Материалы по тегу: nvidia
|
11.04.2024 [15:23], Сергей Карасёв
Студенты США первыми в мире получили собственный ИИ-суперкомпьютер NVIDIAИнженерный колледж Технологического института Джорджии (Georgia Tech) объявил о заключении соглашения о сотрудничестве с NVIDIA с целью создания первого в мире суперкомпьютерного центра ИИ, предназначенного для обучения студентов. Проект получил название AI Makerspace. Отмечается, что AI Makerspace позволит демократизировать доступ к вычислительным ресурсам, которые традиционно были доступны только исследователям и технологическим компаниям. В рамках проекта студенты смогут использовать возможности НРС-комплекса для углубления своих навыков работы с ИИ. Это поможет в выполнении курсовых работ и позволит учащимся получить ценный практический опыт. Фактически AI Makerspace — это выделенный вычислительный кластер. В создании системы приняли участие специалисты Penguin Solutions. Применяется платформа для работы с ИИ-приложениями NVIDIA AI Enterprise. На начальном этапе в составе ИИ-суперкомпьютера задействованы 20 систем NVIDIA HGX H100, насчитывающие в общей сложности 160 ускорителей NVIDIA H100. В качестве интерконнекта применяется NVIDIA Quantum-2 InfiniBand. 
Источник изображения: Georgia Tech В рамках сотрудничества с Georgia Tech компания NVIDIA окажет поддержку студентам и преподавателям Инженерного колледжа по программе NVIDIA Deep Learning Institute (Институт глубокого обучения NVIDIA). Данная инициатива предусматривает все виды практикумов по ИИ, ускоренным вычислениям, графике, моделированию и другим современным технологиям. AI Makerspace расширяет базовую теоретическую учебную программу Georgia Tech по ИИ, предлагая студентам практическую платформу для решения реальных задач, разработки передовых приложений и реализации своих идей.
10.04.2024 [21:16], Владимир Мироненко
«Железо», ПО и доступ к инвесторам: NVIDIA и Google Cloud вместе помогут стартапам в области генеративного ИИNVIDIA и Google Cloud объявили о расширении сотрудничества, чтобы помочь стартапам в создании приложений и сервисов на базе генеративного ИИ. В рамках сотрудничества компании объединили программы NVIDIA Inception и Google for Startups Cloud Program, чтобы расширить доступ стартапам к облачным кредитам, предоставить им техническую экспертизу и помочь с выходом на рынок. Прошедшие отбор участники NVIDIA Inception, глобальной программы, уже поддерживающей более 18 тыс. стартапов, получат возможность использования инфраструктуры Google Cloud и облачные кредиты в размере до $350 тыс. А участники Google for Startups Cloud Program смогут присоединиться к NVIDIA Inception и получить доступ к знаниям, курсам NVIDIA Deep Learning Institute, «железу» и ПО NVIDIA и многому другому. 
Источник изображения: NVIDIA Более того, отобранные участники Google for Startups Cloud Program смогут присоединиться к платформе NVIDIA Inception Capital Connect, связывающей стартапы с венчурными капиталистами. Также разработчики ПО, участвующие в этих программах, смогут получить ускоренную адаптацию к Google Cloud Marketplace, поддержку совместного маркетинга и разработки продуктов. Ранее NVIDIA вместе с Google занялась оптимизацией моделей Gemma. Google Cloud анонсировала инстансы A3 Mega на базе ускорителей NVIDIA H100, которые отличаются вдвое большей пропускной способностью интерконнекта между ускорителями по сравнению с обычными A3. Наконец, было обещано, что в начале следующего года в Google Cloud появятся решения NVIDIA Blackwell: NVIDIA HGX B200 и NVIDIA GB200 NVL72.
08.04.2024 [11:35], Сергей Карасёв
BSC и NVIDIA займутся совместной разработкой HPC- и ИИ-решенийБарселонский суперкомпьютерный центр (Centro Nacional de Supercomputación, BSC-CNS) и NVIDIA объявили о заключении многолетнего соглашения о сотрудничестве, целью которого является совместная разработка инновационных решений, объединяющих технологии НРС и ИИ. Договор рассчитан на пять лет с возможностью последующего продления. При этом каждые шесть месяцев стороны намерены уточнять и оптимизировать направления сотрудничества. Новое соглашение будет действовать параллельно с ранее подписанным документом, касающимся совместных исследований в области сетевых решений. Первоначально сотрудничество между BSC и NVIDIA будет сосредоточено на разработке больших языковых моделей (LLM), а также приложений для метеорологии и анализа изменений климата. Кроме того, стороны займутся адаптацией вычислительной модели цифрового двойника сердца, разработанной в рамках проекта Alya, к различным платформам. Ещё одно направление работ — программная оптимизация процессов для GPU и архитектуры NVIDIA Grace с ядрами Arm, специально разработанной для ИИ и крупномасштабных суперкомпьютерных приложений. 
Источник изображения: BSC Предполагается также, что научный потенциал BSC вкупе с технологическими достижениями и опытом NVIDIA позволят максимизировать вычислительные возможности суперкомпьютера MareNostrum 5, который был запущен в Испании в конце 2023 года. Эта система, использующая ускорители NVIDIA H100, обладает производительностью 314 Пфлопс.
05.04.2024 [16:38], Владимир Мироненко
Nvidia и Indosat построят в Индонезии ИИ-центр стоимостью $200 млнNvidia и индонезийская телекоммуникационная компания Indosat Ooredoo Hutchison планируют построить ИИ-центр стоимостью $200 млн в Центральной Яве, провинции Индонезии, являющейся крупнейшей экономикой Юго-Восточной Азии. Об этом сообщило агентство Reuters со ссылкой на заявление министра связи страны Буди Арие Сетиади (Budi Arie Setiadi). Согласно заявлению Министерства связи и информатики Индонезии, новый ИИ-центр будет построен в Суракарте в конце этого года. «Почему в Суракарте? Потому что они готовы, имеют хорошие человеческие ресурсы и инфраструктуру 5G», — отметил глава ведомства. По словам представителя Indosat Стива Саеранга (Steve Saerang), сотрудничество с Nvidia будет способствовать развитию технологической инфраструктуры в Индонезии. Indosat в настоящее время более глубоко углубляется в сферу цифровых сервисов, стремясь выйти за рамки телекоммуникаций и предлагать более широкий спектр услуг, пишет Nikkei Asia. 
Источник изображения: NVIDIA В свою очередь замминистра связи Незар Патриа (Nezar Patria) отметил, что сотрудничество носит стратегический характер и выразил надежду, что будет также осуществляться передача технологий, чтобы в дальнейшем Индонезия могла стать «частью игроков в области ИИ, которые принимаются во внимание как на региональном, так и на глобальном уровне». Партнёрство с Indosat является следующим этапом наращивания присутствия Nvidia в Юго-Восточной Азии, включая Сингапур и Малайзию. В январе Singapore Telecommunication (Singtel) объявила о сотрудничестве с Nvidia для развёртывания возможностей ИИ в своих ЦОД. YTLP Group из Малайзии заявила, что запускает первое в стране облако ИИ с использованием ускорителей Nvidia Blackwell.
29.03.2024 [21:54], Сергей Карасёв
Eviden увеличит производительность французского суперкомпьютера Jean Zay более чем втроеФранцузское национальное агентство по высокопроизводительным вычислениям (GENCI) и Национальный центр научных исследований (CNRS) заключили соглашение с компанией Eviden (дочерняя структура Atos) о модернизации НРС-комплекса Jean Zay. Ожидается, что производительность этого суперкомпьютера увеличится приблизительно в 3,5 раза. В рамках проекта Eviden оборудует комплекс 1456 ускорителями NVIDIA H100 в дополнение к 416 ускорителям NVIDIA A100 и 1832 ускорителям NVIDIA V100, которые задействованы в настоящее время. Модернизация предполагает использование 14 стоек суперкомпьютерной платформы Eviden BullSequana XH3000. В общей сложности будут задействованы 364 двухпроцессорных узла на базе Intel Xeon Sapphire Rapids с 48 ядрами. Каждый сервер получит 512 Гбайт оперативной памяти и четыре ускорителя NVIDIA H100 SXM5. Говорится об использовании адаптеров NVIDIA ConnectX-7. 
Источник изображения: Eviden Проект также предусматривает комплексное обновление подсистемы хранения данных. Она будет состоять из флеш-массива вместимостью 4,3 Пбайт со скоростями чтения/записи свыше 1 Тбайт/с и дискового массива ёмкостью 39 Пбайт со скоростями чтения/записи более 300 Гбайт/с. Компоненты СХД поставит компания DataDirect Networks (DDN). Для обоих уровней хранения предусмотрено использование файловой системы Lustre. 
