На конференции HotChips 34 компания Intel поделилась некоторыми подробностями о своих топовых ускорителях Ponte Vecchio, уточнив, в частности, производительность и некоторые характеристики новых чипов. Как и было сказано год назад, Ponte Vecchio включают два стека, которые в сумме дают 128 Xe-ядер, 128 RT-блоков, 8 контроллеров памяти HBM2e, два блока L2-кеша, два медиа-движка и 16 интерфейсов Xe Link. Всё это упаковано в OAM-модуль с TDP на уровне 600 Вт.
Ускоритель состоит из 47 различных тайлов (чиплетов), изготовленных с использованием техпроцессов Intel 7/TSMC N7/TSMC N5 и объединённых между собой посредством Foveros и EMIB. Общий транзисторный бюджет — более 100 млрд. Базовая (Base) «подложка», которая несёт на себе часть тайлов, будет иметь площадь 650 мм2, максимальная площадь тайла наверху этого слоёного пирога не превысит 41 мм2, а общая площадь упаковки составит 4843,75 мм2 (77,5 × 62,5 мм). Intel будет предлагать как отдельные OAM-модули, так и сборки из четырёх ускорителей.

Изображения: Intel (via WCCFtech)

Ускоритель отличается развитой иерархией памяти. На самом нижем уровне лежат регистровые файлы суммарным объёмом 64 Мбайт, обеспечивающие пропускную способность (ПСП) до 419 Тбайт/с. L1-кеш имеет тот же объём, но скорость поменьше — 105 Тбайт/с. L2-кеш намеренно увеличен до 408 Мбайт, а его ПСП составляет 13 Тбайт/с. Наконец, на вершине находятся 128 Гбайт HBM2e с ПСП на уровне 3,2 Тбайт/с. Но надо учитывать, что данные даны для двух стеков, связанных мостиками. Xe Link же позволяет объединить четыре или восемь ускорителей по схеме каждый-с-каждым.
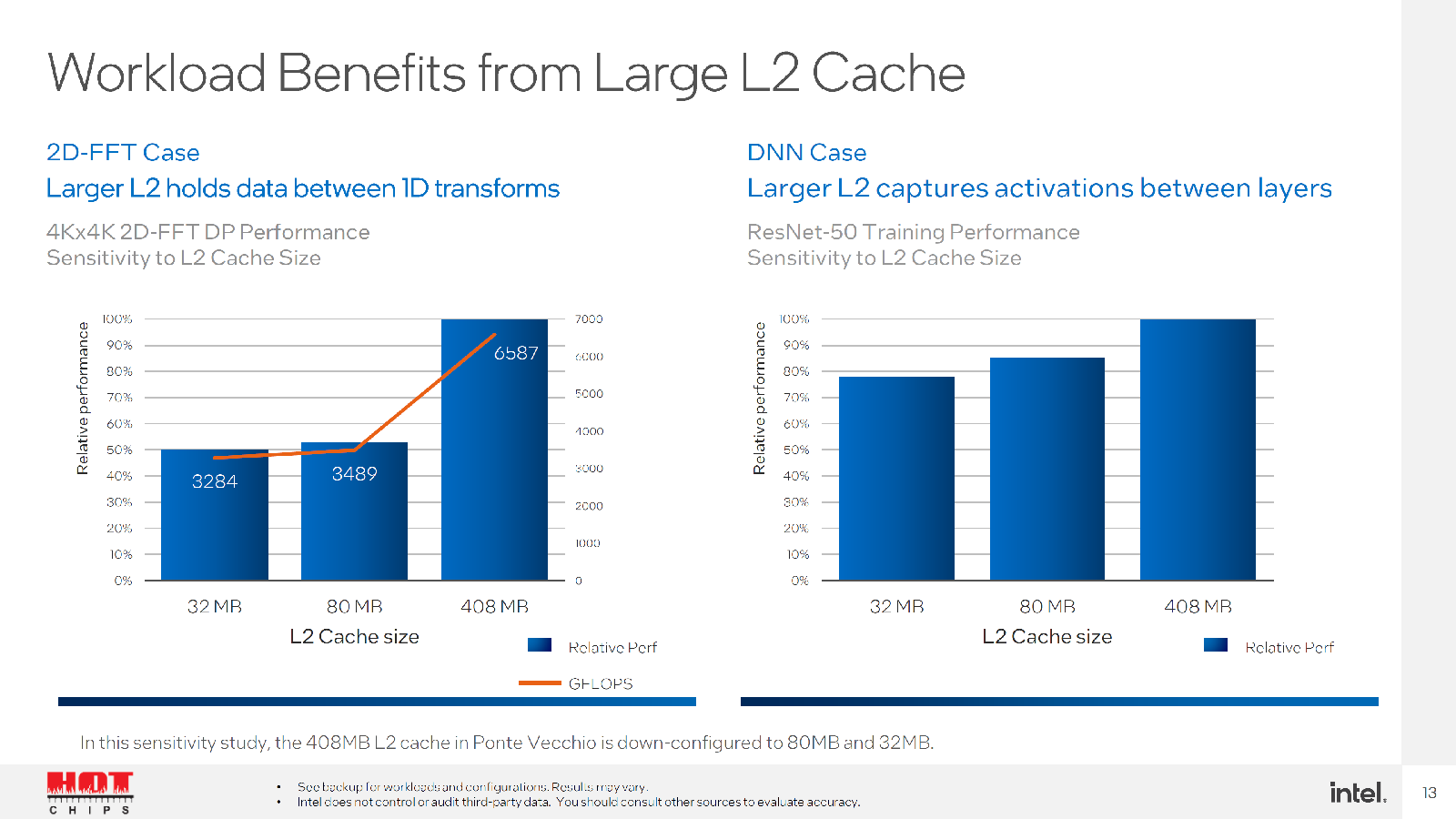
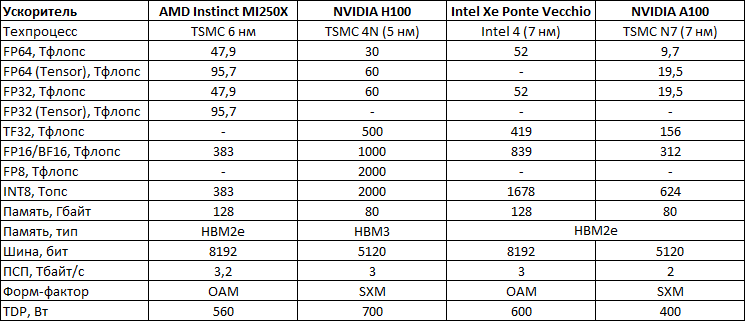
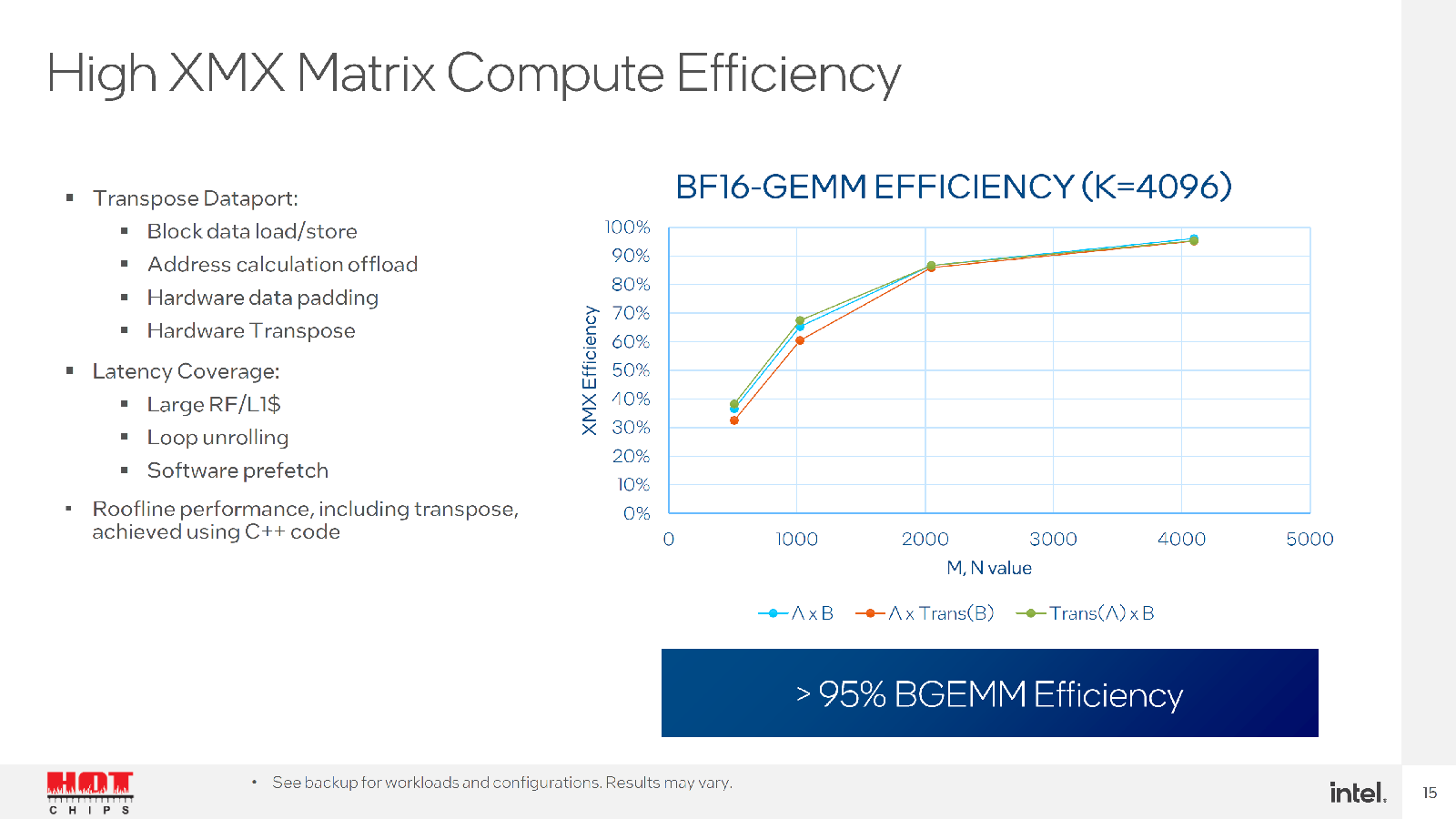
Увеличенный объём L2-кеша, по словам Intel, оказывает значительное влияние на производительность в некоторых задачах. Заявленная производительность составляет 52 Тфлопс для FP64/FP32-вычислений, 419 Тфлопс для TF32, 839 Тфлопс для BF16/FP16 и, наконец, 1678 Топс для INT8. Все вычисления пониженной точности даны для матричных блоков XMX. По «голым» характеристикам Ponte Vecchio действительно намного быстрее NVIDIA A100, а по некоторым пунктам — и AMD Instinct MI250X. Оптимизированное ПО, использующее oneAPI, до двух раз быстрее исполняется на ускорителях Intel по сравнению с A100, но результат, конечно, зависит от задачи.
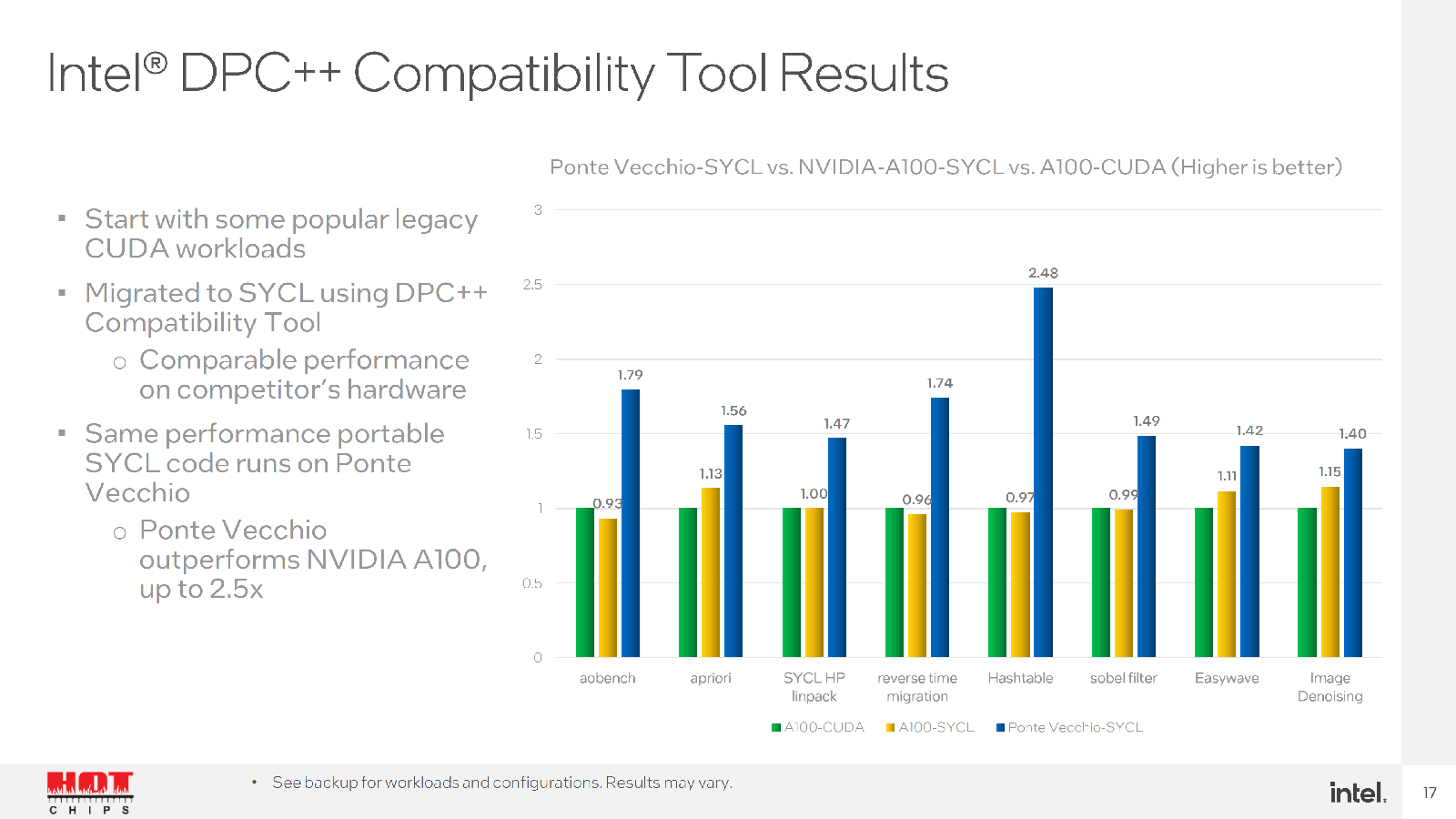
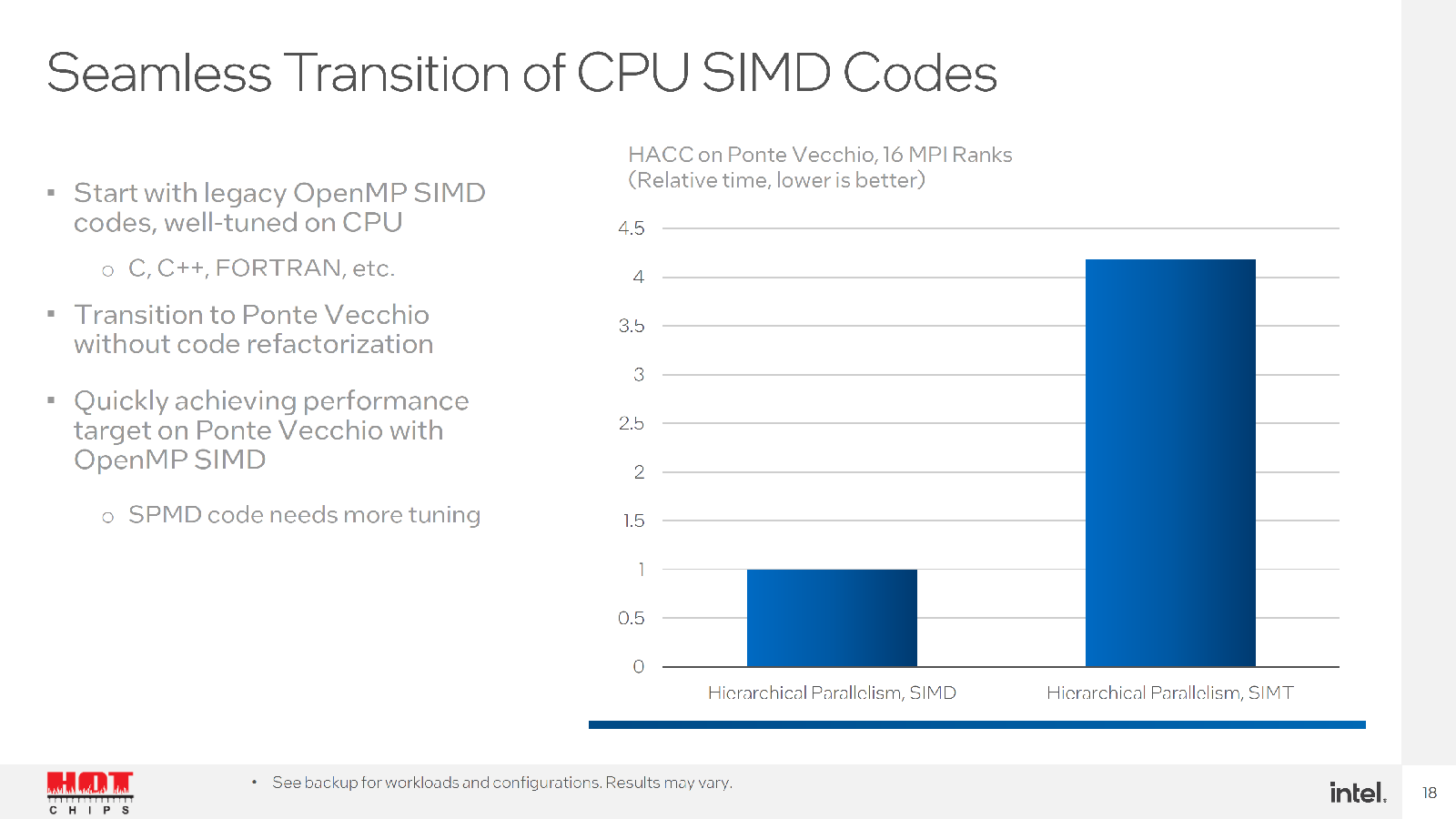
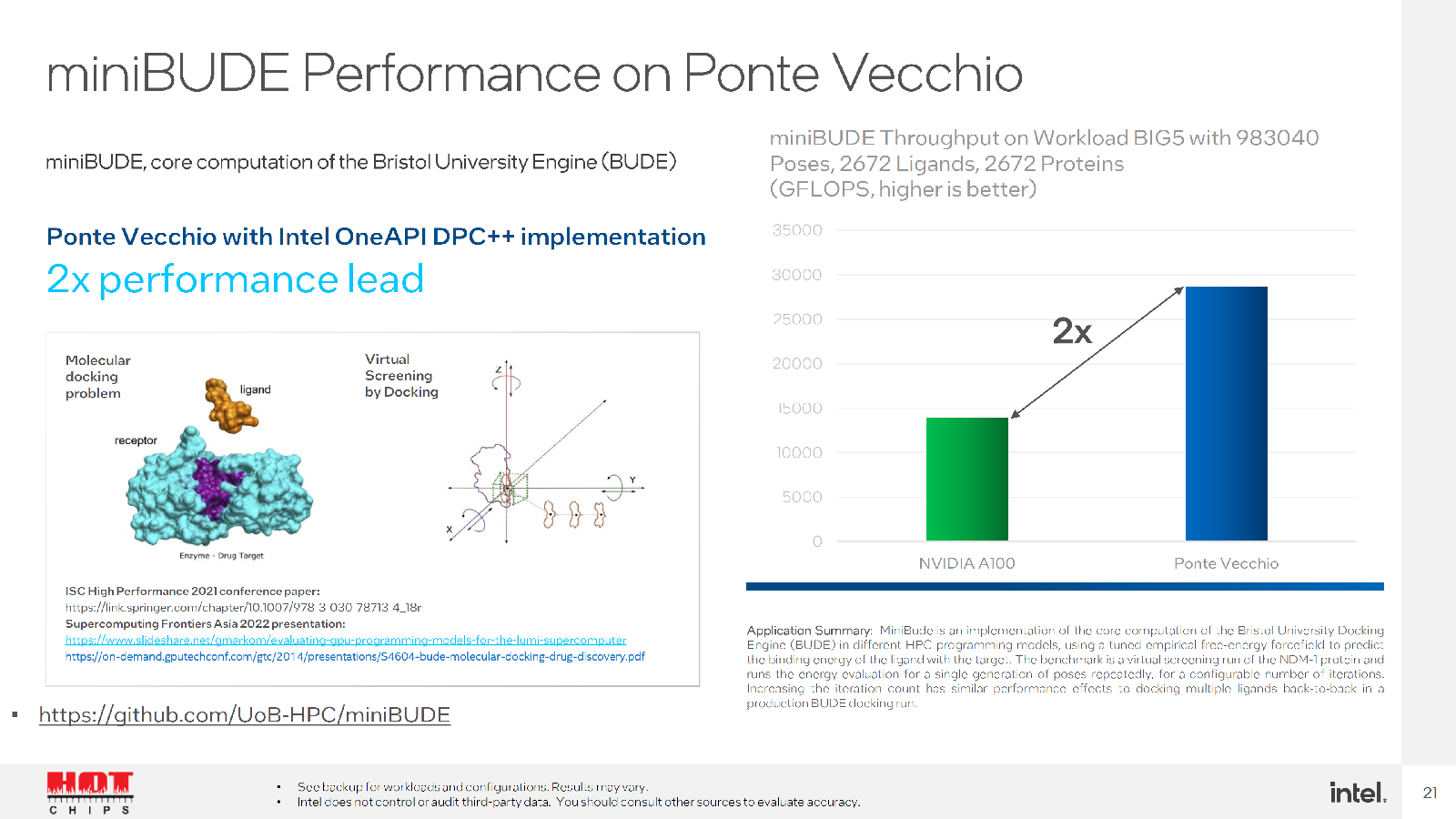
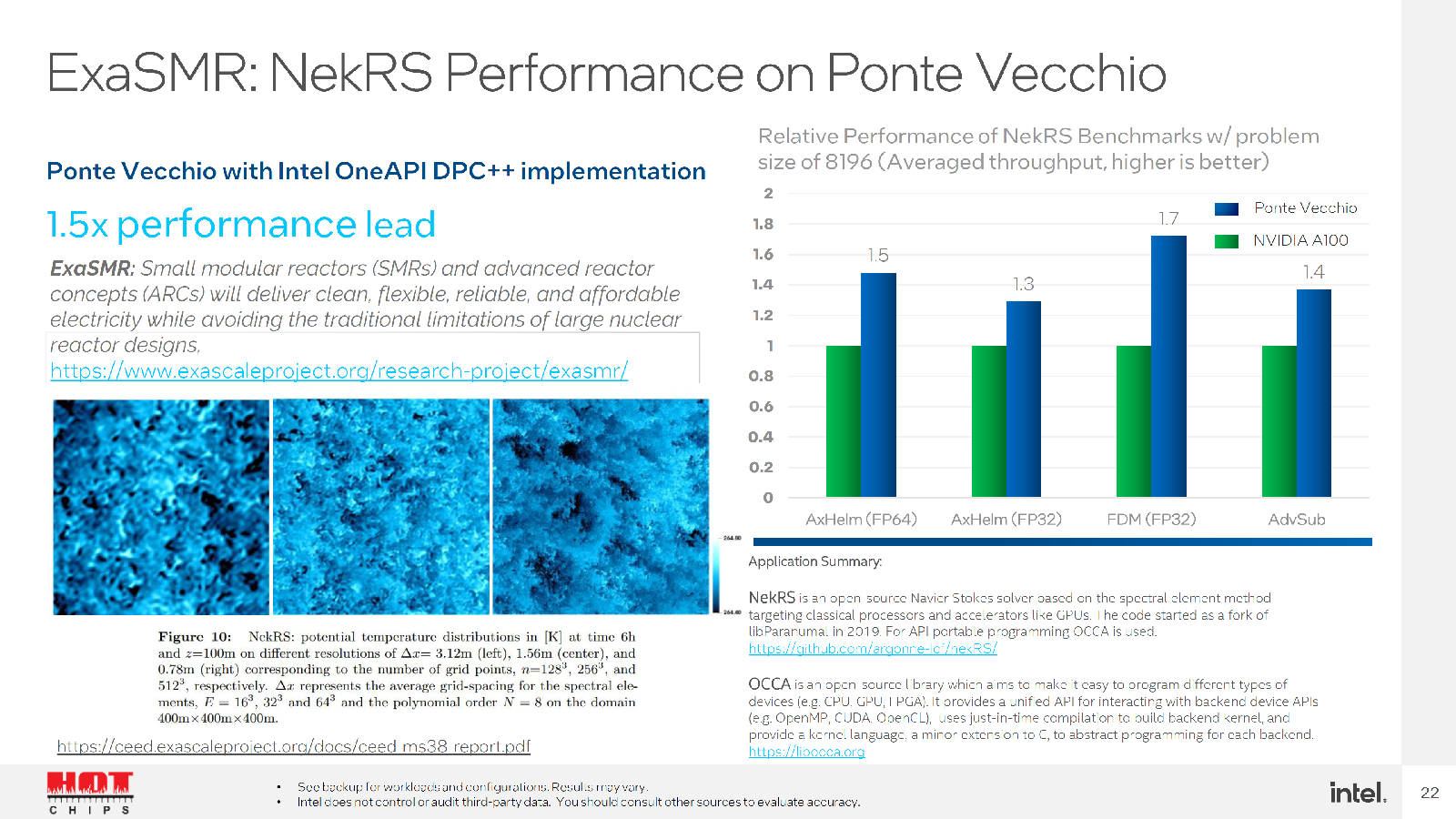
