. В этом раунде лишь Lenovo включила измерение этого показателя в свою заявку, что сделало невозможным сравнение между компаниями. Для тонкой настройки LLM на двух ускорителях Blackwell требуется 6,11 ГДж или 1698 КВт·ч — примерно столько энергии уходит на обогрев небольшого дома зимой.
Источники:

