Материалы по тегу: hardware
|
19.05.2024 [22:45], Владимир Мироненко
HPE анонсировала подписку HPE Timeless для платформы GreenLake Alletra MPHPE расширила функциональность платформы GreenLake, что позволит упростить и оптимизировать управление данными, хранилищем и рабочими нагрузками пользователей в локальных и облачных средах, сообщил ресурс SiliconANGLE. Новые предложения включают в себя возможности блочного хранилища HPE GreenLake для облака Amazon Web Services, новую версию HPE GreenLake для блочного хранилища с повышением производительности, а также программу HPE Timeless, обеспечивающую более высокий уровень защиты клиентов, использующих блочное хранилище данных HPE GreenLake Alletra MP. В частности, доступно обновление контроллеров без прерывания работы СХД. 
Источник изображения: HPE Программа HPE Timeless, запуск которой намечен на III квартал 2024 года, призвана изменить процесс владения СХД для компаний, добавив «защиту инвестиций» и более оптимизированный жизненный цикл инфраструктуры, сообщили в HPE. В рамках программы, клиенты, использующие HPE Alletra MP, будут иметь право на замену контроллера на модель следующего поколения при каждом продлении подписки. В этом случае клиенту не придётся самому заниматься обновлениями аппаратного и программного обеспечения. Новая программа включает в себя 100 % гарантию доступности данных HPE и гарантию HPE StoreMore. Для бесперебойного обновления хранилище HPE Alletra MP должно иметь несколько контроллеров, а также возможность аварийного переключения и восстановления и поддержку со стороны ОС. HPE Timeless похожа на программу Pure Storage EverGreen для клиентов, использующих флеш-массивы FLashArray и FlashBlade. Подписку Storage Assurance с похожими условиями запустила в прошлом месяце и IBM.
19.05.2024 [18:07], Игорь Осколков
Phison представила новый бренд серверных SSD PASCARI и накопители X200 с PCIe 5.0Phison представила собственный бренд SSD корпоративного класса PASCARI, который включает сразу несколько различных серий: X, AI, D, S и B. Новинки представлены в форм-факторах E1.S, E3.S, U.3/U.2, M.2 2280/22110 и SFF 2,5″ и наделены интерфейсами SATA-3 и PCIe 4.0/5.0. Наиболее интересна серия AI (или aiDAPTIVCache), которая фактически является частью программно-аппаратного комплекса aiDAPTIV+. Пока упоминается только один M.2 SSD — AI100E. Это сверхбыстрые и сверхнадёжные 2-Тбайт NVMe-накопители на базе SLC NAND (вероятно, всё же eSLC) с DWPD, равным 100 на протяжении трёх или пяти лет (в материалах указаны разные сроки). Аналогичные накопители, хотя и в более крупном форм-факторе, предлагают Micron и Solidigm, а Kioxia в прошлом году анонсировала накопители на базе XL-Flash второго поколения с MLC NAND. Во всех случаях, по сути, речь идёт об SCM (Storage Class Memory). Наиболее ярким представителем данной категории была почившая серия продуктов Intel Optane. Phison переняла общую идею перестройки иерархии памяти, где SCM является ещё одним слоем между DRAM и массивом SSD, приложив её к задачам обучения ИИ. AI100E являются кеширующими накопителями, расширяющими доступную память. Программная прослойка aiDAPTIVLink общается с ускорителями NVIDIA и SSD с одной стороны и с PyTorch (также есть упоминание TensorFlow) — с другой. 
Источник изображений: Phison aiDAPTIVLink позволяет автоматически и прозрачно переносить на SSD неиспользуемые в текущий момент части обучаемой LLM и по необходимости отправлять их сначала в системную RAM, а потом и в память ускорителя, что и позволяет обходиться меньшим числом ускорителей при тренировке действительно больших моделей. Естественно, никакого чуда здесь не происходит, поскольку время обучения от этого нисколько не сокращается, но с другой стороны, обучение становится в принципе возможным на системах с малым количеством ускорителей или просто с относительно слабыми GPU и относительно небольшим же объёмом системной RAM.  Среди уже поддерживаемых моделей упомянуты некоторые LLM семейств Llama, Mistral, ResNet и т.д. Для них, как заявляется, не нужны никакие модификации для работы с aiDAPTIV+. Также упомянута возможность горизонтального масштабирования при использовании данной технологии. Точные характеристики AI100E компания не приводит, но это и не так существенно, поскольку напрямую продавать эти накопители она не собирается. Вместо этого они будут предлагаться в составе готовых и полностью укомплектованных рабочих станций или серверов. Семейство PASCARI X включает сразу четыре серии накопителей. Так, X200E (DWPD 3) и X200P (DWPD 1) — это двухпортовые накопители на базе TLC NAND с интерфейсом PCIe 5.0 x4, представленные в форм-факторах U.2 и E3.S. Пиковые скорости последовательного чтения и записи составляют 14,8 Гбайт/с и 8,35 Гбайт/с соответственно. На случайных операциях с 4K-блоками производительность чтения достигает 3 млн IOPS, а записи — 900 тыс. IOPS у X200E и 500 тыс. IOPS у X200P. Здесь и далее даны только крайние показатели в рамках серии, а не отдельного накопителя.  Ёмкость X200E составляет 1,6–12,8 Тбайт, но также готовится 25,6-Тбайт U.2-версия. У X200P диапазон ёмкостей простирается от 1,92 Тбайт до 15,36 Тбайт, но опять-таки будет 30,72-Тбайт вариант в U.2-исполнении. Отмечается поддержка MF-QoS (QoS для различных нагрузок), поддержка 64 пространств имён, MTBF на уровне 2,5 млн часов, сквозная защита целостности передаваемых данных, улучшенная защита от потери питания и т.д. У X100E (DWPD 3) и X200P (DWPD 1) среди возможностей дополнительно упомянуты поддержка TCG Opal 2.0, NVMe-MI, шифрования AES-256, безопасной очистки и т.д. От X200 эти накопители отличаются в первую очередь интерфейсом PCIe 4.0 x4 (возможны два порта x2). Выпускаются они только в форм-факторе U.3/U.2. X100E предлагают ёмкость от 1,6 Тбайт до 25,6 Тбайт, а X100P — от 1,92 Тбайт до 30,72 Тбайт. Пиковые скорости последовательного чтения и записи в обоих случаях достигают 7 Гбайт/с. Произвольное чтение 4K-блоками — до 1,7 млн IOPS, а вот запись у X100E упирается в 480 тыс. IOPS, тогда как у X100P и вовсе не превышает 190 тыс. IOPS.  В семейство PASCARI D входит всего одна серия компактных накопителей D100P на базе TLC NAND с интерфейсом PCIe 4.0 x4 (один порт, NVMe 1.4), представленная в форм-факторах M.2 2280 (от 480 Гбайт до 1,92 Тбайт), M.2 22110 (от 480 Гбайт до 3,84 Тбайт) и E1.S (тоже от 480 Гбайт до 1,92 Тбайт). Производительность M.2-вариантов составляет до 6 Гбайт/с и 2 Гбайт/с на последовательных операциях чтения и записи, а на случайных — до 800 тыс. IOPS и 60 тыс. IOPS соответственно. E1.S-версия чуть быстрее в чтении — до 6,8 Гбайт/с. Надёжность — 1 DWPD. Среди особенностей вендор выделяет сквозную защиту целостности данных, LPDC-движок четвёртого поколения, поддержку NVMe-MI и т.п.  PASCARI B включает серию загрузочных накопителей B100P: M.2 2280 (будет и 22110), TLC NAND, PCIe 4.0 x4, 1 DWPD и те же функции, что у D100P. Доступны только накопители ёмкостью 480 Гбайт и 960 Гбайт. Скоростные характеристики относительно скромны. Последовательные чтение и запись не превышают 5 Гбайт/с и 700 Мбайт/с, а произвольные — 450 тыс. IOPS и 30 тыс. IOPS. Также к PASCARI B принадлежит серия BA50P: SATA-накопители в форм-факторах M.2 2280 и SFF 2,5″ на базе TLC NAND с DWPD 1 и ёмкостью 240/480/960 Гбайт. Скорости чтения/записи не превышают 530/500 Мбайт/с при последовательном доступе, и 90/20 тыс. IOPS при случайном доступе 4K-блоками.  Наконец, семейство PASCARI S представлено тремя сериями SFF-накопителей (2,5″) с TLC-памятью и интерфейсом SATA-3, отличающихся в первую очередь опять-таки показателем надёжности: SA50E (3 DWPD), SA50P (1 DWPD) и SA50E (>0,4 DWPD). SA50E имеют ёмкость от 480 Гбайт до 3,84 Тбайт, SA50P — от 480 Гбайт до 7,68 Тбайт, а SA50E — от 1,92 Тбайт до 15,36 Тбайт. Отличаются и максимальные скорости произвольного чтения/записи 4K-блоками: 98/60 тыс., 98/40 тыс. и 97/20 тыс. IOPS соответственно. А вот последовательные чтение и запись естественным образом ограничены самим интерфейсом, т.е. не превышают 530 Мбайт/с и 500 Мбайт/с соответственно. В описании упомянуты сквозная защита целостности данных, LPDC-движок и улучшенная защита от потери питания. Для вообще всех накопителей заявленный диапазон рабочих температур простирается от 0 до 70 °C. А вот срок гарантии не указан, так что показатели DWPD теряют смысл. Кроме того, Phison практически для каждой серии говорит о возможности кастомизации. Например, для X100 предлагаются услуги IMAGIN+.
18.05.2024 [20:00], Алексей Степин
256 ядер и 12 каналов DDR5: Ampere обновила серверные Arm-процессоры AmpereOne и перевела их на 3-нм техпроцессВесной прошлого года компания Ampere Computing анонсировала наследников серии процессоров Altra и Altra Max — чипы AmpereOne с более высокими показателями производительности, энергоэффективности и масштабируемости. На момент анонса AmpereOne получили до 192 ядер, восемь каналов DDR5 и 128 линий PCIe 5.0. Кроме того, эти чипы могут работать и в двухсокетных платформах. Позднее AmpereOne стали доступны у нескольких облачных провайдеров, а главным бенефециаром их появления стала Oracle, когда-то инвестировавшая в Ampere Computing значительные средства. Компания перевела все свои облачные сервисы на процессоры Ampere и даже портировала на них свою флагманскую СУБД. В общем, повторила путь AWS и Alibaba Cloud с процессорами Graviton и Yitian соответственно. Но если последние являются облачным эксклюзивом, то чипы Ampere хоть и ориентированы в первую очередь на гиперскейлеров, более-менее доступны и небольшим компаниям. Поэтому в процессорной гонке останавливаться нельзя, так что на днях Ampere объявила об обновлении модельного ряда AmpereOne, запланированного к выпуску в 2025 году. Новые модели будут использовать продвинутый техпроцесс TSMC N3. 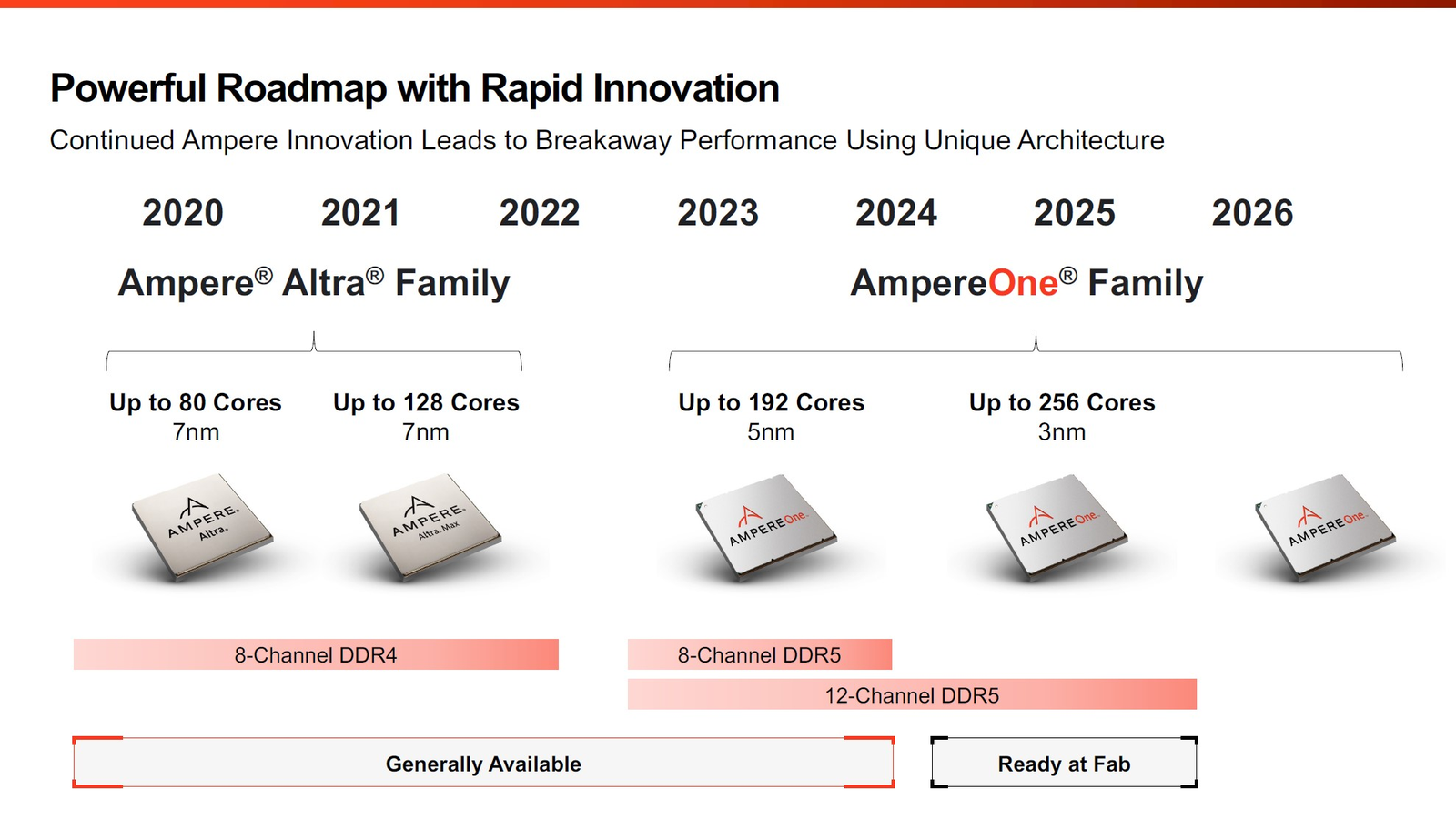
Источник здесь и далее: Ampere Computing via ServeTheHome Согласно опубликованным планам, семейство AmpereOne какое-то время будет существовать в двух ипостасях: изначальном варианте 2023 года с 8-канальным контроллером памяти и 192 ядрами в пределе, производящемся с использованием 5-нм техпроцесса, и новом 3-нм, уже готовом к массовому производству. Ожидается, что 192-ядерный вариант с 12 каналами DDR5 станет доступен в конце этого года. 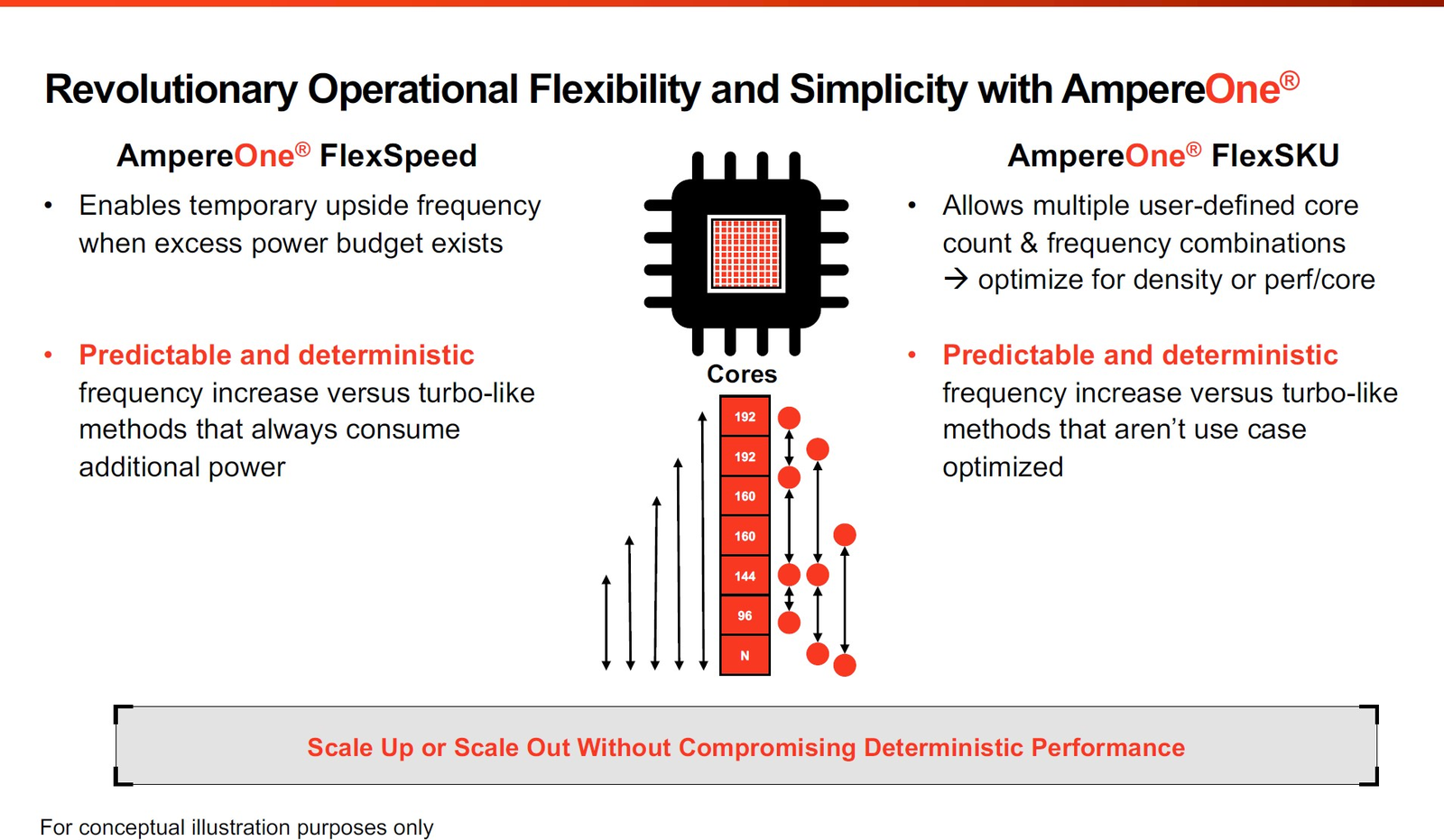
Фирменные технологии Ampere серии Flex позволят гибко управлять характеристиками платформы 3-нм вариант AmpereOne получит до 256 ядер и 12 каналов DDR5, однако отличать его будет не только это. К примеру, в нём дебютируют технологии FlexSpeed и FlexSKU, позволяющие на лету, без перезагрузок или выключения системы оперировать различными параметрами процессора — тактовой частотой, теплопакетом и даже количеством активных ядер. При этом FlexSpeed обеспечит детерминированный прирост производительности в отличие от x86-64, говорит компания. 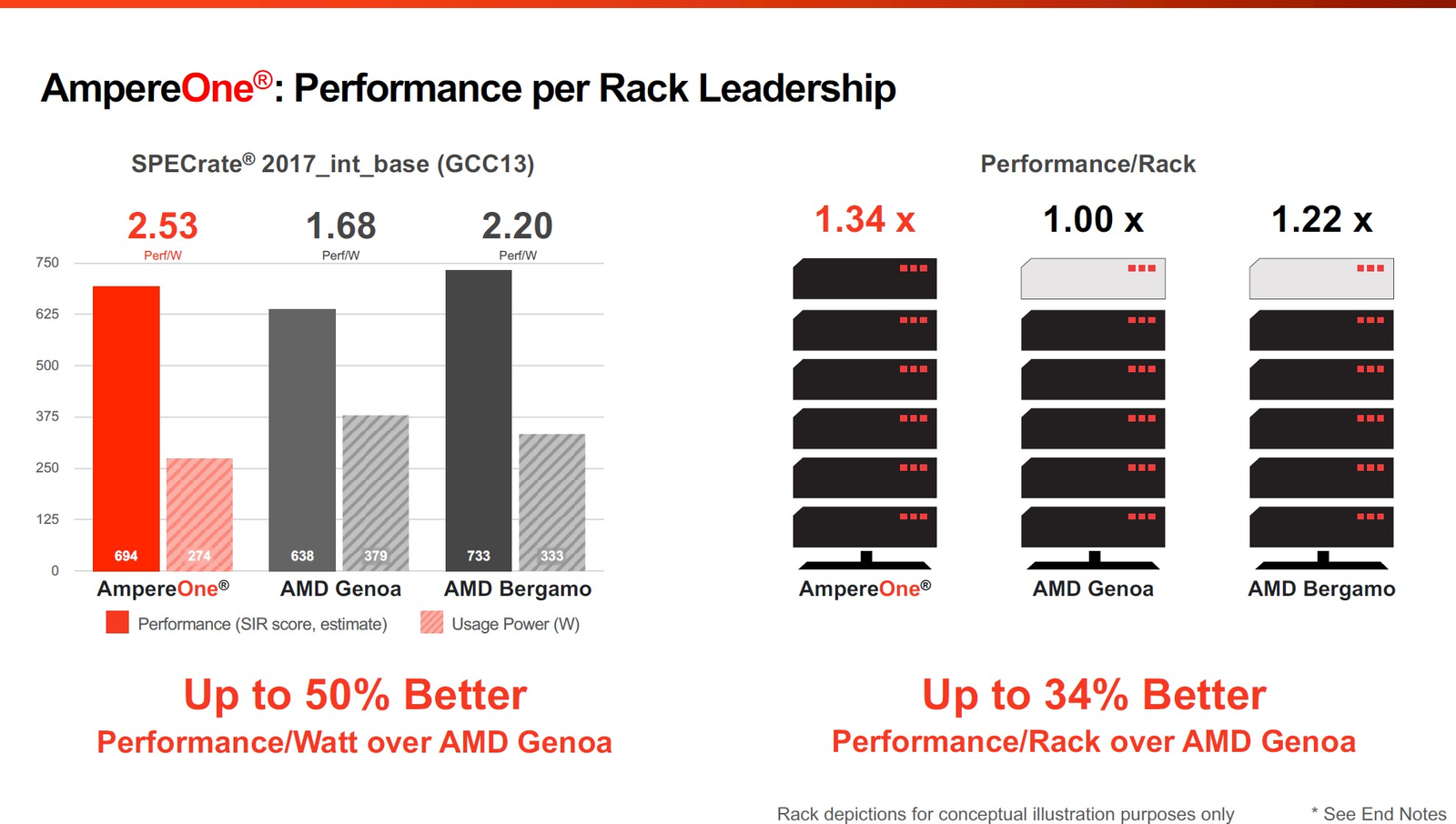 Ampere утверждает, что новые AmpereOne превзойдут в удельной производительности на Вт AMD EPYC Bergamo и обеспечат более высокую производительность в пересчёте на стойку, нежели AMD EPYC Genoa. Особенное внимание компания уделяет энергоэффективности AmpereOne, которая заключается не только в экономии электроэнергии, но и драгоценного места в ЦОД. Проще говоря, компания упирает на повышение плотности размещения вычислительных мощностей. 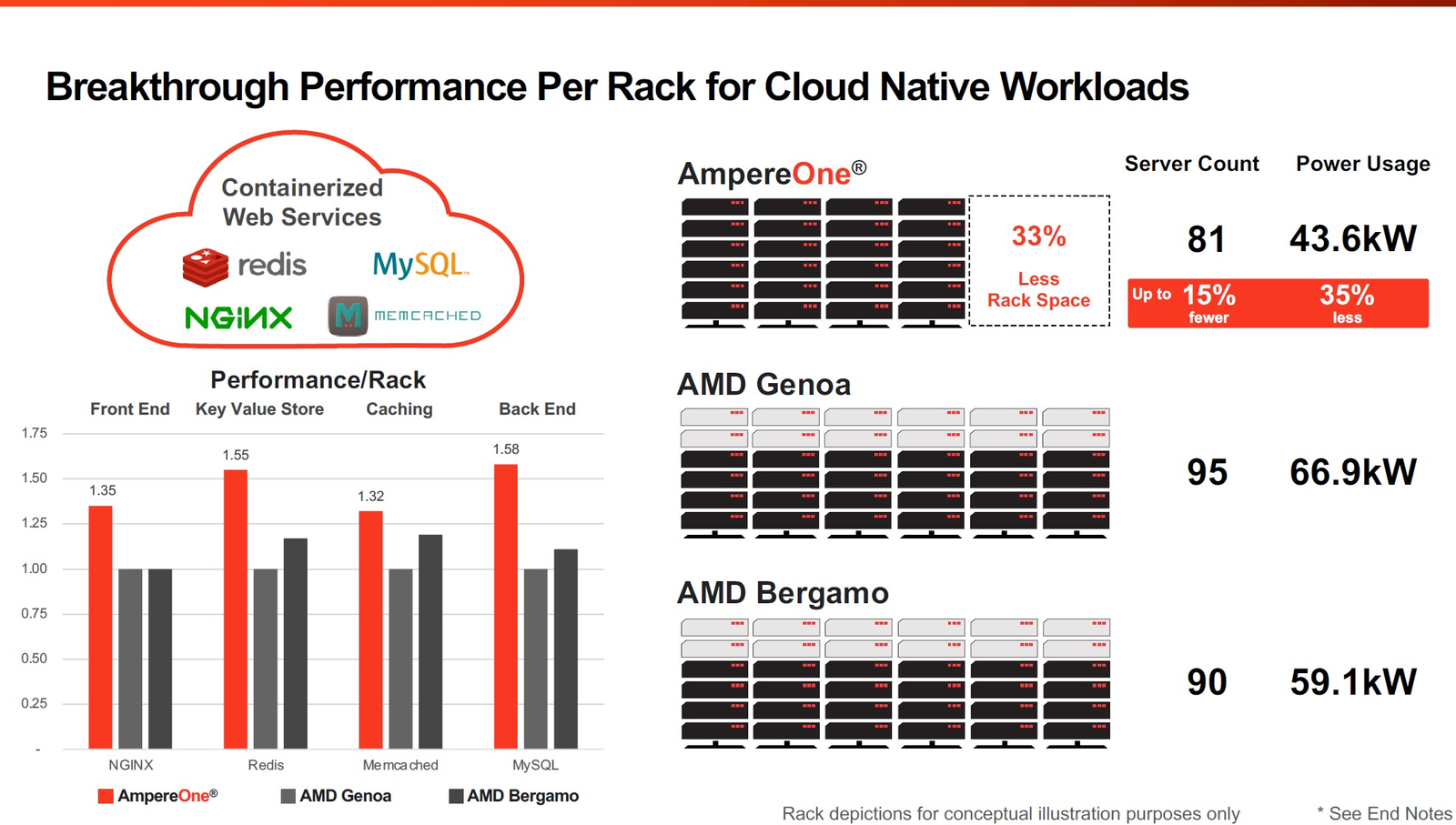 Заодно Ampere в который раз говорит, что в инференс-сценариях её процессоры сопоставимы с некоторыми ускорителями, в частности, NVIDIA A10, но при этом существенно дешевле и экономичнее. В пересчёте на токены при производительности порядка 80 токенов в секунду платформа Ampere обходится на 28% дешевле и в то же время потребляет меньше энергии на целых 67%! 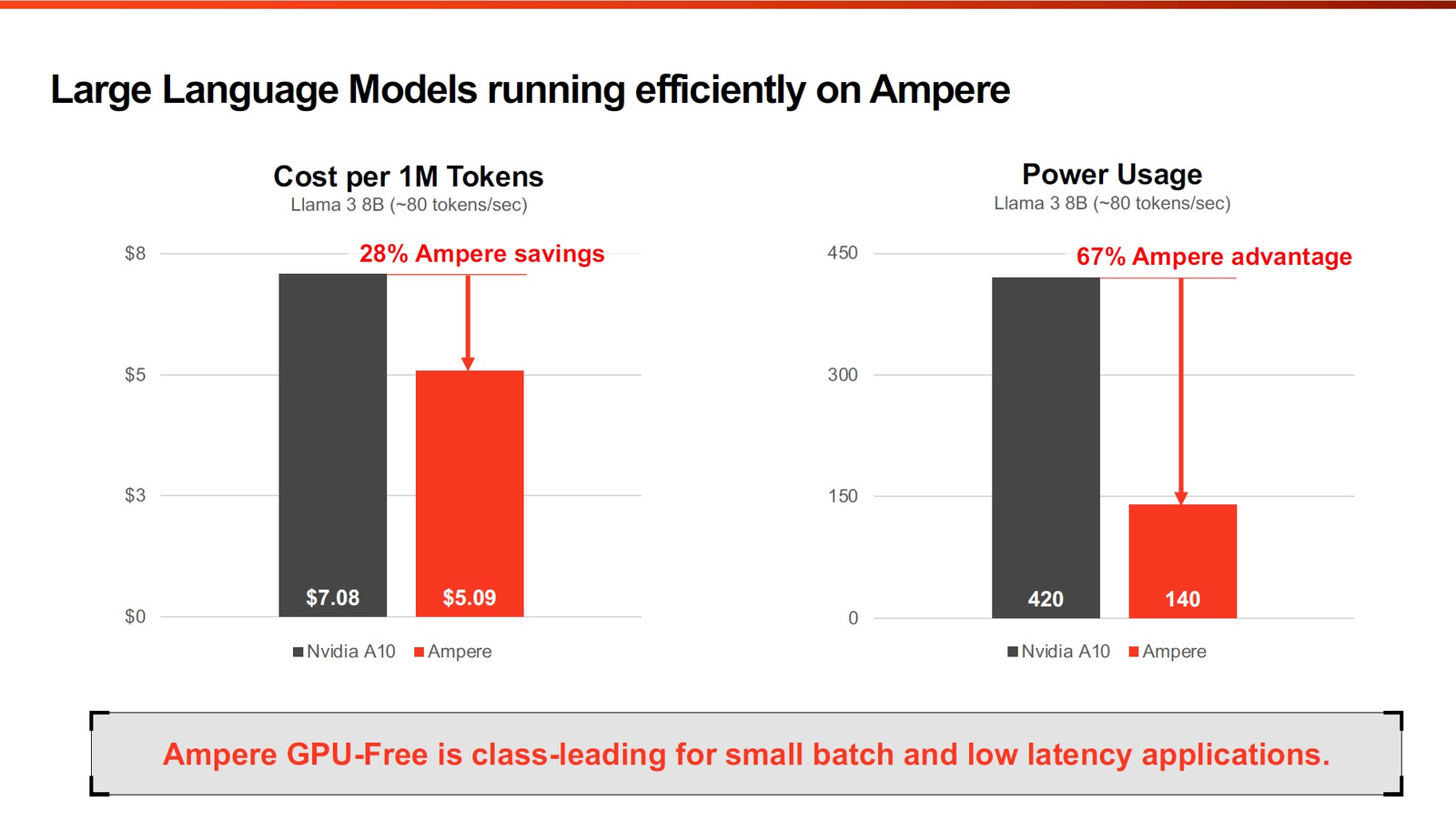 Более того, Ampere заключила союз с Qualcomm для выпуска серверной платформы, сочетающей AmpereOne в качестве процессоров общего назначения и ИИ-ускорителей Qualcomm Cloud AI 100 Ultra. Если сами процессоры успешно работают с LLM сравнительно небольшой сложности (до 7 млрд параметров), то новая платформа позволит запускать и сети с 70 млрд параметров. Кроме того, есть и готовое решение с VPU Quadra T1U.  Увидит ли свет в будущем гибридный процессор Ampere Computing с UCIe-чиплетами, будет зависеть от решений, принятых группой AI Platform Alliance, возглавленной Ampere Computing ещё осенью прошлого года. Но это вполне реальный сценарий: блоки ускорения специфических для ИИ-задач вычислений активно внедряются не только в серверных решениях, подобных Intel Xeon Sapphire/Emerald Rapids — сопроцессоры NPU уже дебютировали в потребительских и промышленных CPU Intel и AMD. При этом Ampere Computing, вероятно, придётся несколько поменять политику дальнейшего развития, поскольку основными конкурентами для неё являются не только 128-ядерные AMD EPYC Bergamo и готовящиеся 144- и 288-ядерные Intel Xeon Sierrra Forest, но и Arm-процессоры Google Axion и Microsoft Cobalt 100, которые изначально создавались гиперскейлерами под свои нужды, а потому наверняка лучше оптимизированы под их задачи и, вероятнее всего, к тому же дешевле, чем продукты Ampere.
17.05.2024 [21:48], Владимир Мироненко
Крупнейший в России оператор ЦОД и облачных услуг «РТК-ЦОД» готовится к IPO«Ростелеком» планирует провести IPO своей «дочке» в сфере облачных услуг и ЦОД — «РТК-ЦОД», пишет «Коммерсантъ». Сообщивший об этом на онлайн-конференции для инвесторов первый вице-президент и финансовый директор «Ростелекома» рассказал, что в настоящее время компания занимается выработкой параметров предстоящего IPO и определением конкретных сроков его проведения. Он отметил, что для «Ростелекома» это будет первый опыт выведения быстрорастущих направлений на рынок, добавив, что компания видит в этом потенциал дальнейшей работы для того, чтобы в «большей степени транслировать, раскрывать стоимость направлений» её бизнеса. Ранее «Ростелеком-ЦОД» попал под санкции США. 
Источник изображения: «Ростелеком» Операторы ЦОД в комментариях «Коммерсанту» отметили, что выход конкурента на биржу является для него логичным шагом в условиях растущего рынка и позволит привлечь инвестиции. После объявления о планах по проведению IPO «РТК-ЦОД» котировки «Ростелекома» по выросли на 6,1 % при росте индекса на 0,45 %. Объём торгов составил 3,8 млрд руб. — рекорд за два года. 
Источник: iKS-Consulting По оценкам iKS-Consulting, РТК-ЦОД контролирует 33 % российского рынка аренды стойко-мест и размещения оборудования и 24 % облачных услуг IaaS и PaaS, темпы роста которых составляют 25 % и 34 % соответственно. Также отмечается, что с учётом высокой ключевой ставки ЦБ заёмный капитал слишком дорог, поэтому «использование для развития внешних инвестиций, получаемых в ходе IPO, выглядит хорошим решением».
17.05.2024 [16:35], Руслан Авдеев
Быстрое развитие ИИ привело к резкому росту углеродных выбросов Microsoft, но сбавлять обороты корпорация не намеренаC 2020 года Microsoft увеличила выбросы углекислого газа приблизительно на 30 %, передаёт The Register. Из-за этого ранее заявленная цель достижения углеродно-отрицательного баланса компанией к 2030 году стала ещё более труднодостижимой, а виной тому, судя по всему, широкое внедрение ИИ-систем. Как сообщается в докладе 2024 Environmental Sustainability Report, который посвящён статистике 2023 фискального года, закончившегося 30 июня прошлого календарного, с 2020 года выбросы CO2 взлетели на 29,1 %. В основном из-за непрямых выбросов Scope 3, связанных со строительством и снабжением всё большего числа ЦОД. В указанный период Microsoft начала наращивать поддержку ИИ после взрывного роста интереса к теме с дебютом ChatGPT компании OpenAI. 
Источник изображения: Marcin Jozwiak/unsplash.com В докладе компания констатирует, что ИИ требует модернизации инфраструктуры — повышения эффективности ЦОД и систем передачи энергии для того, чтобы добиться углеродной нейтральности. По имеющимся данным, некоторые крупные поставщики товаров и услуг для Microsoft будут обязаны перейти на 100 % безуглеродную энергетику к 2030 году. Во всяком случае, эти требования будут входить в документ Supplier Code of Conduct с 2025 фискального года. Сама компания к текущему моменту заключила договоры на поставку 19,8 ГВт из «зелёных» источников. На Scope 3 приходится более 96 % всех выбросов Microsoft, включая те, что касаются работы цепочек поставок, а также выбросов, связанных с жизненным циклом устройств и прочими непрямыми источниками. «Собственные» выбросы (Scope 1 и 2) компании снизились на 6 % с 2020 года, благодаря закупкам чистой энергии, участии во всевозможных «зелёных» программах и покупке сертификатов на возобновляемую энергию. 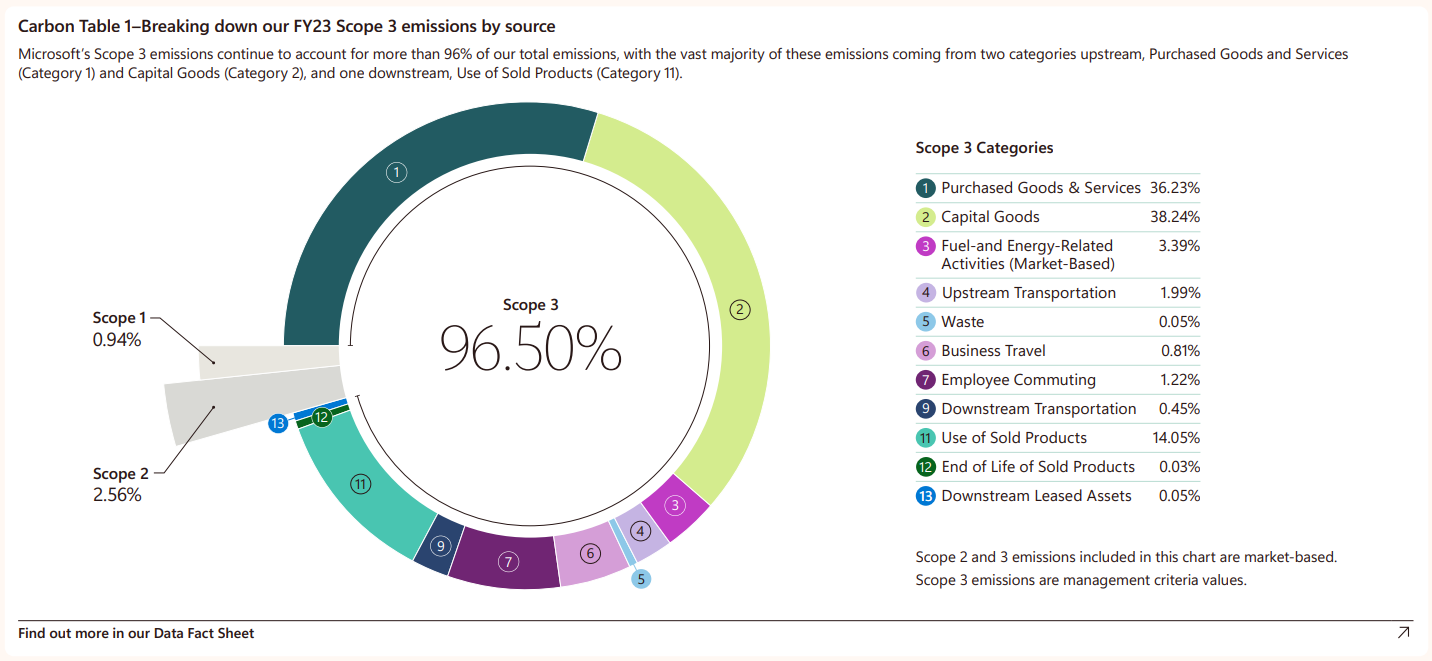
Источник изображения: Microsoft В Microsoft утверждают, что использование возможности перевода серверов в режим низкого энергопотребления уже обеспечило сокращение использования энергии приблизительно на 25 %. Соответствующие энергосберегающие технологии опробовали в 2022 году на нескольких тысячах серверов, а к концу 2023 года речь шла уже приблизительно о миллионе серверов. Ожидается, что 90 % серверов и иного облачного оборудования компании будут перерабатываться и использоваться повторно к 2025 году. Новые ЦОД Microsoft разработаны и оптимизированы для поддержки ИИ-вычислений и не будут потреблять воду для охлаждения вообще. Впрочем, в докладе признаётся, что за 2023 финансовый год потребление воды даже выросло, с 6,4 млн м3 годом ранее до 7,8 млн м3. При этом в 2022 фискальном году рост водопотребления тоже составил 34 % год к году. Microsoft уже увеличила инвестиции в программы защиты водных ресурсов, направив ещё $16 млн в 49 проектов их восполнения по всему миру. Речь потенциально идёт о возвращении 62 млн м3 чистой воды, но эффект от таких проектов часто становится хоть как-то заметен лишь спустя годы после старта. 
Источник изображения: Microsoft Президент компании Брэд Смит (Brad Smith) уже заявил, что вред природе, наносимый из-за ИИ, будет с избытком компенсироваться преимуществами использования подобных систем — замедлять внедрение ИИ не стоит в любом случае, только надо делать подобные системы более «зелёными». Microsoft намерена утроить скорость строительства дополнительных ЦОД в I половине фискального 2025 года.
17.05.2024 [13:20], Руслан Авдеев
AWS потратит €7,8 млрд на суверенное облако для ЕвропыAmazon Web Services (AWS) намерена потратить €7,8 млрд ($8,47 млрд) на создание в Европе, в частности, в Германии суверенной облачной инфраструктуры до 2040 года. По данным Datacenter Dynamics, первый суверенный облачный регион AWS разместится в земле Бранденбург, запуск планируется к концу 2025 года. По данным представителя подразделения Sovereign Cloud, инвестиции укрепят намерение предоставить клиентам наиболее передовые решения, отвечающие за обеспечение суверенитета облака. Кроме того, компания активно инвестирует в местные кадры и инфраструктуру. В компании рассчитывают, что проект ежегодно обеспечит в Германии занятость, эквивалентную 2800 рабочих мест — речь идёт о строителях, специалистах поддержки инфраструктуры, инженерах, телеком-специалистах и других экспертах. Понадобятся и высококлассные сотрудники, которые будут работать над управлением суверенным облаком на постоянной основе: программисты, системные разработчики и архитекторы облачных решений. 
Источник изображения: Roman Kraft/unsplash.com По словам представителя властей Бранденбурга, высокопроизводительная, надёжная и безопасная инфраструктура является важнейшим элементом цифровизацию экономики. В последние годы местные власти взяли курс на инвестиции в современную и устойчивую инфраструктуру ЦОД, это усиливает позиции Бранденбурга в роли бизнес-хаба. Впервые AWS заявила о намерении построить европейский суверенный облачный регион European Sovereign Cloud в октябре 2023 года. Также о планах построить в Бранденбурге кампус ёмкостью 300 МВт сообщала в сентябре того же года Virtus Data Centres. У Google облачный регион в Бранденбурге уже есть, а Oracle запустила облачный сервис EU Sovereign Cloudво Франкфурте (Германия) и Мадриде (Испания). Microsoft и Google располагают суверенными облачными регионами в Евросоюзе, но продвигают свои сервисы при посредничестве партнёров. В 2021 году Orange и Capgemini основали французскую облачную компанию Bleu для продажи сервисов Microsoft Azure, в январе 2024 года Bleu объявила, что работа начнётся в конце года. Google тем временем сотрудничает в Германии с T-Systems и с Thales во Франции, а также с Proximus в Бельгии и Люксембурге. По некоторым данным Google считает чрезвычайно важной свою программу доверенного облачного партнёрства и рассчитывает захватить в Евросоюзе и Азии рынок суверенных облаков объёмом в $100 млрд.
16.05.2024 [23:30], Алексей Степин
Шестое поколение ускорителей Google TPU v6 готово к обучению ИИ-моделей следующего поколенияGoogle успешно занимается разработкой ИИ-ускорителей порядка 10 лет. В прошлом году компания заявила, что четвёртое поколение TPU в связке с фирменными оптическими коммутаторами превосходит кластеры на базе NVIDIA A100 с интерконнектом InfiniBand, а к концу того же года было представлено уже пятое поколение, причём в двух вариантах: энергоэффективные TPU v5e для малых и средних ИИ-моделей и высокопроизводительные TPU v5p для больших моделей. Сбавлять темпа компания явно не собирается — не прошло и полугода, как было анонсировано последнее, шестое поколение TPU, получившее, наконец, собственное имя — Trillium. Клиентам Gooogle Cloud новинка станет доступна до конца этого года, в том числе в составе AI Hypercomputer. Сведений об архитектуре и особенностях Trillium пока не очень много, но согласно заявлениям разработчиков, он в 4,7 раза быстрее TPU v5e. 
Источник: The Verge Ранее аналитик Патрик Мурхед (Patrick Moorhead) опубликовал любопытное фото, на котором глава подразделения кастомных чипов Broadcom держит в руках некий XPU, разработанный для «крупной ИИ-компании». Не исключено, что сделан он именно для Google. На снимке видна чиплетная сборка из двух крупных кристаллов в окружении 12 стеков HBM-памяти. Любопытно и то, что TPU v6 нарекли точно так же, как и проект Arm шестилетней давности по созданию нового поколения ИИ-ускорителей. Пропускная способность 32 Гбайт набортной HBM-памяти составляет 1,6 Тбайт/с. Межчиповый интерконнект ICI имеет пропускную способность до 3,2 Тбит/с, хотя в TPU v5p скорости ICI уже 4,8 Тбит/с. По словам Google, новый чип получился на 67% энергоэффективнее TPU v5e. Складывается ощущение, что компания сознательно избегает сравнения с TPU v5p. Но это объяснимо, поскольку заявленный почти пятикратный прирост производительности в сравнении с TPU v5e даёт примерно 926 Тфлопс в режиме BF16 и 1847 Топс в INT8, что практически вдвое выше показателей TPU v5p. 
Кластер Google на базе TPU v5e. Источник: Google При этом компания не бравирует высокими цифрами в INT4/FP4, как это делает NVIDIA в случае с Blackwell. Согласно опубликованным данным, прирост производительности достигнут за счёт расширения блоков перемножения матриц (MXU) и прироста тактовой частоты. В новом TPU также использовано новое, третье поколение блоков SparseCore, предназначенных для ускорения работы с ИИ-модели, часто использующихся в системах ранжирования и рекомендаций. Масштабируется Trillium практически так же, как TPU v5e — в составе одного блока («пода») могут работать до 256 чипов. Эти «поды» формируют кластер с технологией Multislice, позволяющий задействовать в одной задаче до 4096 чипов. В таких кластерах на помощь приходят DPU Titanium, берущие на себя обслуживание IO-операций, сети, виртуализации, безопасности и доверенных вычислений. Размеры кластера могут достигать сотен «подов». 
Кластер Google на базе TPU v5p. Источник: Google Google полагает, что TPU v6 готовы к приходу ИИ-моделей нового поколения и имеет для этого все основания: ориентировочно каждый Trillium с его 32 Гбайт быстрой памяти может оперировать примерно 30 млрд параметров, а речь, напомним, в перспективе идёт о десятках тысяч таких чипов в одном кластере. В качестве интерконнекта в таких системах используется платформа Google Jupiter с оптической коммутацией, совокупная пропускная способность которой уже сейчас превышает 6 Пбайт/с.
16.05.2024 [15:54], Руслан Авдеев
150 кВт на стойку: Digital Realty внедрила поддержку СЖО в своих ЦОД по всему миру, чтобы поддержать ИИ-нагрузкиКомпания Didital Realty внедрила прямое жидкостное охлаждение чипов (DLC) на 170 своих колокейшн-объектах, размещённых по всему миру. Datacenter Dynamics сообщает, что речь идёт о комбинации решений вроде теплообменников задней двери (RDHx) и собственно DLC. В результате плотность размещения оборудования достигает 30–150 кВт на стойку, а в некоторых случаях ещё больше. По данным самой компании, совместное использование RDHx и DLC позволяет удвоить плотность стоек в сравнении с решениями прошлого поколения. В августе прошлого года компания предложила решения на основе AALC — гибридной системы Air-Assisted Liquid Cooling, как раз совмещающей RDHx и DLC. На тот момент сообщалось о пороге в 70 кВт на стойку на 28 региональных рынках Северной Америки, Европы. Ближнего Востока и Азиатско-Тихоокеанского региона. По данным компании, новое решение будет использовать уже существующую инфраструктуру, чтобы удовлетворить растущие потребности ИИ-систем и станет применяться в более половины подконтрольных ЦОД. Вместе с тем планируется и дальнейшее внедрение разработок на новых площадках. Известно, что в проекте участвует Lenovo Infrastructure Solutions Group (ISG), но роль компании не раскрывается. 
Источник изображения: Digital Realty Ранее жидкостное охлаждение Digital Realty уже опробовала в нескольких ЦОД, включая объекты во Франции и Сингапуре. Компания также является инвестором стартапа Colovore, управляющего в Калифорнии ЦОД с жидкостным охлаждением. Не дремлют и конкуренты. Так, оператор Equinix сообщил о готовности поддержать использование прямого жидкостного охлаждения более чем в 100 дата-центрах ещё в декабре прошлого года.
16.05.2024 [14:22], Руслан Авдеев
xAI Илона Маска потратит $10 млрд на облачные ИИ-серверы Oracle для чат-бота GrokИИ-стартап Илона Маска (Elon Musk) xAI готов потратить $10 млрд на серверы в облаке Oracle. По данным The Information, ссылающейся на осведомлённые источники, компании ведут переговоры о долгосрочном сотрудничестве, которое сделает детище Маска одним из крупнейших клиентов Oracle. Предполагается, что xAI требуется больше вычислительных ресурсов для соперничества с OpenAI, Anthropic и другими компаниями, уже заключившими многомиллиардные инвестиционные сделки с Microsoft и AWS соответственно. Это позволяет им получать доступ к облачной инфраструктуре для обучения и запуска больших языковых моделей (LLM). Например, Microsoft и OpenAI, по слухам, готовы потратить $100 млрд на кампус ЦОД Stargate ёмкостью 5 ГВт. Пока Micosoft вынуждена сама арендовать часть ИИ-ускорителей у Oracle. В прошлом году xAI представила чат-бот Grok, доступный платным пользователям соцсети X, а сейчас разрабатывается вторая версия. Имеются сведения, что xAI завершает раунд привлечения инвестиций в размере $6 млрд, а Маск уже заявил, что полученные средства будут потрачены на аренду инфраструктуры. В прошлом месяце миллиардер заявил, что новинка обучается на 20 тыс. ускорителей NVIDIA, но для Grok 3.0 потребуется уже 100 тыс. ускорителей. 
Источник изображения: Towfiqu barbhuiya/unsplash.com Маск и основатель Oracle Ларри Эллисон (Larry Ellison) крепко дружат, кроме того, Элиссон входил в совет директоров Tesla. В декабре прошлого года он заявлял, что xAI уже является крупнейшим клиентом Oracle и утверждал, что у облачного гиганта достаточно ускорителей для Grok первого поколения, но, по его признанию, в xAI хотят намного больше. Сейчас xAI арендует у Oracle 15 тыс. ускорителей NVIDIA H100. Tesla, ещё одно детище Маска, уже ввела в эксплуатацию ИИ-ресурсы, эквивалентные по производительности 35 тыс. H100. ИИ-инфраструктура стала выгодным источником дохода для облачного оператора, в марте Эллисон заявлял, что компания строит новые ЦОД, включая некий «крупнейший в мире» объект. Примечательно, что после покупки социальной сети Twitter (ныне X), Маск и его менеджмент не хотели платить за услуги Oracle (а также AWS и Google), пытаясь оптимизировать расходы.
16.05.2024 [01:05], Игорь Осколков
И для ИИ, и для HPC: первые европейские серверные Arm-процессоры SiPearl Rhea1 получат HBM-памятьКомпания SiPearl уточнила спецификации разрабатываемых ею серверных Arm-процессоров Rhea1, которые будут использоваться, в частности, в составе первого европейского экзафлопсного суперкомпьютера JUPITER, хотя основными чипами в этой системе будут всё же гибридные ускорители NVIDIA GH200. Заодно SiPearl снова сдвинула сроки выхода Rhea1 — изначально первые образцы планировалось представить ещё в 2022 году, а теперь компания говорит уже о 2025-м. При этом существенно дизайн процессоров не поменялся. Они получат 80 ядер Arm Neoverse V1 (Zeus), представленных ещё весной 2020 года. Каждому ядру полагается два SIMD-блока SVE-256, которые поддерживают, в частности, работу с BF16. Объём LLC составляет 160 Мбайт. В качестве внутренней шины используется Neoverse CMN-700. Для связи с внешним миром имеются 104 линии PCIe 5.0: шесть x16 + две x4. О поддержке многочиповых конфигураций прямо ничего не говорится. 
Источник изображения: SiPearl Очень похоже на то, что SiPearl от референсов Arm особо и не отдалялась, поскольку Rhea1 хоть и получит четыре стека памяти HBM, но это будет HBM2e от Samsung. При этом для DDR5 отведено всего четыре канала с поддержкой 2DPC, а сам процессор ожидаемо может быть поделён на четыре NUMA-домена. И в такой конфигурации к общей эффективности работы с памятью могут быть вопросы. Именно наличие HBM позволяет говорить SiPearl о возможности обслуживать и HPC-, и ИИ-нагрузки (инференс). 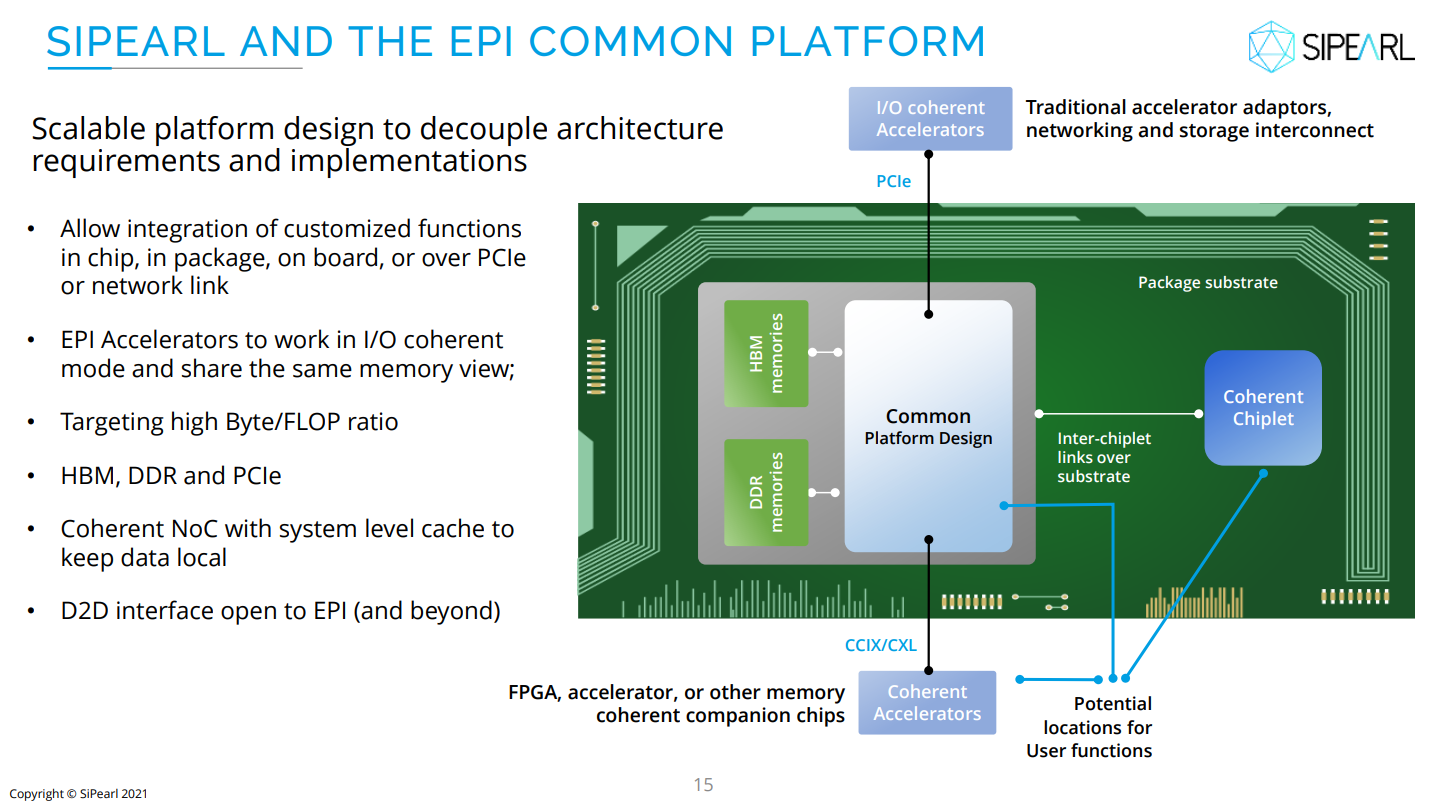
Источник изображения: SiPearl На примере Intel Xeon Max (Sapphire Rapids c 64 Гбайт HBM2e) видно, что наличие сверхбыстрой памяти на борту даёт прирост производительности в означенных задачах, хотя и не всегда. Однако это другая архитектура, другой набор инструкций (AMX), другая же подсистема памяти и вообще пока что единичный случай. С Fujitsu A64FX сравнения тоже не выйдет — это кастомный, дорогой и сложный процессор, который, впрочем, доказал эффективность и в HPC-, и даже в ИИ-нагрузках (с оговорками). В MONAKA, следующем поколении процессоров, Fujitsu вернётся к более традиционному дизайну. 
Источник изображения: EPI Пожалуй, единственный похожий на Rhea1 чип — это индийский 5-нм C-DAC AUM, который тоже базируется на Neoverse V1, но предлагает уже 96 ядер (48+48, два чиплета), восемь каналов DDR5 и до 96 Гбайт HBM3 в четырёх стеках, а также поддержку двухсокетных конфигураций. AWS Graviton3E, который тоже ориентирован на HPC/ИИ-нагрузки, вообще обходится 64 ядрами Zeus и восемью каналами DDR5. Наконец, NVIDIA Grace и Grace Hopper в процессорной части тоже как-то обходятся интегрированной LPDRR5x, да и ядра у них уже Neoverse V2 (Demeter), и своя шина для масштабирования имеется. 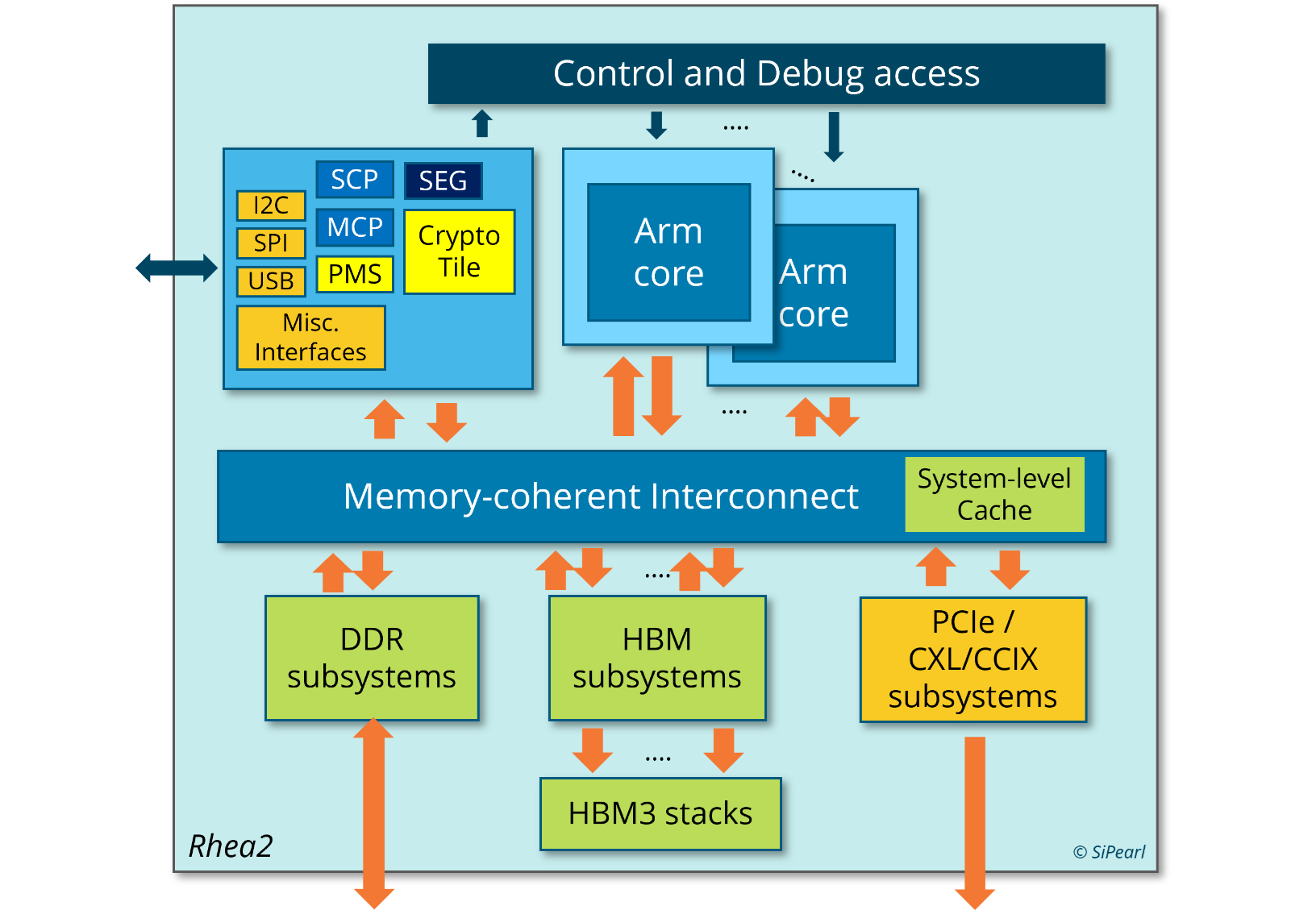
Источник изображения: EPI В любом случае в 2025 году Rhea1 будет выглядеть несколько устаревшим чипом. Но в этом же году SiPearl собирается представить более современные чипы Rhea2 и обещает, что их разработка будет не столь долгой как Rhea1. Компанию им должны составить европейские ускорители EPAC, тоже подзадержавшиеся. А пока Европа будет обходиться преимущественно американскими HPC-технологиями, от которых стремится рано или поздно избавиться. |
|