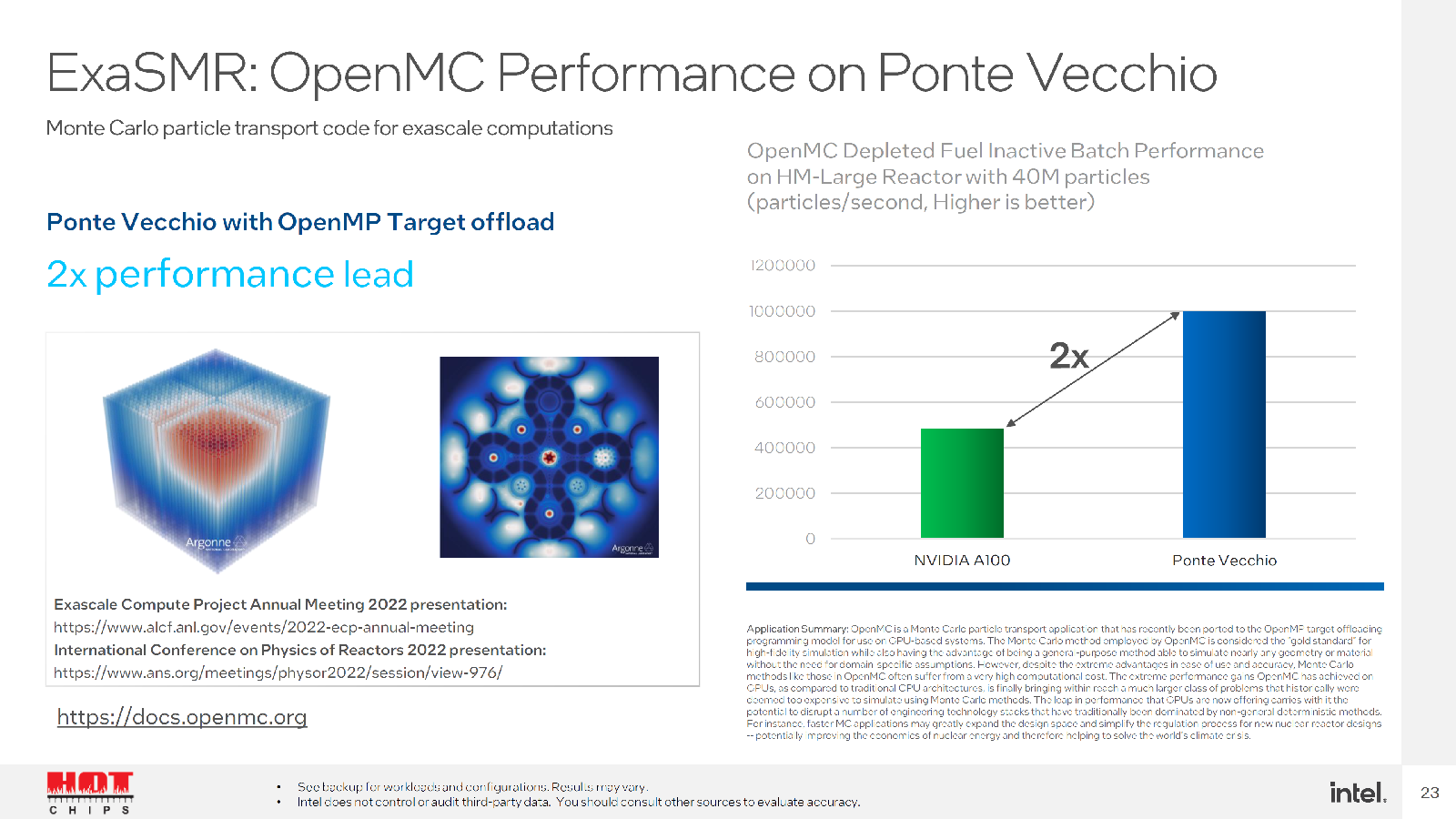

Но у Intel есть ещё один козырь. Во-первых, компания обещает, что часть старых кодов, оптимизированных ещё для CPU можно быстро перенести на её ускорители. Во-вторых, она предлагает инструмент для быстрого перевода CUDA-программ на SYCL. Любопытно, что после такого переноса часть ПО работает на ускорителях NVIDIA лучше прежнего, а на ускорителях Intel — до 2,5 раз. Правда, A100 уже более двух лет. И буквально за углом нас ждёт ускоритель H100, который даже на бумаге практически по всем пунктам опережает Ponte Vecchio.
Источники:

