Как известно, Китай первым в мире успешно ввёл в эксплуатацию суперкомпьютеры экзафлопсного класса, но современная HPC-система практически немыслима без ускорителей. Однако и здесь китайские разработчики подготовили прорыв: на конференции Hot Chips 34 компания Birentech рассказала о чипе BR100, решении, которое может бросить вызов как AMD, так и NVIDIA.
Новинка базируется на архитектуре собственной разработки под кодовым названием Bi Liren. Это первый китайский ускоритель общего назначения, использующий чиплетную компоновку и поддерживающий PCI Express 5.0/CXL. Новые ускорители будут сопровождаться полноценной программной поддержкой, начиная с драйверов и библиотек и заканчивая популярными фреймворками, такими, как TensorFlow и PyTorch.

Источник: WCCFTech
Сложность BR100 внушает уважение: новый чип состоит из 77 млрд транзисторов, скомпонованных воедино с использованием 7-нм техпроцесса и технологии TSMC 2.5D CoWoS. Площадь чипа составляет 1074 мм2, правда, не очень понятно, идёт ли речь исключительно о кристалле, т.н. «вычислительном тайле», или о сборке в целом, поскольку в состав BR100 входит 64 Гбайт памяти HBM2e.

Источник: WCCFTech
Среди особенностей можно отметить наличие быстрого кеша объёмом 300 Мбайт (256 Мбайт L2) — для сравнения, у NVIDIA A100 он составляет всего 40 Мбайт, и даже у новейшего H100 он увеличен лишь до 50 Мбайт. Что касается ПСП, то она составляет 1,64 Тбайт/с.
Источник: WCCFTech
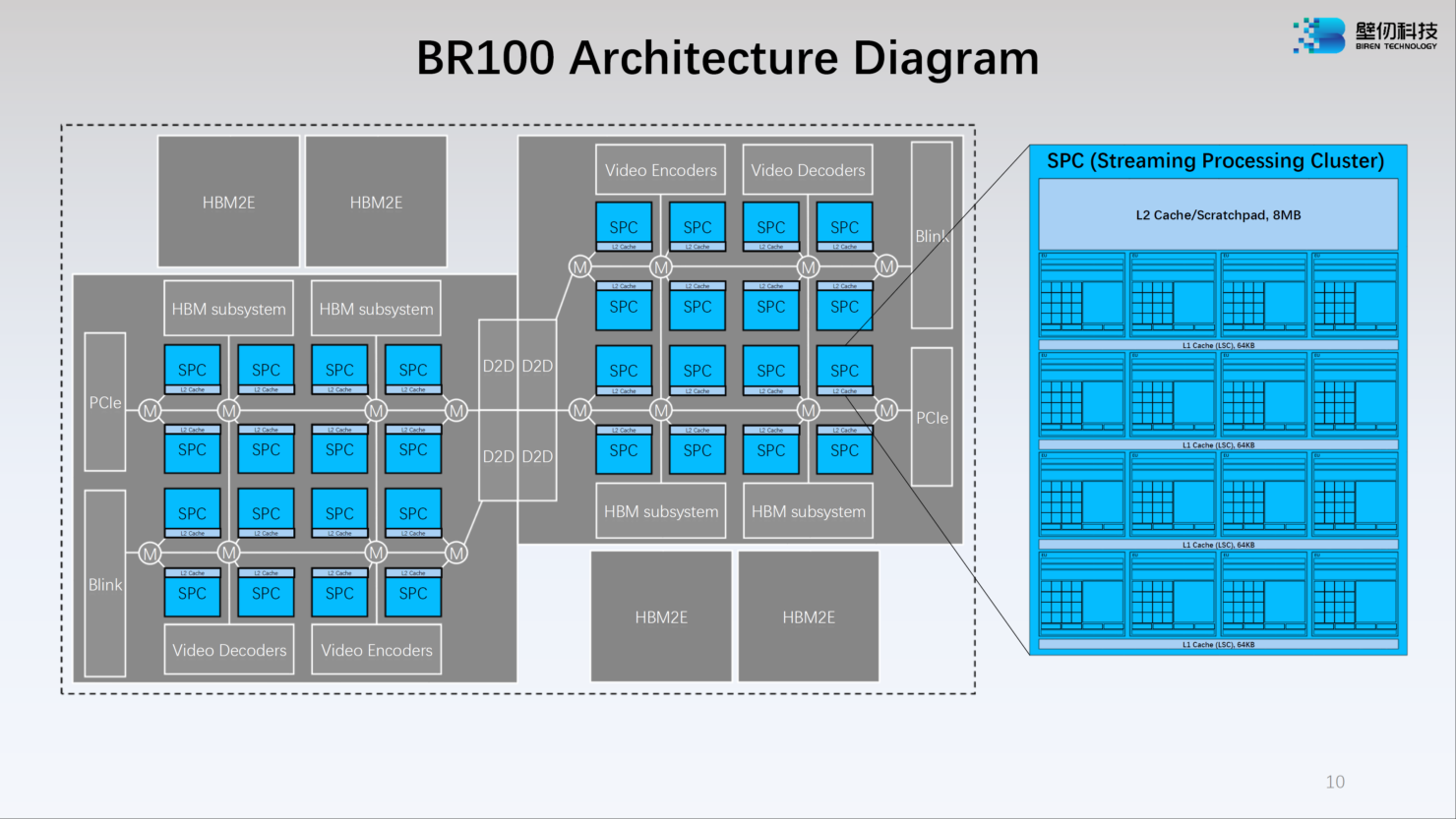
