В последние годы сложность ИИ-моделей удваивается в среднем каждые два месяца, и пока что эта тенденция сохраняется. Всего три года назад Google обучила «скромную» модель BERT с 340 млн параметров за 9 Пфлоп-дней. В 2020 году на обучение модели Micrsofot MSFT-1T с 1 трлн параметров понадобилось уже порядка 25-30 тыс. Пфлоп-дней. Процессорам и GPU общего назначения всё труднее управиться с такими задачами, поэтому разработкой специализированных ускорителей занимается целый ряд компаний: Google, Groq, Graphcore, SambaNova, Enflame и др.

Особо выделятся компания Cerebras, избравшая особый путь масштабирования вычислительной мощности. Вместо того, чтобы печатать десятки чипов на большой пластине кремния, вырезать их из пластины, а затем соединять друг с другом — компания разработала в 2019 г. гигантский чип Wafer-Scale Engine 1 (WSE-1), занимающий практически всю пластину. 400 тыс. ядер, выполненных по 16-нм техпроцессу, потребляют 15 кВт, но в ряде задач они оказываются в сотни раз быстрее 450-кВт суперкомпьютера на базе ускорителей NVIDIA.

В этом году компания выпустила второе поколение этих чипов — WSE-2, в котором благодаря переходу на 7-нм техпроцесс удалось повысить число тензорных ядер до 850 тыс., а объём L2-кеша довести до 40 Гбайт, что примерно в 1000 раз больше чем у любого GPU. Естественно, такой подход к производству понижает выход годных пластин и резко повышает себестоимость изделий, но Cerebras в сотрудничестве с TSMC удалось частично снизить остроту этой проблемы за счёт заложенной в конструкцию WSE избыточности.
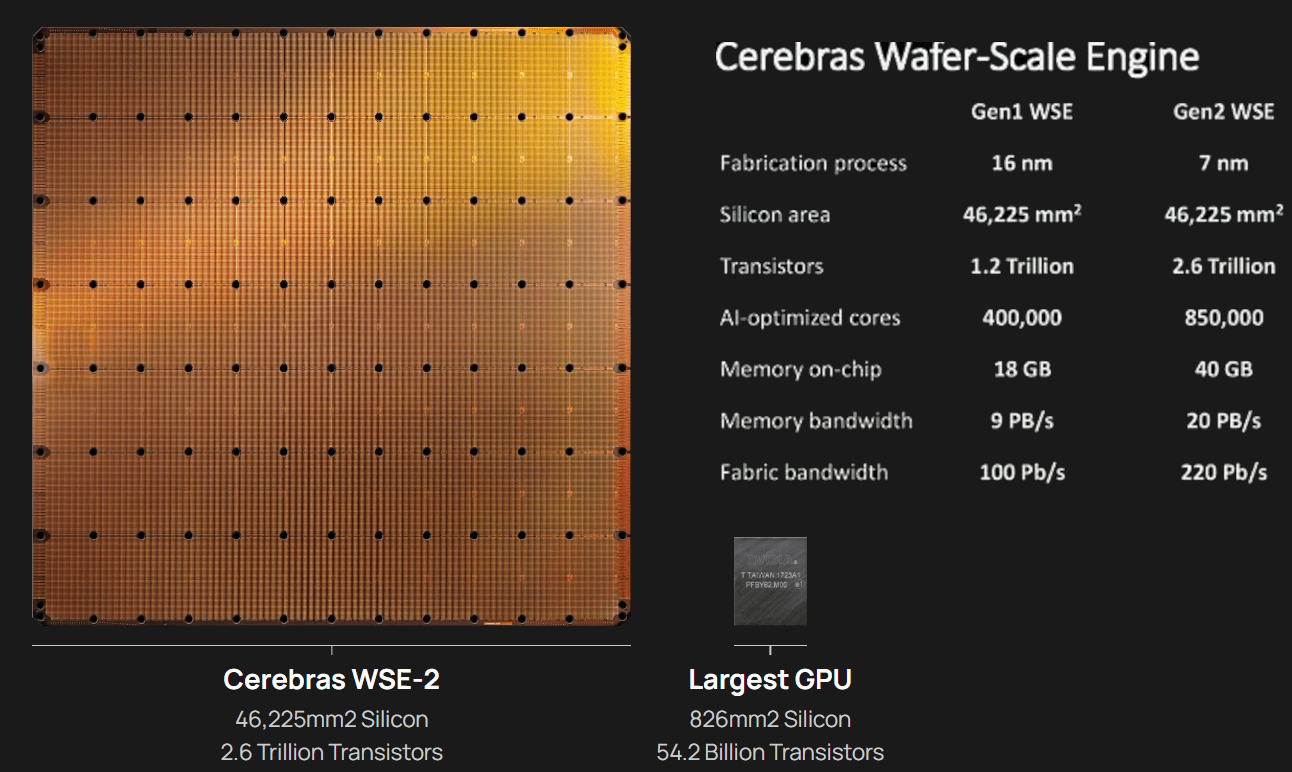
Благодаря идентичности всех ядер, даже при неисправности некоторых их них, изделие в целом сохраняет работоспособность. Тем не менее, себестоимость одной 7-нм 300-мм пластины составляет несколько тысяч долларов, в то время как стоимость чипа WSE оценивается в $2 млн. Зато система CS-1, построенная на таком процессоре, занимает всего треть стойки, имея при этом производительность минимум на порядок превышающую самые производительные GPU. Одна из причин такой разницы — это большой объём быстрой набортной памяти и скорость обмена данными между ядрами.

Тем не менее, теперь далеко не каждая модель способна «поместиться» в один чип WSE, поэтому, по словам генерального директора Cerebras Эндрю Фельдмана (Andrew Feldman), сейчас в фокусе внимания компании — построение эффективных систем, составленных из многих чипов WSE. Скорость роста сложности моделей превышает возможности увеличения вычислительной мощности путём добавления новых ядер и памяти на пластину, поскольку это приводит к чрезмерному удорожанию и так недешёвой системы.

Инженеры компании рассматривают дезагрегацию как единственный способ обеспечить необходимый уровень производительности и масштабируемости. Такой подход подразумевает разделение памяти и вычислительных блоков для того, чтобы иметь возможность масштабировать их независимо друг от друга — параметры модели помещаются в отдельное хранилище, а сама модель может быть разнесена на несколько вычислительных узлов CS, объединённых в кластер.
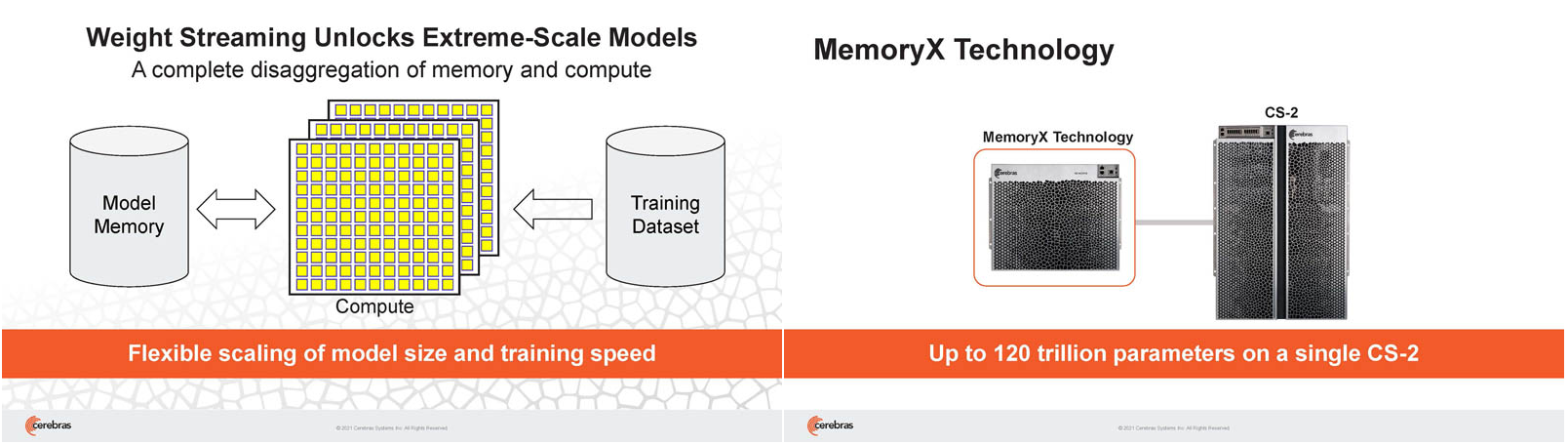
На Hot Chips 33 компания представила особое хранилище под названием MemoryX, сочетающее DRAM и флеш-память суммарной емкостью 2,4 Пбайт, которое позволяет хранить до 120 трлн параметров. Это, по оценкам компании, делает возможным построение моделей близких по масштабу к человеческому мозгу, обладающему порядка 80 млрд. нейронов и 100 трлн. связей между ними. К слову, флеш-память размером с целую 300-мм пластину разрабатывает ещё и Kioxia.

Для обеспечения масштабирования как на уровне WSE, так и уровне CS-кластера, Cerebras разработала технологию потоковой передачи весовых коэффициентов Weight Streaming. С помощью неё слой активации сверхкрупных моделей (которые скоро станут нормой) может храниться на WSE, а поток параметров поступает извне. Дезагрегация вычислений и хранения параметров устраняет проблемы задержки и узости пропускной способности памяти, с которыми сталкиваются большие кластеры процессоров.
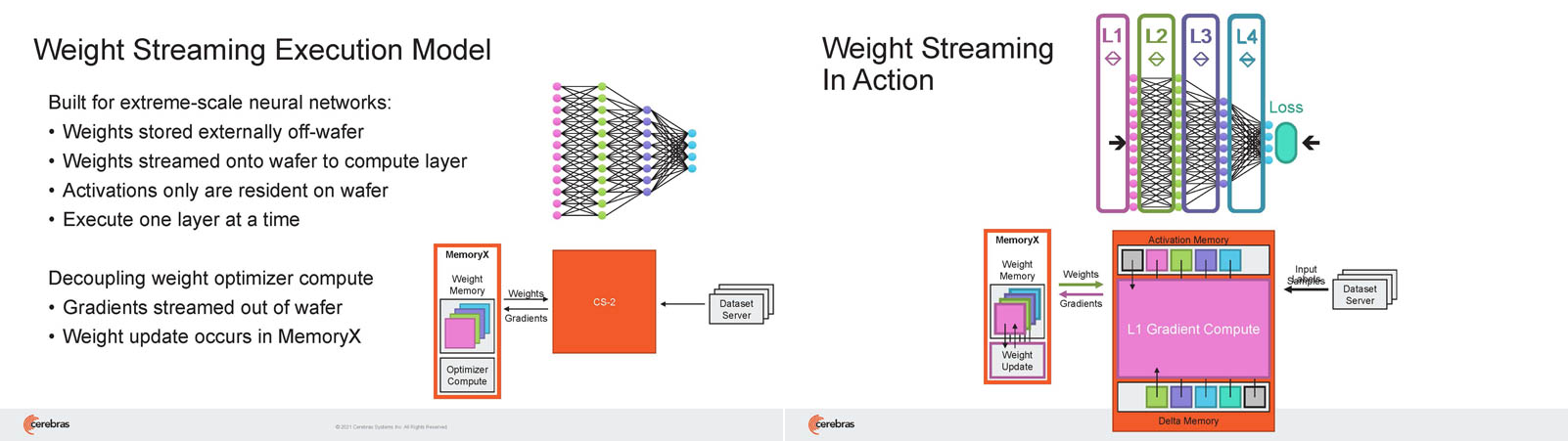
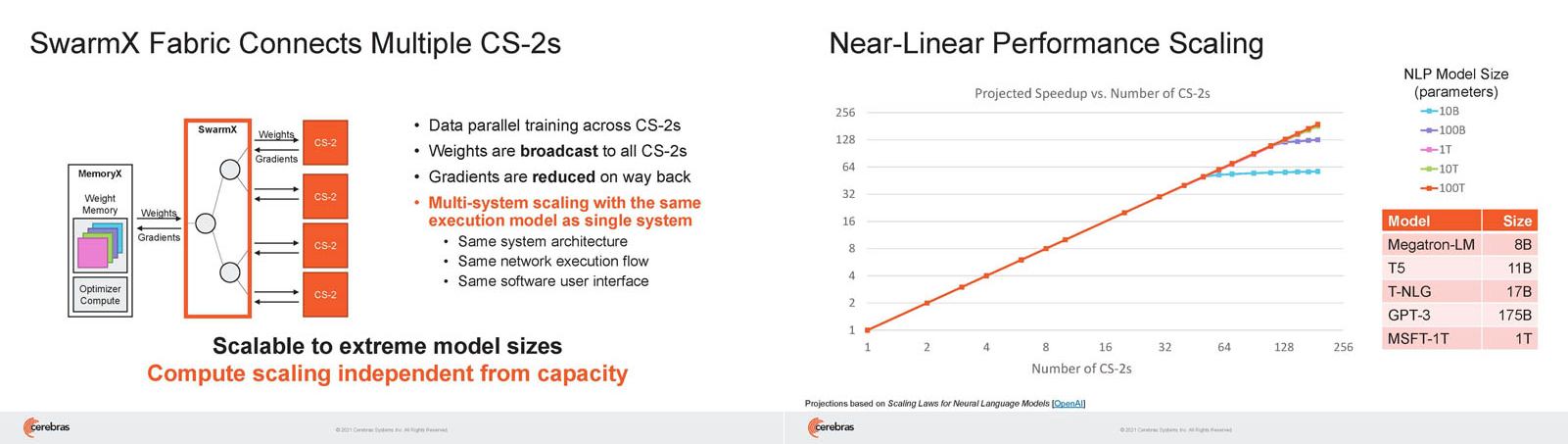
Это открывает широкие возможности независимого масштабирования размера и скорости кластера, позволяя хранить триллионы весов WSE-2 в MemoryX и использовать от 1 до 192 CS-2 без изменения ПО. В традиционных системах по мере добавления в кластер большего количества вычислительных узлов каждый из них вносит всё меньший вклад в решение задачи. Cerebras разработала интерконнект SwarmX, позволяющий подключать до 163 млн вычислительных ядер, сохраняя при этом линейность прироста производительности.
Также, компания уделила внимание разрежённости, то есть исключения части незначимых для конечного результата весов. Исследования показали, что должная оптимизации модели позволяет достичь 10-кратного увеличения производительности при сохранении точности вычислений. В CS-2 доступна технология динамического изменения разрежённости Selectable Sparsity, позволяющая пользователям выбирать необходимый уровень «ужатия» модели для сокращение времени вычислений.

«Крупные сети, такие как GPT-3, уже изменили отрасль машинной обработки естественного языка, сделав возможным то, что раньше было невозможно и представить. Индустрия перешла к моделям с 1 трлн параметров, а мы расширяем эту границу на два порядка, создавая нейронные сети со 120 трлн параметров, сравнимую по масштабу с мозгом» — отметил Фельдман.
Источник:

