Конференцию ISC 2015, которой в этом году исполнилось аж 30 лет, можно коротко охарактеризовать разными выражениями: «междусобойчик», «закрытая вечеринка для своих», или, более официозно, «специализированное мероприятие для узкопрофильных профессионалов». Это всё касается европейской версии ISC — американская и побольше, и пободрее. В целом формат мероприятия простой – себя показать и на других посмотреть. Правда, показывал всё больше условный Запад, а смотрел, нюхал, щупал и влезал с головой не менее условный Восток. С одной стороны, не присутствовать на такой важной и давно известной конференции нельзя, иначе какой же ты суперкомпьютерщик. С другой – чем не повод лишний раз встретиться со старыми знакомыми и пропустить по стаканчику.

Традиционная фотография общего вида выставки
Конечно, за кулисами происходило много всяких важных и полезных штук – доклады, мини-конференции, задушевные беседы в переговорках, обучающие курсы и тренинги и так далее. Но публичная часть всего этого действа выглядела несколько странной. Прессе здесь не то чтоб не рады, но на одних стендах были люди, которым запрещено общаться со СМИ, а у других в глазах читалось: «Меня не учили правильно отвечать на этот вопрос», что вербализировалось в «Давайте я уточню детали и отвечу вам на почту». На третьих вообще была лёгкая неразбериха – между собой-то все уже давно подписали всякие NDA и даже вовсю используют ещё не анонсированные официально продукты – так что с ходу и не понять, можно ли этому загадочному русскому что-то рассказывать.
На ISC только и разговоров, что о KNL
Одним из таких известно-неизвестных продуктов является новая версия процессора Intel Xeon Phi поколения Knights Landing (KNL). Всем, кому надо, Intel уже раздала образцы, да и на выставке тоже демонстрировала работу новинок – несколько систем, связанных воедино с помощью шины Intel Omni-Path, обсчитывали очередную физическую модель. Со стороны это выглядело так: стоит стойка, в стойку упакованы лезвия, сверху торчит Omni-коммутатор. Всё: сзади снимать нельзя, спереди смысла нет – поди отличи этот шкафчик от другого. Тем более что на других стендах тоже притаились материнские платы для KNL.

Платы для Intel Xeon Phi Knights Landing

Собственно говоря, о самом KNL слухи™ ходят давно – в новых CPU (а это скорее действительно процессоры, а не сопроцессоры) будет до 72 Atom’ных ядер на техпроцессе 14 нм, каждое из которых будет бинарно совместимо с обычными Intel Xeon (возможно, за исключением некоторых инструкций). Плюс каждому ядру достанется по два обработчика AVX-512. Обещано сразу несколько версий KNL в форм-факторе карты PCIe или в виде обычного «камня», устанавливаемого в приличного размера процессорный разъем (на фото) на отдельной плате с шестью DDR4-слотами. Ну и, собственно говоря, никто не мешает выделить, например, четыре ядра для работы ОС, а остальные впрячь в «числодробилку». Обещанная пиковая производительность достигает уровня 3 Тфлопс на модуль. Каждое ядро, предположительно работающее на частоте 1,1-1,3 ГГц, способно исполнять до четырёх потоков. Впрочем, есть ряд других изменений, касающихся работы кеша, буферов, очереди исполнения и предсказания ветвлений.


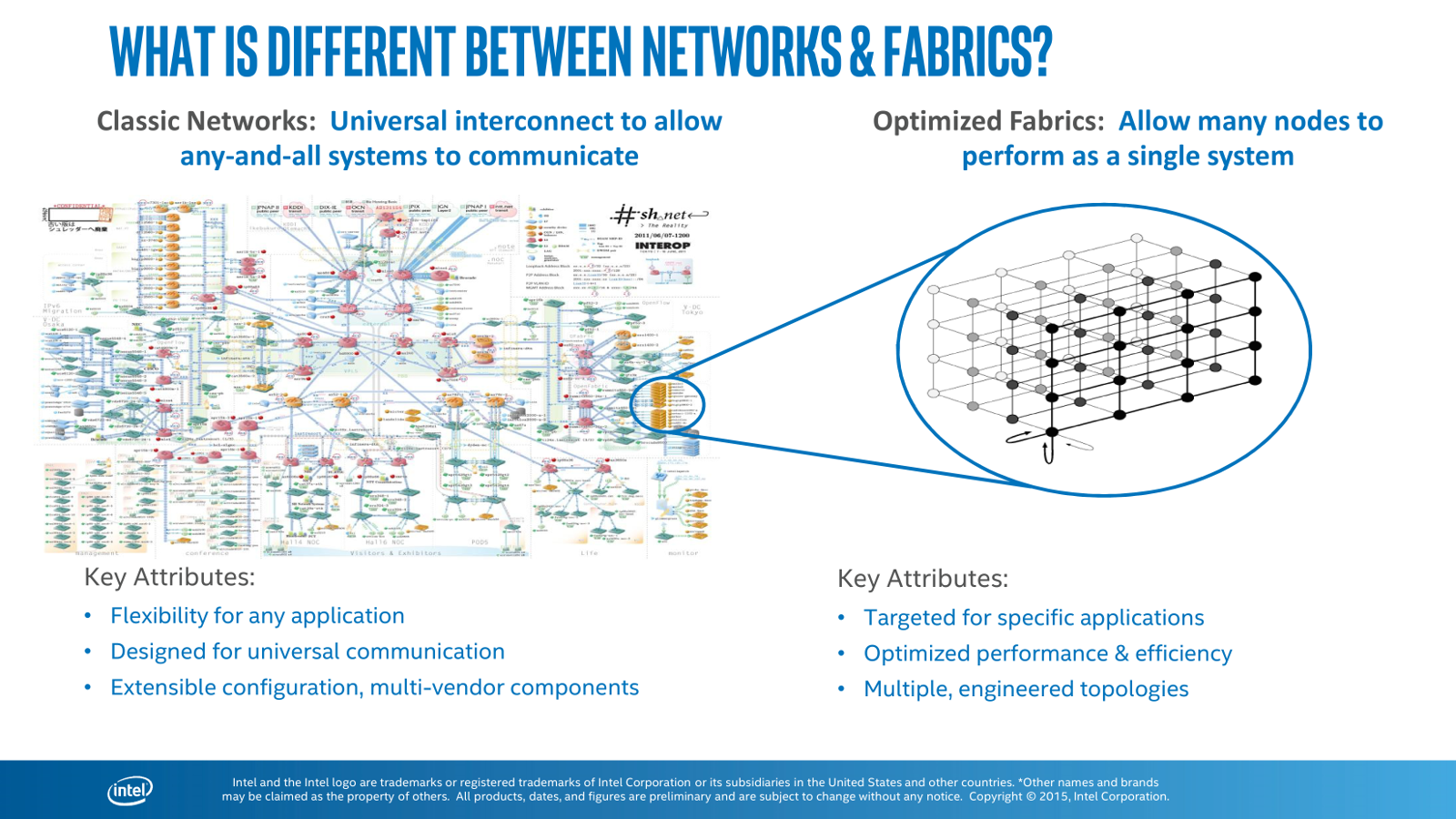
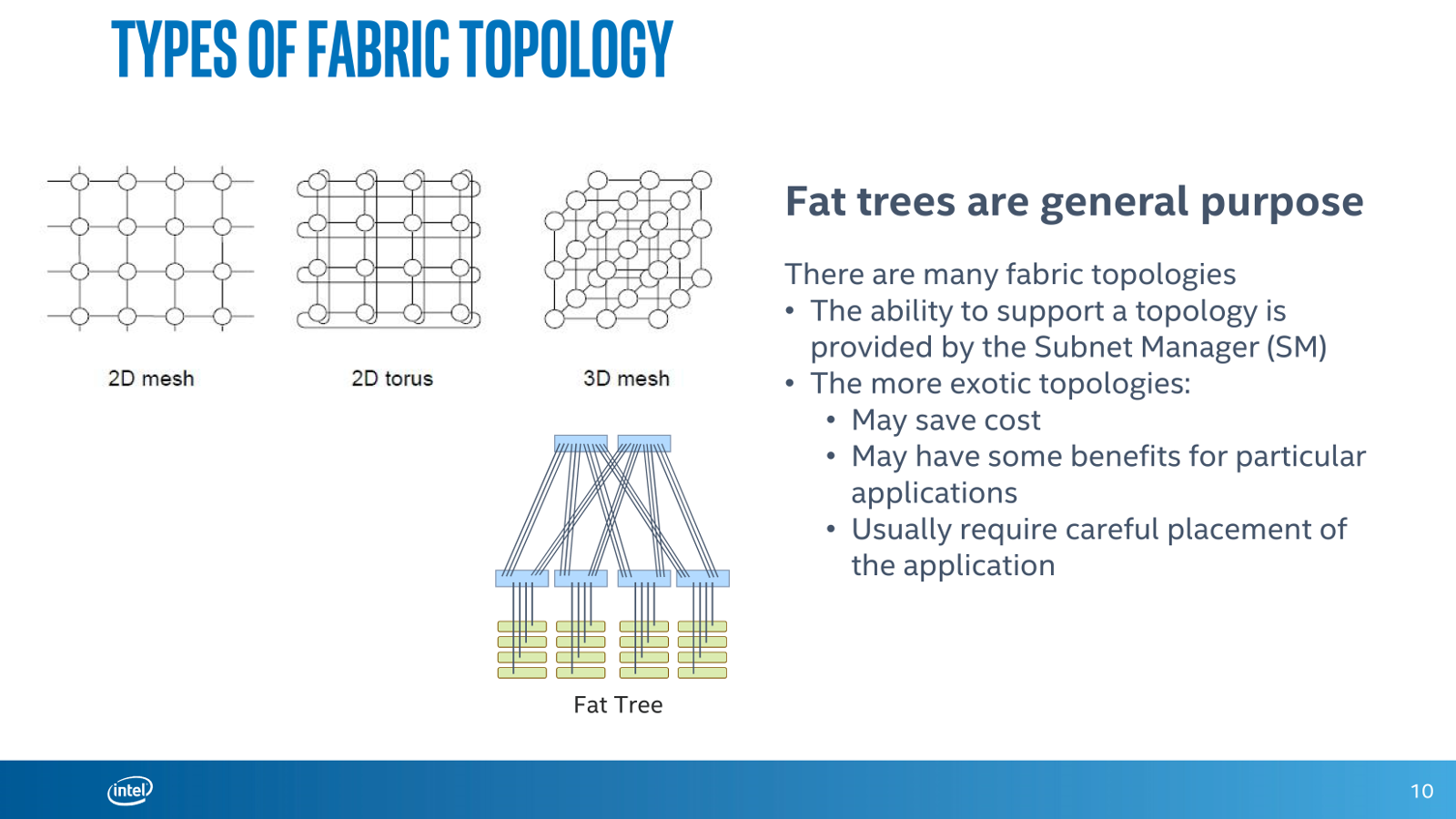
Вероятнее всего, будет выпущено сразу несколько модификаций KNL, которые будут различаться числом ядер, форм-фактором, наличием/отсутствием Omni-Path и другими параметрами. Точные технические характеристики нового чипа не известны, в том числе это касается и энергопотребления с TDP. Во всяком случае, заявленная ранее конфигурация 3 × KNL с «фабрикой» в 1U несколько, хм-м, смущает, да и на выставке основной упор одни производители делали на жидкостное охлаждение новинок, а вторые рвались в бой под девизом: «А давайте упихаем четыре PCIe-ускорителя (стандартные карты AMD, Intel или NVIDIA) в корпус 1U и посмотрим, как оно будет охлаждаться». Впрочем, СЖО – это общий тренд, о котором мы ещё поговорим отдельно. А пока обратимся к другой важной части новинки – шине Omni-Path, которая будет доступна и для обычных Intel Xeon. Важное отличие от других типов интерконнекта заключается в использовании топологии fat tree («утолщённое дерево»). Intel производит собственные чипы ASIC на два порта Omni-Path 100, которые будут доступны и другим производителям.


Обратите внимание на выемку в левой части разъема – она необходима для подключения двух портов Omni-Path Fabric 100 напрямую к CPU. Каждый порт Omni-Path 100 обеспечивает скорость 100 Гбит/с (4 линии по 25 Гбит/с), а для объединения узлов Intel подготовила коммутаторы на 24 и на 48 портов, а также большие версии на 192 и 768 портов плюс адаптер PCIe Gen3 ×16 для старых систем. Данная технология во многом похожа на InfiniBand EDR, но заявляется, что она почти вдвое быстрее обрабатывает сообщения и достигает скорости 195 млн сообщений в секунду, а также предлагает задержку на уровне 100-110 нс и проверку целостности пакетов, не требующую дополнительного времени для выявления ошибок. Сеть из множества узлов, многократно подключенных друг к другу, образует так называемую фабрику. За счёт такой топологии достигается одновременно и устойчивость сети, и уменьшение числа и длины кабелей.




изображения (5)
А вот про обещанную HMC-память никаких новых сведений не было, да и про только что анонсированную 3D XPoint тоже ни слуху ни духу. Однако в свете презентации, проведённой на ISC 2015, становится весьма любопытно – не её ли собираются продвигать на замену SSD, смещая всю иерархию памяти на шаг ближе к CPU (см. первый слайд ниже). Ну и да, на выставке то тут, то там слышался шёпот: «Вот сейчас-то ка-а-ак представят официально Knights Landing!» Увы, если судить по различным слайдам в презентациях Intel, то ждать прихода нового поколения Xeon Phi надо не просто во втором полугодии, а в четвёртом квартале нынешнего года. Хотя загадывать не будем. Вместо анонса Intel рассказала о своём видении будущего суперкомпьютинга – если коротко и совсем обобщённо, то Intel предлагает абстрагировать конкретные задачи и приложения, убрав их привязку к конкретному «железу» и ПО.
 |
 |
 |
Снизу будет работать единый программно-аппаратный комплекс, которые сможет гибко выделять ресурсы вышестоящим приложениям, а для разработчиков будут предоставлены простые интерфейсы доступа ко всем возможностям этого комплекса. Основной посыл – давайте, наконец, откажемся от местами весьма условного разделения на HPC и BigData (да и не только) в суперкомпьютинге и дружно перейдём в лоно Intel Scalable System Framework, который и позволит грамотно распоряжаться всеми ресурсами, обеспечивая при этом лёгкую масштабируемость и надёжность, а в конечном итоге — и экономию средств. Естественно, всё это будет доступно в рамках единой экосистемы Intel.
 |
 |
 |
||
|
Intel Scalable System Framework |
||||
Любопытно, что на слайдах чуть ли не впервые в дополнение к традиционным «железным» продуктам Intel появилась скромная приписка – FPGA. Правильно, зря, что ли, Altera купили? Тем не менее весьма интересно, каким именно образом и в каком виде они появятся в будущих продуктах. Будет ли это stand-alone-решение, или появится множество заточенных под конкретного заказчика или конкретные задачи вариантов Xeon. Строго говоря, про такую модель стало известно год назад, а в 2016 году появятся и другие варианты с обычным CPU и FPGA на одной подложке. Пока что для ряда действительно крупных заказчиков Intel выпускает специализированные версии Xeon (Phi). Например, для Facebook✴, оказывается, интересны целочисленные вычисления, так что можно слегка «придушить» FPU и повысить производительность других блоков, оставаясь в рамках заложенного TDP, что для интернет-гиганта крайне важно.

Сервер Facebook✴

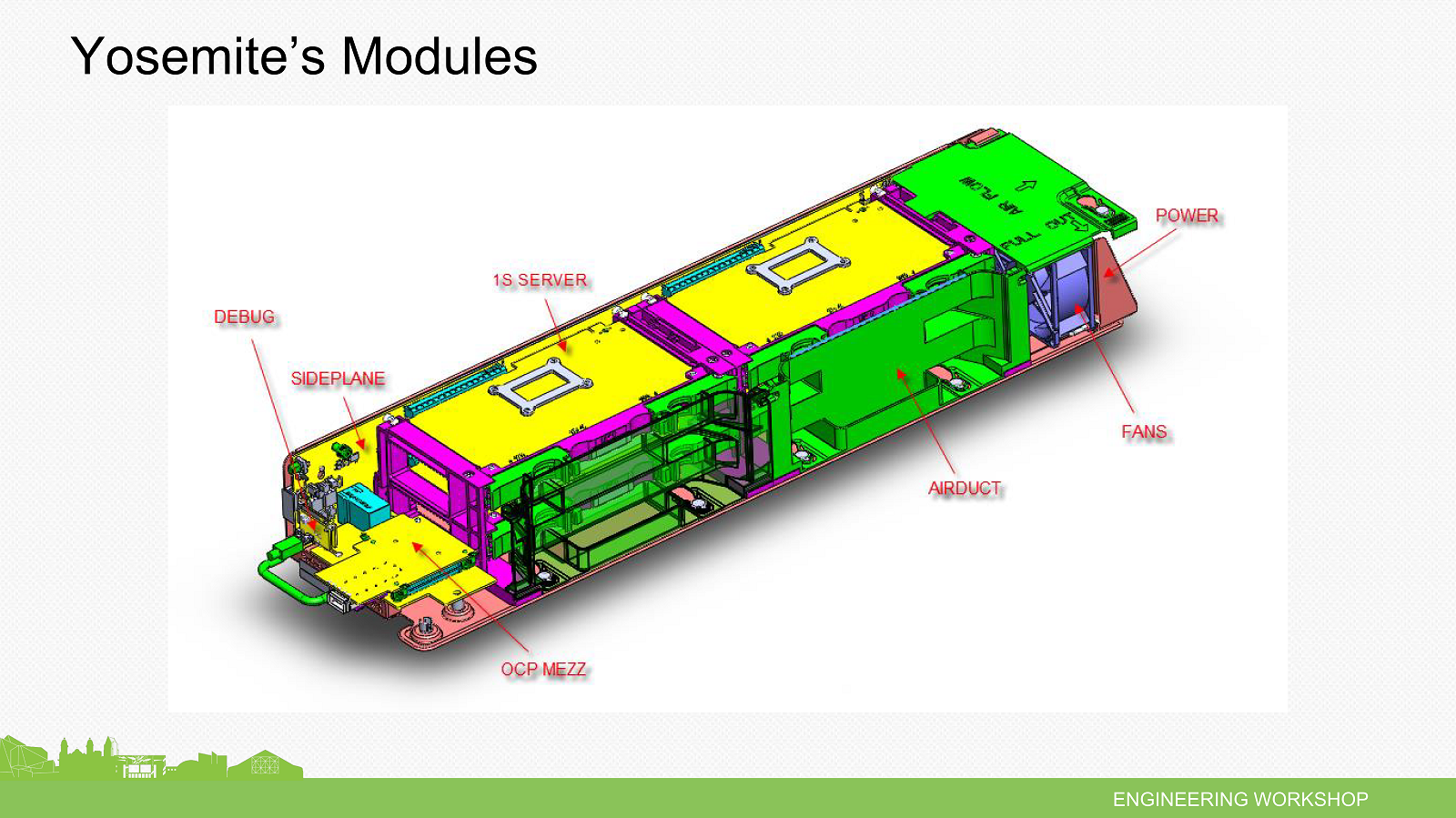
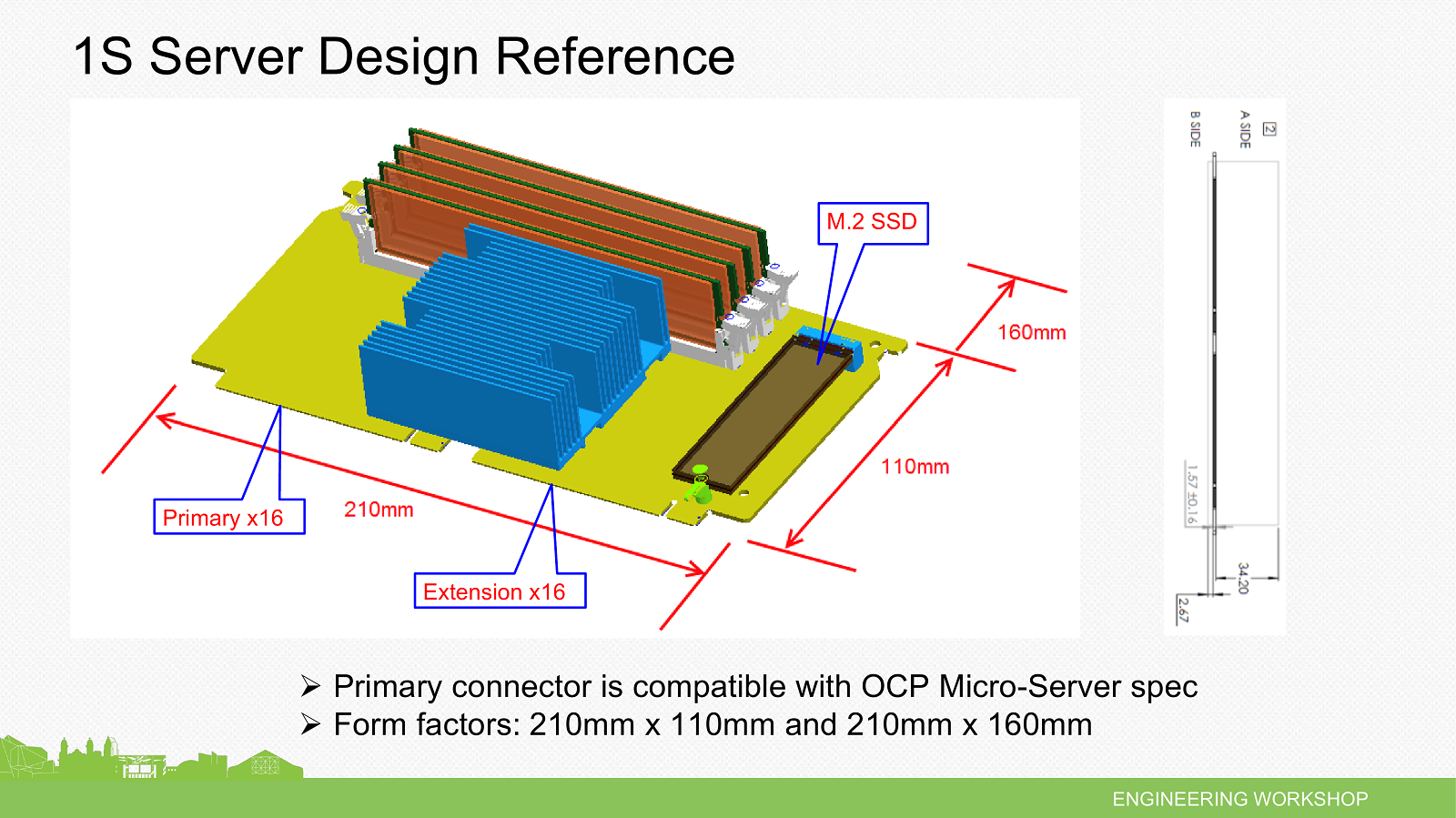
Раз уж заговорили про Facebook✴, то нельзя не упомянуть о том, что на ISC 2015 компания Mellanox привезла новые серверы этого гиганта (сама компания сделала для них сетевой адаптер). Представлены они были ещё весной этого года, на саммите Open Compute Project (OCP). Напомним, что OCP была создана самой Facebook✴ для разработки нового поколения серверных платформ специально для крупных ЦОД. На выставке же показали блоки Yosemite для четырёх односокетных узлов Mono Lake. Каждый узел оснащён процессором Intel Xeon D-1500, четырьмя слотами для двухканальной DDR4-RDIMM (до 128 Гбайт суммарно), коннекторами M.2 SSD (SATA или PCIe, для ОС и небольшого локального хранилища) и TPM. Остальные интерфейсы – 6 линий PCIe x4 Gen3, SATA3, сеть 10GbE – выводятся через коннекторы на общую плату блока Yosemite, которая обеспечивает связь с внешним миром и управляет узлами. В спецификации заложены и другие варианты связи узлов с основной платой, включая интерфейсы USB, UART, NC-SI, 40Gbe, I2C.
 |
 |
 |
Не Intel единой жив HPC
По-видимому, достойную альтернативу связке Intel Xeon + Xeon Phi KNL + Omni-Path + FPGA Altera ± GPU сможет предложить только платформа OpenPOWER. Чипы с ядрами POWER и любой доступной обвязкой по лицензии можно производить где угодно. В качестве высокоскоростной шины прямого обмена данными между CPU и другими элементами предлагается CAPI. Массивно-параллельные вычисления можно делать на ускорителях NVIDIA, которые, кстати, с приходом Pascal обзаведутся и HBM, и NVLink (тот же CAPI, в общем-то). Связь с внешним миром будет осуществляться посредством InfiniBand EDR от Mellanox, а все прочие компоненты будут предоставлены другими участниками консорциума, которых уже больше сотни, включая, кстати говоря, ту же Altera. Программной платформой будет, как обычно, Linux.


Но… это всё по большей части планы на ближайшее будущее. Даже первые саммиты – что характерно, в США и Китае – консорциум провёл спустя полтора года после основания. Пока что на стенде IBM были лишь полупустой корпус с четырьмя ускорителями NVIDIA и несерверным блоком питания – что они этим хотели сказать, не очень понятно. Также была и укомплектованная машина с водружённой на неё «зелёной» картой Tesla K80, обладающей весьма, м-м-м… специфическим коннектором. Любопытно, что самой NVIDIA на выставке не было, хотя она незримо «присутствовала» на многих стендах в виде всё тех же карт и партнёрских логотипов. AMD на ISC 2015 привезла лишь один ускоритель FirePro и ARM-плату.

Платформа OpenPOWER

С прочими альтернативными платформами пока не так уж густо. Да, по традиции Fujitsu приехала со своими SPARC-решениями, но они, откровенно говоря, нужны именно просто как альтернатива x86, на всякий пожарный. Разве что Cavium порадовала, привезя на выставку свои 48-ядерные 64-битные ARMv8-чипы ThunderX с частотой 2,5 ГГц. Всего есть четыре линейки процессоров ThunderX, оптимизированных под различные задачи. Новые платформы обладают не только внушительной вычислительной мощностью, но и поддержкой других необходимых технологий: работы с DDR3/4 ёмкостью до 1 Тбайт и когерентного кеша (в двухпроцессорной конфигурации), виртуализации, специализированных ускорителей, разъёмов PCIe и SATA3, сети 10/40GbE, Ethernet-«фабрики» (см. выше) и так далее. Пока что Cavium активно занимается продвижением своих ARM-решений на серверный рынок, заключая партнёрство с крупными игроками и подталкивая разработчиков к переносу ПО.

Cavium ThunderX 1K

На самой выставке было объявлено о заключении соглашений с провайдерами облачного хостинга и разработчиками «железа» для суперкомпьютеров и ЦОД. Также на ISC 2015 были показаны примеры решений Gigabyte с CPU ThunderX – 384-ядерный сервер высотой 2U. Да и сама компания представила публике два варианта своих референсных платформ ThunderX 1K и 2K высотой 1U и 2U соответственно. Обе снабжены двумя портами 10GbE SFP+, одним портом 40GbE QSFP+, двумя слотами PCIe х8 Gen3, восемью слотами памяти для каждого CPU, а также BMC-контроллером. Различие в том, что младшая, односокетная модель поддерживает DDR3-память и четыре накопителя 2,5”/3,5”, а старшая, двухсокетная, умеет работать с DDR4 и шестью 2,5” SSD/HDD (или 3 × 3,5”). По умолчанию обе поставляются с предустановленной ОС Ubuntu 14.04, но предлагаются и сборки других дистрибутивов, а также драйверы.

Cavium ThunderX 2K

Gigabyte H270-T70 с двумя Cavium ThunderX
Если же говорить о более специализированных вычислителях и ускорителях, то вот вам хороший пример – чипы Micron Automata Processor, которые были анонсированы пару лет назад и которые представляют собой массив машин состояний, способных на лету выискивать в потоке неструктурированных данных заданные последовательности. Этакая, если хотите, аппаратная реализация регулярных выражений. Пожалуй, самые наглядные примеры – это сравнение нескольких ДНК с целью выявления различий между ними и поиск в сетевом трафикенужных последовательностей, характерных для попыток эксплуатации уязвимостей. При этом Automata может параллельно работать в связке с другими такими же чипами и перепрограммироваться чуть ли не на лету. Разработчики постарались максимально упростить процесс создания программ для этих процессоров и предлагают визуальный редактор для создания автоматов и правил.


Естественно – ну куда же без этого – Micron и Samsung рассказывали о прелестях HBM-памяти, каждая о своей реализации. Правда, Micron устроила живую демонстрацию преимуществ HMC на примере FPGA-плат поглощённой полгода назад Pico Computing, а Samsung ограничилась стендом с показательной схемой строения такой памяти. А ещё Micron в очередной раз привезла на выставку свою гибридную NVDIMM-память – тот же DIMM, но с SSD и батареей суперконденсаторов, запаса энергии которых хватит для сброса дампа памяти на SDD в случае сбоя питания. Видимо, не зря Micron уже года три как рассказывает о преимуществах такого вида памяти – в мае JEDEC приняла решение её стандартизировать. Также во время ISC 2015 Micron анонсировала новые TCG-накопители SSD серии M510DC для корпоративного сектора и с шифрованием данных.

TSV-модель памяти Samsung

NVDIMM-модуль Micron
Здесь мы уже кратко коснулись темы систем жидкостного охлаждения (СЖО), которое становится всё популярнее. Да не просто СЖО, а таких, которые способны работать с горячей водой, то есть при температуре +45 °C, — это уже почти что стандарт для всех новых разработок. Подобные системы представили чуть ли не все крупные вендоры – одни предлагают комплекты для установки на имеющееся железо, другие ставят их в свои системы изначально, а третьи клепают собственные серверы с собственными же «проприетарными» СЖО. Но попадаются и необычные решения. Вот, к примеру, Calyos предлагает системы охлаждения с контурными тепловыми трубками (loop heat pipe) или испарительными камерами (loop vapor chamber) с капиллярным насосом. Очевидные плюсы – бесшумность, отсутствие механических частей (помпы) и различные варианты отвода тепла во втором контуре.

СЖО Calyos

Правда, есть и пара тонких моментов – в качестве теплоносителя используется далеко не безвредный и к тому же горючий метанол, что вызывает определённые вопросы относительно и обслуживания такой СО, и её работы в экстремальных ситуациях, и даже транспортировки. Другое модное направление разработок СО – иммерсионное охлаждение, когда вся система полностью погружается в жидкий теплоноситель-диэлектрик, в качестве которого обычно используют минеральные масла, парафины или другие, более хитрые жидкости. Идея, конечно, не нова, но вот создать идеальный теплоноситель с подходящими параметрами теплоёмкости, теплопроводности, вязкости, агрессивности – нетоксичности, в конце концов! – не очень-то и просто. Впрочем, есть масса других нюансов. Например, не все оптические кабели способны работать в такой среде, а за счёт капиллярного эффекта теплоноситель всё равно будет убегать по кабелям из ванны. И это уж не говоря о не самой приятной процедуре обслуживания таких серверов и необходимости создания компонентов именно для подобных сред.


Герметичный «гелиевый» накопитель HGST отлично подходит для иммерсионных СЖО
Да и плотность размещения вычислительных узлов пока не слишком высока. Самые «вкусные», конечно, открытые системы с испарением хладагента – фазовый переход всё ж таки! Но и с ними беда – хладагент будет испаряться не только когда надо, но и когда не надо тоже, то есть улетучиваться, пусть и не так активно, как при кипении. Значит, придётся думать то ли о герметизации, то ли о регулярном доливе. Да, в ряде специфических инсталляций иммерсионные системы охлаждения действительно могут быть наиболее разумным решением, но до массового внедрения их в дата-центры ещё очень и очень далеко. Всё-таки «воздух» и «водянка» намного привычнее и практичнее.

Иммерсионная СЖО CarnotJet от Green Revolution Cooling
 |
 |
|
|
Иммерсионная испарительная СЖО на стенде exToll |
||
Заключение
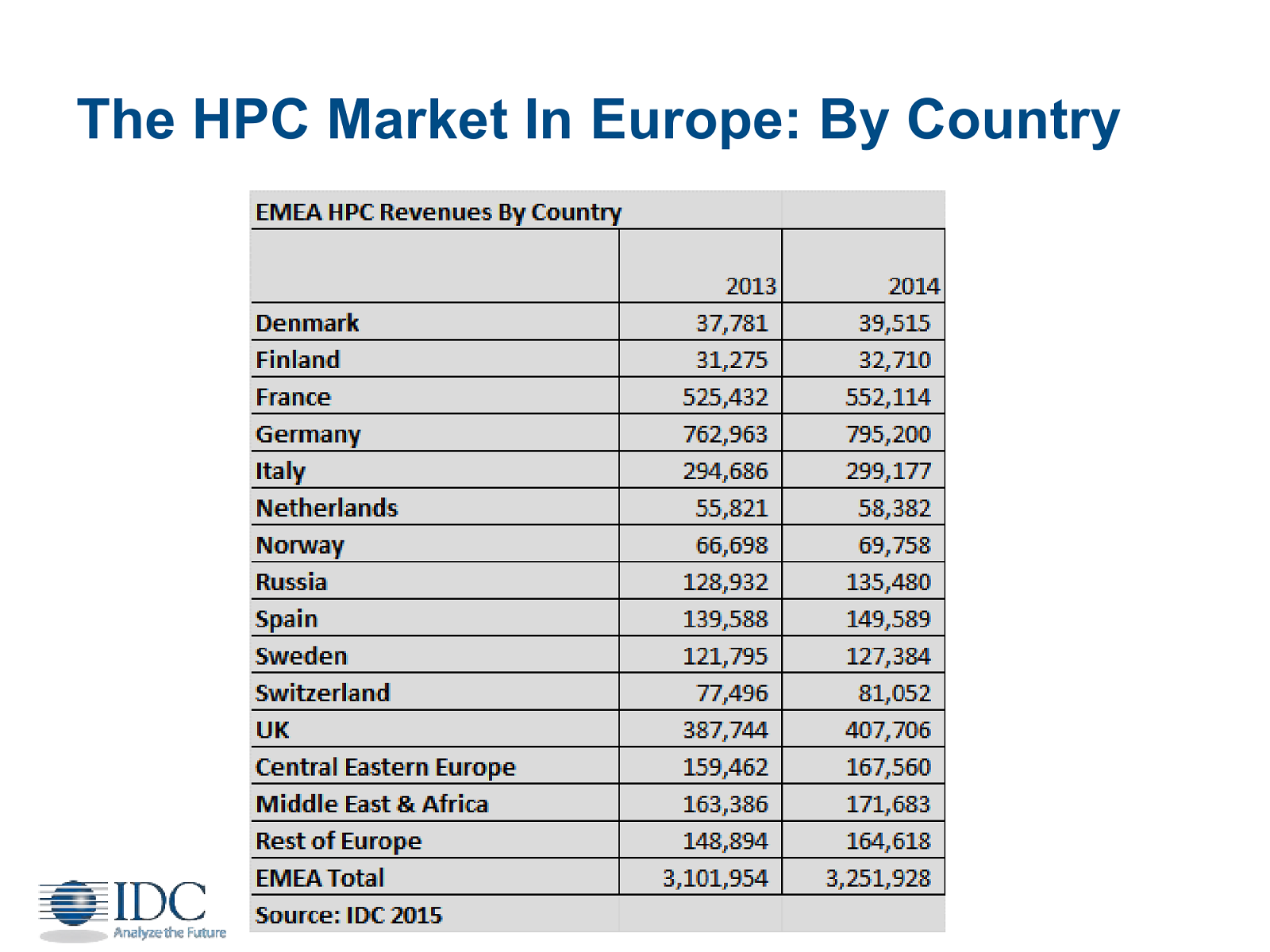
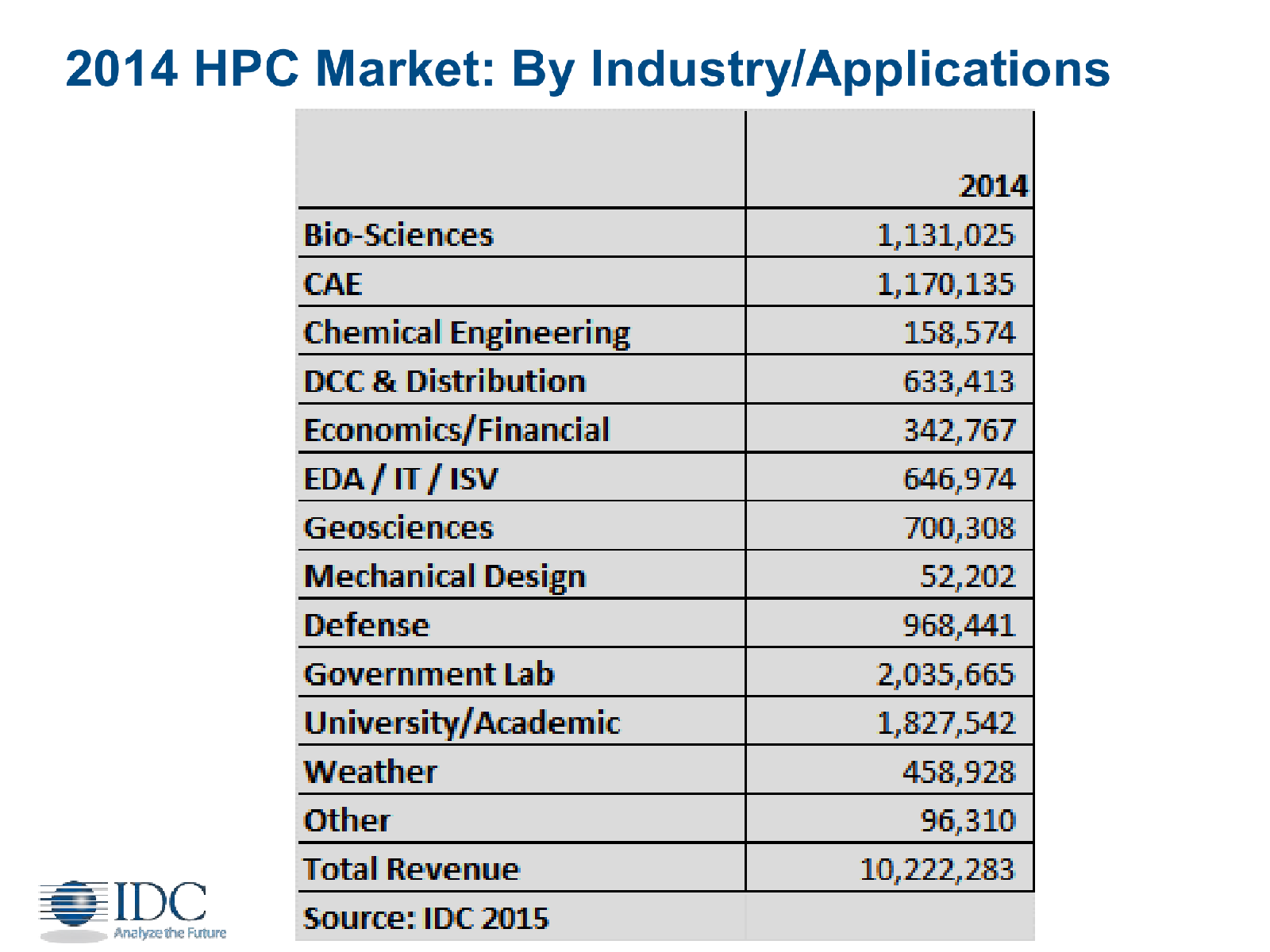
На этом, пожалуй, всё – остальные «железные» новости с выставки можно найти по соответствующему тегу. В заключении же стоит привести некоторые выдержки из ежегодного доклада IDC. Год 2014-й закончился для HPC не лучшим образом – по деньгам вышло чуточку меньше, чем в 2013-м, и это после нескольких лет бурного роста, который, по мнению IDC, восстановится в 2015-2018 годах. Рост будет в том числе за счёт слияния HPC, BigData и облаков в единую систему – как раз то, о чём рассказывала Intel (см. выше). При этом картина поменяется довольно заметно. Та же сделка IBM с Lenovo ощутимо повлияла на весь рынок, а тут ещё и китайские компании, варившиеся доселе исключительно на внутреннем рынке, стали заглядываться на Запад. Впрочем, глобальная суперкомпьютерная битва будет идти между США и Китаем. Любопытно, что для правительств обладание суперкомпьютерами и связанными технологиями становится ещё одним соревновательным фактором, хотя и для экономики в целом они тоже крайне полезны. А вот тормозить развитие будут всё ещё недостаточно хорошие системы управления и хранения данных, а также проблема разработки и переноса ПО на новые платформы. Собственно говоря, связано с это с тем, что в HPC наблюдается переход к гетерогенным системам, в которых, помимо традиционных x86-чипов, всё чаще станут появляться и другие процессорные архитектуры — и уже привычные GPU/MIC, и совсем уж специализированные ускорители и FPGA (опять вспоминаем Intel + Altera). И весь этот зоопарк надо использовать с максимальной эффективностью, чего, к сожалению, не всегда удаётся добиться.






Чего не было в отчёте IDC, так это наблюдения за тем, как консолидируется рынок микроэлектроники, без которой никакого HPC и не было бы. Смотрите сами: NXP купила Freescale за $12 млрд; Intel получила Altera за $14 млрд. Компания Avago приобрела Emulex Corporation за $606 млн, PLX Technology за $309 млн и LSI (часть которой отошла опять же Intel) за $6,6 млрд и теперь совершает фантастическую сделку по приобретению Broadcom ($37 млрд, Карл!). Китайских AllWinner и Rockchip вроде как собираются слить воедино, а ON Semiconductor успела купить Aptina Imaging за $400 млн и Truesense Imaging за $95 млн, ну а сейчас «переваривает» только-только полученную AXSEM. Cypress приобрела за $1,6 млрд Spansion, а Infineon поглотила International Rectifier за $3 млрд. За ISSI предлагают $730 млн. Попутно ходили слухи о слиянии NVIDIA и MediaTek, о покупке Lenovo компании Marvell, об интересном предложении Micron от Tsinghua, а про продажу AMD упоминали аж два раза. На этом фоне Qualcomm подумывает прикупить то ли NVIDIA, то ли NXP, да и Texas Instruments тоже не прочь «пошопиться». Да и та же Avago, кажется, ищет новую «жертву». Заметьте, мы прошлись только по более-менее крупным сделкам и лишь по некоторым крупнейшим производителям микроэлектроники. Интересно, появится ли в череде этих слияний и поглощений новый сильный игрок, который сможет полноценно противостоять известно кому и известно какой архитектуре?