Фото: Photothèque CNRS/Cyril Frésillon Ожидается, что модернизация позволит увеличить пиковую производительность Jean Zay с 36,85 до 125,9 Пфлопс. Проект получил финансирование в рамках национальной инвестиционной программы «Франция 2030». Усовершенствованный суперкомпьютер будет использоваться для решения ресурсоёмких задач, в том числе в области ИИ. Отмечается, что Jean Zay — это один из наиболее экологичных суперкомпьютеров в Европе. Отчасти это достигается благодаря использованию генерируемого машиной тепла для обогрева более 1000 зданий в кампусе Париж-Сакле.
28.03.2024 [14:43], Сергей Карасёв
DDN создала хранилище с быстродействием 4 Тбайт/с для ИИ-суперкомпьютера NVIDIA EOSКомпания DataDirect Networks (DDN), специализирующаяся на платформах хранения данных для НРС-задач, сообщила о создании высокопроизводительного хранилища на базе DDN EXAScaler AI (A3I — Accelerated, Any-Scale AI) для ИИ-суперкомпьютера NVIDIA EOS производительностью 18,4 Эфлопс (FP8). Речь идёт о кластере, объединяющем 576 систем NVIDIA DGX H100. Компания DDN заявляет, что разработала для NVIDIA EOS систему хранения с высокими показателями быстродействия и энергетической эффективности. Объединены 48 устройств A3I, которые сообща занимают менее трёх серверных стоек. Потребляемая мощность заявлена на отметке 100 кВт. 
Источник изображения: DDN Задействованы 250-Тбайт массивы NVMe-накопителей. Суммарная ёмкость СХД составляет 12 Пбайт. Общая пропускная способность, по заявлениям разработчика, достигает 4 Тбайт/с. Таким образом, система способна справляться с самыми ресурсоёмкими рабочими нагрузками ИИ, большими языковыми моделями, комплексным моделированием и пр. «Наша цель — обеспечение максимальной эффективности всей платформы, а не просто предоставление эффективного хранилища. Благодаря интеграции с суперкомпьютером NVIDIA EOS наше решение демонстрирует способность сократить время окупаемости при одновременном снижении рисков как для локальных, так и для облачных партнёров», — говорит президент и соучредитель DDN.
27.03.2024 [22:29], Алексей Степин
Новый бенчмарк — новый рекорд: NVIDIA подтвердила лидерские позиции в MLPerf InferenceКомпания NVIDIA опубликовала новые, ещё более впечатляющие результаты в области работы с большими языковыми моделями (LLM) в бенчмарке MLPerf Inference 4.0. За прошедшие полгода и без того высокие результаты, демонстрируемые архитектурой Hopper в инференс-сценариях, удалось улучшить практически втрое. Столь внушительный результат достигнут благодаря как аппаратным улучшениям в ускорителях H200, так и программным оптимизациям. Генеративный ИИ буквально взорвал индустрию: за последние десять лет вычислительная мощность, затрачиваемая на обучение нейросетей, выросла на шесть порядков, а LLM с триллионом параметров уже не являются чем-то необычным. Однако и инференс подобных моделей тоже является непростой задачей, к которой NVIDIA подходит комплексно, используя, по её же собственным словам, «многомерную оптимизацию». 
Источник изображений: NVIDIA Одним из ключевых инструментов является TensorRT-LLM, включающий в себя компилятор и прочие средства разработки, учитывающие архитектуру ускорителей компании. Благодаря ему удалось почти втрое повысить производительность инференса GPT-J на ускорителях H100 всего за полгода. Такой прирост достигнут благодаря оптимизации очередей на лету (inflight sequence batching), применению страничного KV-кеша (paged KV cache), тензорному параллелизма (распределение весов по ускорителям), FP8-квантизации и использованию нового ядра XQA (XQA kernel). 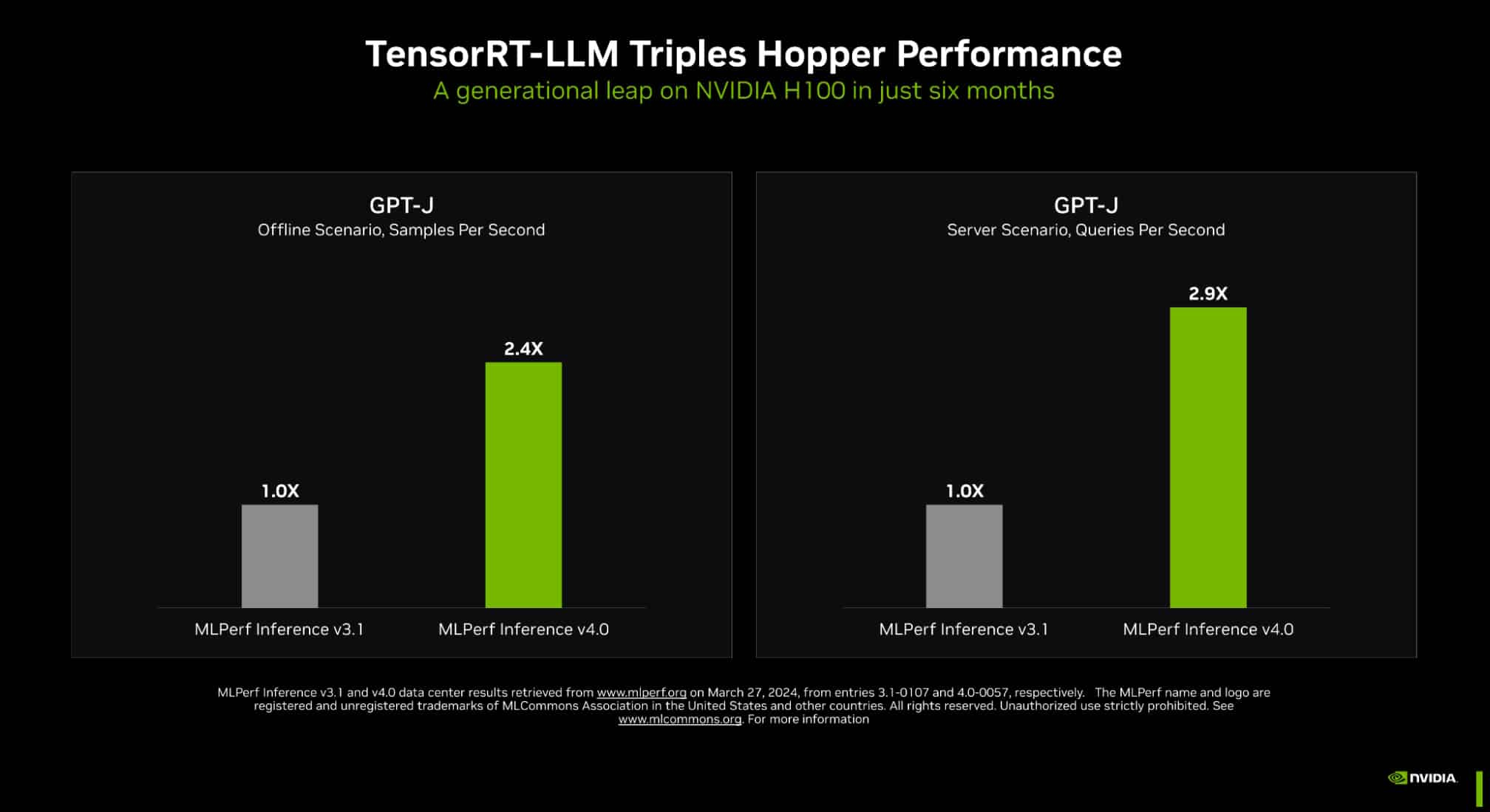 В случае ускорителей H200, использующих ту же архитектуру Hopper, что и H100, важную роль играет память: 141 Гбайт HBM3e (4,8 Тбайт/с) против 80 Гбайт HBM3 (3,35 Тбайт/с). Такой объём позволяет разместить модель уровня Llama 2 70B целиком в локальной памяти. В тесте MLPerf Llama 2 70B ускорители H200 на 28 % производительнее H100 при том же теплопакете 700 Вт, а увеличение теплопакета до 1000 Вт (так делают некоторые вендоры в своих MGX-платформах) даёт ещё 11–14 % прироста, а итоговая разница с H100 в этом тесте может доходить до 45 %. 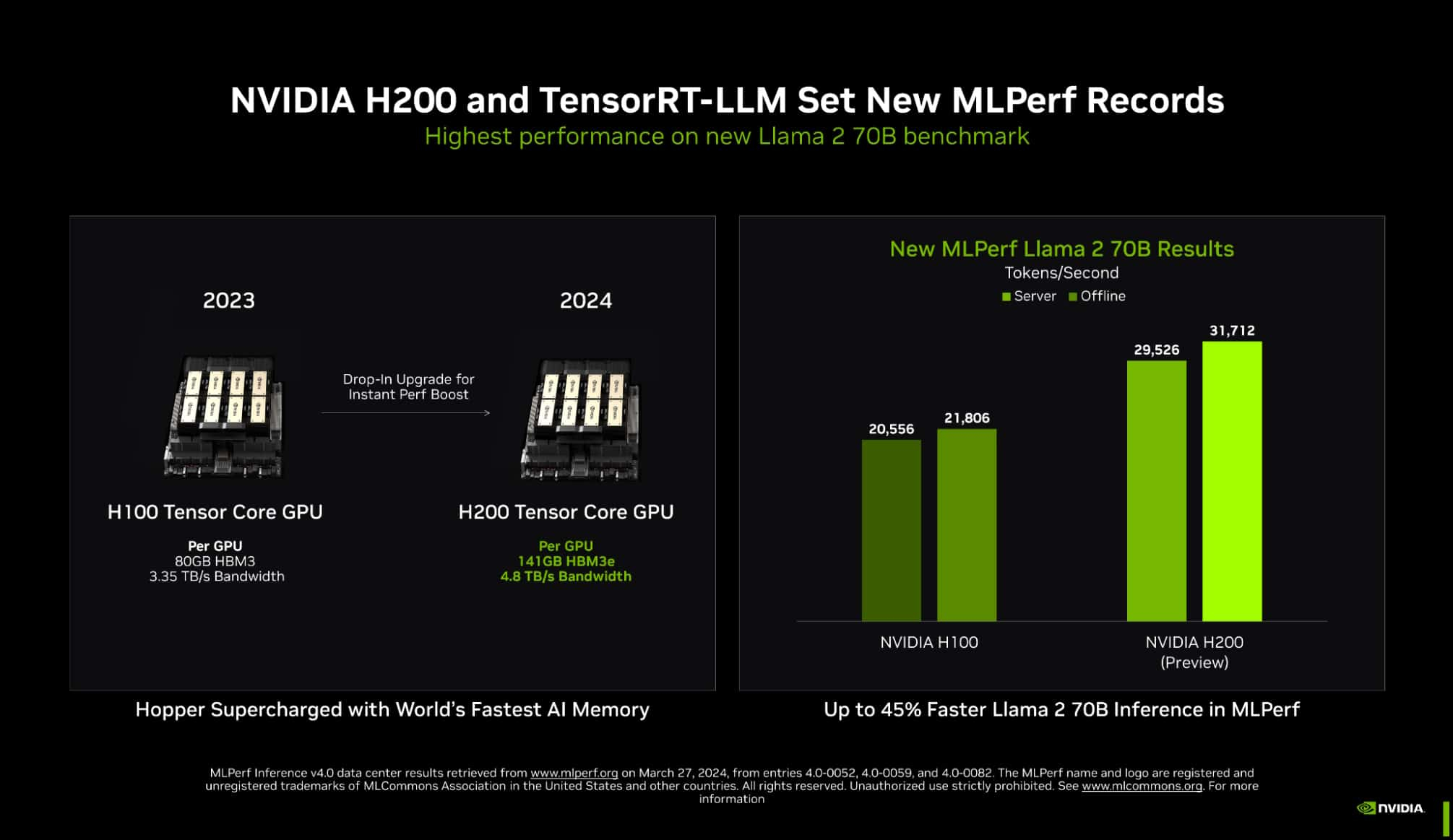 В специальном разделе новой версии MLPerf NVIDIA продемонстрировала несколько любопытных техник дальнейшей оптимизации: «структурированную разреженность» (structured sparsity), позволяющую поднять производительность в тесте Llama 2 на 33 %, «обрезку» (pruning), упрощающую ИИ-модель и позволяющую повысить скорость инференса ещё на 40 %, а также DeepCache, упрощающую вычисления для Stable Diffusion XL и дающую до 74 % прироста производительности. На сегодня платформа на базе модулей H200, по словам NVIDIA, является самой быстрой инференс-платформой среди доступных. Результатами GH200 компания похвасталась ещё в прошлом раунде, а вот показатели ускорителей Blackwell она не предоставила. Впрочем, не все считают результаты MLPerf показательными. Например, Groq принципиально не участвует в этом бенчмарке.
23.03.2024 [16:02], Сергей Карасёв
Supermicro представила ИИ-системы SuperCluster с ускорителями NVIDIA H100/H200 и суперчипами GH200Компания Supermicro анонсировала вычислительные кластеры SuperCluster с ускорителями NVIDIA, предназначенные для обработки наиболее ресурсоёмких приложений ИИ и обучения больших языковых моделей (LLM). Дебютировали системы, оснащённые жидкостным и воздушным охлаждением. В частности, представлен комплекс SuperCluster в составе пяти стоек на основе 4U-узлов СЖО. Каждый из узлов может нести на борту два процессора Intel Xeon Sapphire Rapids / Xeon Emerald Rapids или два чипа AMD EPYC 9004 (Genoa), дополненные памятью DDR5-5600. Доступны восемь фронтальных отсеков для SFF-накопителей NVMe и два слота M.2 NVMe. Каждый из узлов рассчитан на установку восьми ускорителей NVIDIA H100 или H200. Таким образом, в общей сложности SuperCluster с 32 узлами насчитывает до 256 ускорителей. Говорится о применении интерконнекта NVIDIA Quantum-2 InfiniBand, а также Ethernet-технологии NVIDIA Spectrum-X. Используется платформа для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая теперь включает микросервисы на базе загружаемых контейнеров. 
Источник изображений: Supermicro Ещё одна система SuperCluster предусматривает конфигурацию из девяти стоек с узлами в форм-факторе 8U с воздушным охлаждением. У таких узлов во фронтальной части находятся 12 отсеков для SFF-накопителей NVMe и три отсека для SFF-устройств с интерфейсом SATA. В остальном характеристики аналогичны решениям типоразмера 4U. Общее количество узлов в системе равно 32.  Кроме того, вышел комплекс SuperCluster с девятью стойками на основе узлов 1U с воздушным охлаждением. Эти узлы комплектуются суперчипом NVIDIA GH200 Grace Hopper. Есть восемь посадочных мест для накопителей E1.S NVMe и два коннектора M.2 NVMe. В кластере объединены 256 узлов. Отмечается, что данная система оптимизирована для задач инференса в облачном масштабе.
22.03.2024 [15:44], Владимир Мироненко
Schneider Electric и NVIDIA разработают эталонные проекты инфраструктуры ЦОД для ИИ-нагрузокФранцузская корпорация Schneider Electric объявила о сотрудничестве с NVIDIA с целью оптимизации инфраструктуры ЦОД, что позволит добиться новых достижений в области искусственного интеллекта (ИИ) и технологий цифровых двойников. Используя опыт в области инфраструктуры ЦОД и передовые ИИ-технологии NVIDIA, Schneider Electric разработает первые в своём роде общедоступные эталонные проекты дата-центров, призванные переопределить стандарты развёртывания и эксплуатации ИИ в экосистемах ЦОД. Эти проекты будут адаптированы для кластеров ускорителей NVIDIA и предназначены для поддержки нагрузок инженерного моделирования, автоматизации электронного проектирования, автоматизированного проектирования лекарств и генеративного ИИ. Особое внимание будет уделено обеспечению системам распределения большой мощности, системам жидкостного охлаждения и средствам управления для обеспечения простого ввода в эксплуатацию и надёжной работы высокоплотных кластеров. Эталонные проекты предложат надёжную основу для внедрения аппаратных платформ NVIDIA в ЦОД, одновременно оптимизируя производительность, масштабируемость и общую устойчивость объектов. Эти же проекты можно будет использовать для развёртывания ИИ-серверов высокой плотности в существующих ЦОД. 
Изображение: Steve Johnson / Unsplash В рамках объявленного сотрудничества AVEVA, дочерняя компания Schneider Electric, подключит свою платформу цифровых двойников к NVIDIA Omniverse, создав единую среду для виртуального моделирования и совместной работы. Это позволит ускорить проектирование и развёртывание сложных систем, а также сократить время их вывода на рынок и затраты. «Технологии NVIDIA расширяют возможности AVEVA по созданию реалистичного и захватывающего опыта совместной работы, основанного на богатых данных и возможностях интеллектуального цифрового двойника AVEVA», — отметил глава AVEVA.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data. |
|