Модульная компоновка BR100 включает в себя два вычислительных тайла и четыре сборки HBM2e. Между собой кристаллы соединены интерконнектом с пропускной способностью 896 Гбайт/с, а для дальнейшего масштабирования в составе нового ускорителя предусмотрен фирменный интерконнект BLink (8 линий) с производительностью 2,3 Тбайт/с.

Источник: WCCFTech
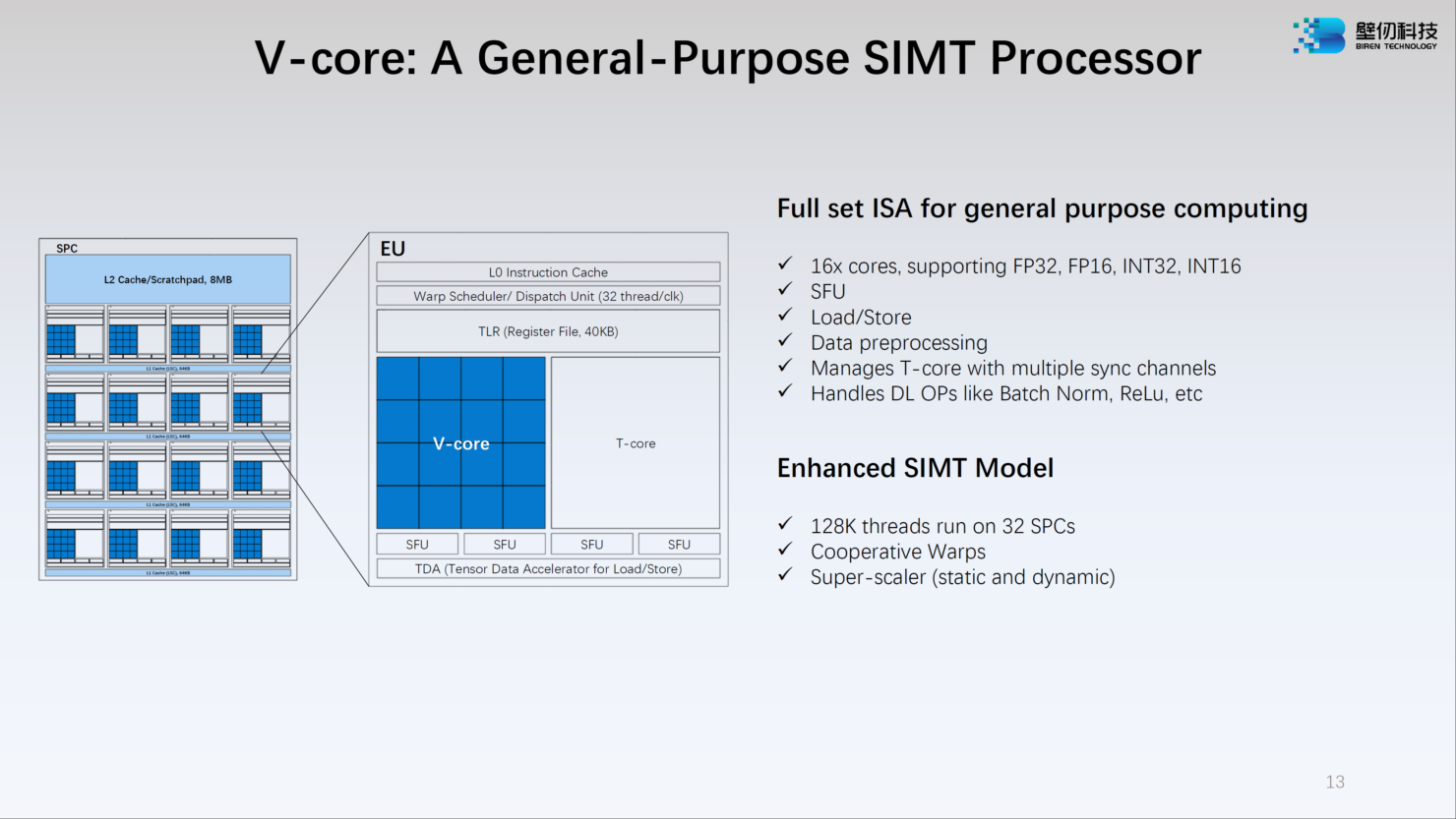
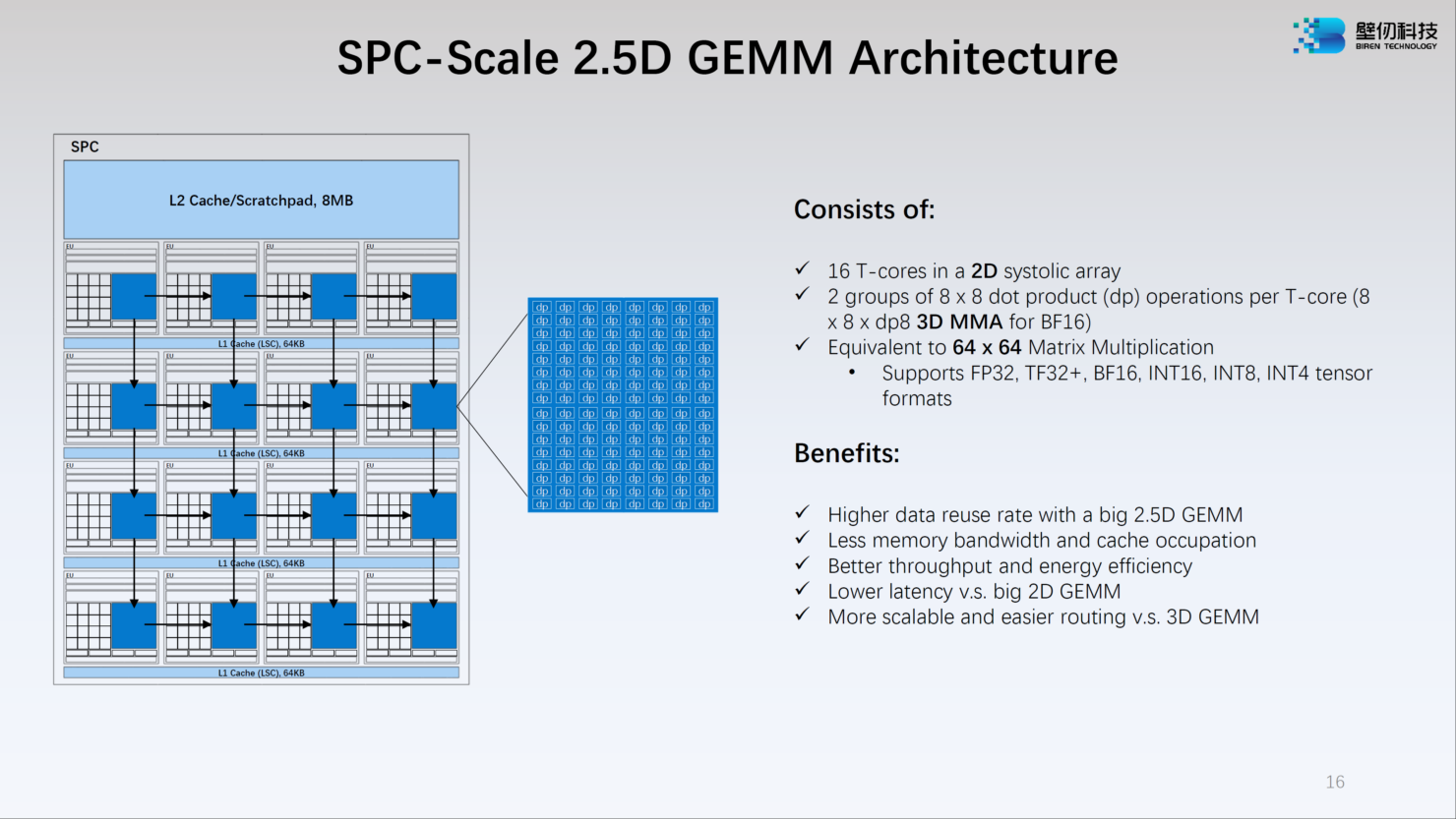
Каждый из двух кристаллов несёт в себе по 16 потоковых вычислительных кластеров (SPC), а каждый такой кластер, в свою очередь, содержит 16 исполнительных блоков (EU). Каждый блок EU содержит 16 потоковых ядер V-Core и одно тензорное ядро T-Core, так что всего в составе BR100 имеется 8192 классических ядра и 512 тензорных. Каждый SPC имеет свой кеш L2 объёмом 8 Мбайт, суммарно 256 Мбайт на всю сборку BR100.
Источник: WCCFTech
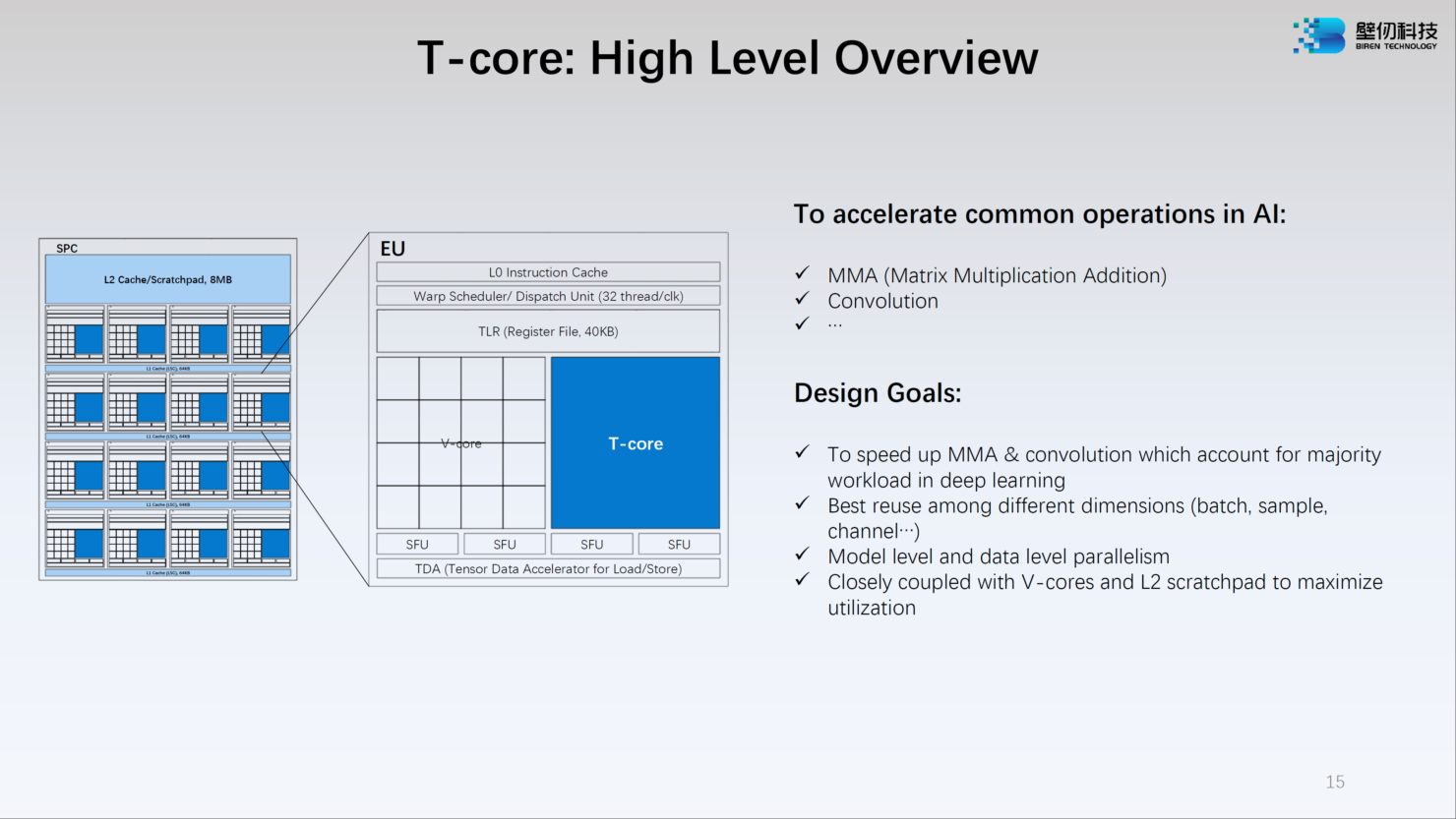
Ядро V-Core имеет архитектуру SIMT (Single Instructions, Multiple Thread) и поддерживает вычисления в форматах INT16/32, FP16 и FP32. Тензорные ядра T-Core предназначены для выполнения операций типа MMA, свёртки и прочих, характерных для современных задач машинного обучения. Предельное количество потоков у BR100 в суперскалярном режиме — 128 тысяч.
Источник: WCCFTech
Компания-разработчик приводит некоторые цифры производительности для BR100: это 256 Тфлопс в режиме FP32, вдвое больше в режиме TF32+, 1024 Тфлопс в формате BF16 и целых 2048 Топс в режиме INT8. Это серьёзная заявка: с такими показателями BR100 должен опережать NVIDIA A100. Заявлено превосходство от 2,5х до 2,8х в зависимости от задачи и сценария.
Источник: WCCFTech
Любопытно, что BR100 несильно уступает NVIDIA H100 по количеству транзисторов (77 против 80 млрд), но, естественно, использование более грубого 7-нм техпроцесса против N4 у последней разработки NVIDIA означает и большее тепловыделение. Этот параметр у BR100 составляет 550 Вт в то время, как PCIe-вариант H100 укладывается в стандартные 350 Вт.

Источник: WCCFTech
Это не единственная новинка: в арсенале Birentech заявлен и менее мощный чип BR104. Он вдвое медленнее старшей модели по всем показателям и несёт 32 Гбайт памяти против 64, но в отличие от BR100, использует монолитный, а не чиплетный дизайн. На его основе будут выпущены ускорители в формате PCIe с TDP в районе 300 Вт, тогда как старшая версия будет доступна только в виде OAM-модуля.
Источник:

